Inhaltsverzeichnis
- 14.1. Die
MyISAM-Speicher-Engine - 14.2.
InnoDB-Tabellen - 14.2.1. Überblick über InnoDB-Tabellen
- 14.2.2. Kontaktinformationen
- 14.2.3. Konfiguration
- 14.2.4.
InnoDB: Startoptionen und Systemvariablen - 14.2.5. InnoDB-Tablespace erzeugen
- 14.2.6.
InnoDB-Tabellen erzeugen - 14.2.7. Hinzufügen und Entfernen von InnoDB-Daten- und -Logdateien
- 14.2.8. Sichern und Wiederherstellen einer
InnoDB-Datenbank - 14.2.9. Eine InnoDB-Datenbank auf eine andere Maschine verschieben
- 14.2.10. InnoDB-Transaktionsmodell
- 14.2.11. Tipps zur Leistungssteigerung
- 14.2.12. Implementierung der Multiversionierung
- 14.2.13. Tabellen- und Indexstrukturen
- 14.2.14. Verwaltung von Speicherplatz für Dateien und von Festplattenein- und -ausgaben
- 14.2.15.
InnoDB-Fehlerbehandlung - 14.2.16. Beschränkungen von
InnoDB-Tabellen - 14.2.17.
InnoDB-Troubleshooting
- 14.3. Die
MERGE-Speicher-Engine - 14.4. Die
MEMORY-Speicher-Engine - 14.5. Die
BDB-Speicher-Engine - 14.6. Die
EXAMPLE-Speicher-Engine - 14.7. Die
FEDERATED-Speicher-Engine - 14.8. Die
ARCHIVE-Speicher-Engine - 14.9. Die
CSV-Speicher-Engine - 14.10. Die
BLACKHOLE-Speicher-Engine
MySQL unterstützt mehrere Speicher-Engines für die Arbeit mit unterschiedlichen Tabellentypen. MySQL kennt Speicher-Engines sowohl für transaktionssichere als auch für nicht-transaktionssichere Tabellen:
Mit
MyISAMwerden nicht-transaktionssichere Tabellen verwaltet. Dieser Tabellentyp kann Daten sehr schnell speichern und abrufen und bietet Volltext-Suchfähigkeiten.MyISAMwird in allen MySQL-Konfigurationen unterstützt und ist als Standard-Tabellentyp voreingestellt, sofern Sie in MySQL keinen anderen Default konfiguriert haben.Die Speicher-Engine
MEMORYstellt Tabellen im Arbeitsspeicher zur Verfügung. Mit der Speicher-EgnineMERGElassen sich mehrere identischeMyISAM-Tabellen wie eine einzige behandeln. WieMyISAMverwalten auch die Speicher-EnginesMEMORYundMERGEnicht-transaktionssichere Tabellen. Beide sind ebenfalls standardmäßig in MySQL enthalten.Note: Die Speicher-Engine
MEMORYhieß früherHEAP.Die Speicher-Engines
InnoDBundBDBstellen transaktionssichere Tabellen zur Verfügung.BDBist in den Binärdistributionen von MySQL-Max für Betriebssysteme, die dieses unterstützen, enthalten. Außerdem istInnoDBStandardbestandteil aller MySQL 5.1-Binärdistributionen. In Quelldistributionen können Sie diese Engines aktivieren oder deaktivieren, indem Sie MySQL nach Ihren Wünschen konfigurieren.Die Speicher-Engine
EXAMPLEist ein „Sockel“-Modul, das eigentlich gar nichts tut. Sie können mit ihr zwar Tabellen anlegen, aber keine Daten speichern oder abrufen. Sie soll lediglich im MySQL-Quellcode als Beispiel zu dienen, um zu zeigen, wie man neue Speicher-Engines schreibt. Daher ist sie vor allem für Entwickler von Interesse.NDB Clusterwird von MySQL Cluster als Speicher-Engine zur Implementierung von Tabellen genutzt, die über viele Computer partitioniert sind. Sie steht in den MySQL-Max 5.1- Binärdistributionen zur Verfügung. Dieses Speicher-Engine wird zurzeit nur von Linux, Solaris und Mac OS X unterstützt. In zukünftigen MySQL-Releases soll sie auch auf anderen Plattformen, wie etwa Windows, unterstützt werden.Die Speicher-Engine
ARCHIVEdient der Speicherung großer Datenmengen ohne Indizes mit einem sehr kleinen Speicherverbrauch.Die Speicher-Engine
CSVspeichert Daten in Textdateien in Form von kommagetrennten Werten.Die Speicher-Engine
BLACKHOLEnimmt Daten entgegen, speichert sie jedoch nicht. Abfragen liefern immer eine leere Menge zurück.Die Speicher-Engine
FEDERATEDspeichert Daten in einer Remote-Datenbank. Gegenwärtig funktioniert sie nur mit MySQL unter Verwendung der MySQL-C-Client-API. In zukünftigen Releases soll sie auch mit anderen Datenquellen mit anderen Treibern oder Client-Verbindungsmethoden funktionieren.
In diesem Kapitel werden die Speicher-Engines von MySQL beschrieben.
Eine Ausnahme bildet die Engine NDB Cluster, die
in Kapitel 16, MySQL Cluster behandelt wird.
Wenn Sie eine neue Tabelle anlegen, können Sie die zu verwendende
Speicher-Engine angeben, indem Sie der CREATE
TABLE-Anweisung die Tabellenoption
ENGINE oder TYPE hinzufügen:
CREATE TABLE t (i INT) ENGINE = INNODB; CREATE TABLE t (i INT) TYPE = MEMORY;
Der ältere Begriff TYPE wird aus Gründen der
Abwärtskompatibilität noch als Synonym für
ENGINE akzeptiert, doch ENGINE
ist der aktuelle Begriff, während TYPE
mittlerweile veraltet ist.
Wenn Sie die Option ENGINE oder
TYPE weglassen, wird die Standard-Speicher-Engine
verwendet. Normalerweise ist dies MyISAM, doch
mit der Server-Startoption --default-storage-engine
oder --default-table-type oder der Systemvariablen
storage_engine oder table_type
können Sie auch etwas anderes einstellen.
Wird MySQL unter Windows mit dem MySQL Configuration Wizard
installiert, kann die Speicher-Engine InnoDB
anstelle der standardmäßigen MyISAM-Engine
gewählt werden. Siehe
Abschnitt 2.3.5.6, „Der Dialog zur Datenbankverwendung“.
Um eine Typkonvertierung von Tabellen vorzunehmen, geben Sie in
einer ALTER TABLE-Anweisung den neuen Typ an:
ALTER TABLE t ENGINE = MYISAM; ALTER TABLE t TYPE = BDB;
Siehe Abschnitt 13.1.5, „CREATE TABLE“ und
Abschnitt 13.1.2, „ALTER TABLE“.
Wenn Sie eine Speicher-Engine zu verwenden versuchen, die entweder
gar nicht kompiliert oder zwar kompiliert, aber deaktiviert ist,
legt MySQL stattdessen mit der Standard-Speicher-Engine eine Tabelle
an, also normalerweise mit MyISAM. Dieses
Verhalten ist praktisch, wenn Tabellen zwischen MySQL-Servern hin-
und herkopiert werden, die verschiedene Speicher-Engines
unterstützen. (So könnte beispielsweise in einer Replikation Ihr
Masterserver aus Sicherheitsgründen transaktionssichere
Speicher-Engines verwenden, während die Slaveserver aus Gründen
der Schnelligkeit nur nicht-transaktionssichere einsetzen.)
Dass MySQL für Speicher-Engines, die nicht zur Verfügung stehen, automatisch die Standard-Speicher-Engine einsetzt, kann für Neulinge verwirrend sein. Es wird jedoch in einem solchen Fall immer eine Warnung ausgegeben.
Für neue Tabellen legt MySQL immer eine
.frm-Datei zur Speicherung der Tabellen- und
Spaltendefinitionen an. Der Index und die Daten der Tabelle können
je nach Speicher-Engine in einer oder mehreren Dateien gespeichert
sein. Der Server erstellt die .frm-Datei über
der Ebene der Speicher-Engine. Einzelne Speicher-Engines legen
zusätzliche Dateien an, die für die von ihnen verwalteten Tabellen
erforderlich sind.
Eine Datenbank kann unterschiedliche Tabellentypen enthalten; die Tabellen müssen also nicht alle mit derselben Speicher-Engine angelegt werden.
Transaktionssichere Tabellen (TSTs) haben gegenüber den nicht-transaktionssicheren (NTSTs) mehrere Vorteile:
Sie sind sicherer. Selbst wenn MySQL abstürzt oder Hardware-Probleme auftreten, bekommen Sie Ihre Daten auf jeden Fall zurück, sei es durch die automatische Wiederherstellung, sei es aus einer Sicherungskopie plus dem Transaktionslog.
Sie können viele Anweisungen miteinander kombinieren und mit der
COMMIT-Anweisung später alle gleichzeitig festschreiben (wenn Autocommit deaktiviert wurde).Sie können Ihre Änderungen mit einem
ROLLBACKverwerfen (wenn Autocommit deaktiviert wurde).Schlägt ein Update fehl, werden alle Ihre Änderungen rückgängig gemacht. (Bei nicht-transaktionssicheren Tabellen sind alle einmal stattgefundenen Änderungen von Dauer.)
Transaktionssichere Speicher-Engines bieten bessere Nebenläufigkeit für Tabellen, in denen gleichzeitig mit Lese-Operationen viele Änderungen stattfinden.
Sie können transaktionssichere und nicht-transaktionssichere
Tabellen in derselben Anweisung verwenden, um aus beiden das Beste
herauszuholen. Allerdings sollten Sie nicht bei ausgeschaltetem
Autocommit verschiedene Speicher-Engines durcheinanderwürfeln, auch
wenn MySQL mehrere transaktionssichere Engines unterstützt, um die
bestmöglichen Ergebnisse zu erzielen. Denn wenn Sie die Engines
vermischen, werden Änderungen an nicht-transaktionssicheren
Tabellen weiterhin festgeschrieben und können nicht mehr
zurückgerollt werden. Informationen zu diesem und anderen
Problemen, die in Transaktionen mit einem Mix von Speicher-Engines
auftreten können, finden Sie unter Abschnitt 13.4.1, „BEGIN/COMMIT/ROLLBACK“.
Nicht-transaktionssichere Tabellen haben mehrere Vorteile, die alle damit zusammenhängen, dass der Aufwand von Transaktionen entfällt:
Viel schneller
Weniger Speicherbedarf auf der Festplatte
Weniger Arbeitsspeicherbedarf für Updates
MyISAM ist die Standard-Speicher-Engine. Sie
baut auf dem älteren ISAM-Code auf, hat aber
viele praktische Erweiterungen. (Beachten Sie, dass MySQL
5.1 ISAMnicht
mehr unterstützt.)
Jede MyISAM-Tabelle wird in drei Dateien auf
der Festplatte gespeichert. Die Namen der Dateien beginnen mit dem
Tabellennamen und haben eine Erweiterung, die den Dateityp angibt.
Eine .frm-Datei speichert das Tabellenformat.
Die Datendatei besitzt die Erweiterung .MYD
(MYData). Die Indexdatei hat die Erweiterung
.MYI (MYIndex).
Um ausdrücklich zu sagen, dass Sie eine
MyISAM-Tabelle möchten, verwenden Sie die
Tabellenoption ENGINE:
CREATE TABLE t (i INT) ENGINE = MYISAM;
Der ältere Begriff TYPE wird aus Gründen der
Abwärtskompatibilität noch als Synonym für
ENGINE akzeptiert, doch
ENGINE ist der aktuelle Begriff, während
TYPE mittlerweile veraltet ist.
Normalerweise ist eine ENGINE-Angabe für die
MyISAM-Speicher-Engine unnötig.
MyISAM ist ohnehin die Standard-Engine, es sei
denn, die Standardeinstellung wurden geändert. Um in solchen
Situationen ganz sicherzugehen, dass MyISAM
verwendet wird, sollten Sie explizit die Option
ENGINE verwenden.
Zur Prüfung oder Reparatur von MyISAM-Tabellen
setzen Sie den mysqlcheck-Client oder das
Hilfsprogramm myisamchk ein. Überdies können
Sie MyISAM-Tabellen mit
myisampack komprimieren, dann belegen sie viel
weniger Speicherplatz. Siehe auch Abschnitt 8.9, „mysqlcheck — Hilfsprogramm für die Wartung und Reparatur von Tabellen“,
Abschnitt 5.10.4.1, „Benutzung von myisamchk für die Fehlerbeseitigung nach Abstürzen“, und
Abschnitt 8.4, „myisampack — Erzeugung komprimierter, schreibgeschützter MyISAM Tabellen“.
Kennzeichen von MyISAM-Tabellen:
Alle Daten werden mit dem niederwertigen Byte zuerst gespeichert. Dadurch werden die Daten maschinen- und betriebssystemunabhängig. Die einzigen Voraussetzungen für die binäre Portierbarkeit der Daten sind, dass der Computer vorzeichenbehaftete Integers (Zweierkomplement) und das IEEE-Fließkommaformat verwendet. Diese Voraussetzungen werden von den üblichen Computern meist erfüllt. Nur bei Embedded-Systemen mit ihren manchmal seltsamen Prozessoren ist die Binärkompatibilität nicht immer gegeben.
Die Verarbeitungsgeschwindigkeit leidet nicht sonderlich, wenn das niederwertige Byte zuerst gespeichert wird. Die Bytes in einer Tabellenzeile werden normalerweise nicht ausgerichtet und es macht zeitmäßig kaum einen Unterschied, ob ein unausgerichtetes Byte in der Reihenfolge oder gegen die Reihenfolge gelesen wird. Darüber hinaus ist der Server-Code, der die Spaltenwerte abruft, im Vergleich zu anderem Code nicht zeitkritisch.
Alle numerischen Schlüsselwerte werden mit dem höchstwertigen Byte zuerst gespeichert, um eine bessere Indexkompression zu ermöglichen.
Große Dateien (bis zu 63 Bit Dateilänge) werden für Datei- und Betriebssysteme, auf denen große Dateien möglich sind, unterstützt.
Eine
MyISAM-Tabelle kann maximal 64 Indizes haben. Dies lässt sich jedoch durch Rekompilieren ändern: Ab der Version MySQL 5.1.4 können Sie den Build konfigurieren, indem Sie configure mit der Option--with-max-indexes=aufrufen, wobeiNNdie Höchstzahl der proMyISAM-Tabelle zulässigen Indizes ist.Nmuss kleiner oder gleich 128 sein. In älteren Versionen als MySQL 5.1.4 müssen Sie die Quelle wechseln.Ein Index darf maximal 16 Spalten haben.
Die Höchstlänge für Schlüssel beträgt 1000 Bytes. Auch dies lässt sich durch Wechseln der Quelle und Rekompilieren ändern. Ist ein Schlüssel länger als 250 Bytes wird ein größerer als der standardmäßig 1024 Bytes große Schlüsselblock verwendet.
Werden Zeilen sortiert eingefügt (wie zum Beispiel mit einer
AUTO_INCREMENT-Spalte), wird der Indexbaum aufgespalten, so dass der höchste Knoten nur einen Schlüssel enthält. So wird der Platz im Indexbaum besser ausgenutzt.Intern wird eine
AUTO_INCREMENT-Spalte pro Tabelle unterstützt.MyISAMaktualisiert diese Spalte beiINSERT- undUPDATE-Operationen automatisch. Das machtAUTO_INCREMENT-Spalten schneller (um mindestens 10%). Werte am Anfang der Folge werden nach ihrer Löschung nicht wiederverwendet. (Wenn eineAUTO_INCREMENT-Spalte als die letzte Spalte eines Mehrspalten-Indizes definiert ist, werden gelöschte Werte vom Anfang einer Folge doch wiederverwendet.) DerAUTO_INCREMENT-Wert kann mitALTER TABLEoder myisamchk zurückgesetzt werden.Zeilen mit dynamischer Größenanpassung werden bei einer Mischung von Lösch-, Änderungs- und Einfügeoperationen viel weniger stark fragmentiert, da aneinander grenzende gelöschte Blöcke automatisch zusammengefasst und Blöcke, deren Nachbarblock gelöscht werden, automatisch erweitert werden.
Hat eine Tabelle in der Mitte der Datendatei keine freien Blöcke, können Sie neue Zeilen mit
INSERTeinfügen, während gleichzeitig andere Threads die Tabelle lesen. (Man nennt dies "nebenläufige Einfügeoperationen".) Wird eine Zeile gelöscht oder werden in eine Zeile dynamischer Länge mehr Daten geschrieben, als sie zuvor enthalten hatte, kann ein freier Block entstehen. Wenn alle freien Blöcke aufgebraucht (ausgefüllt) wurden, werden zukünftige Einfügeoperationen wieder nebenläufig. Siehe Abschnitt 7.3.3, „Gleichzeitige Einfügevorgänge“.Mit den Tabellenoptionen
DATA DIRECTORYundINDEX DIRECTORYvonCREATE TABLEkönnen Sie die Daten- und die Indexdatei in unterschiedliche Verzeichnisse legen, um mehr Geschwindigkeit zu erzielen. Siehe Abschnitt 13.1.5, „CREATE TABLE“.BLOB- undTEXT-Spalten können indiziert werden.NULL-Werte sind in indizierten Spalten zulässig. Hierfür werden 0 bis 1 Byte pro Schlüssel gebraucht.Jede Zeichenspalte kann einen anderen Zeichensatz haben. Siehe Kapitel 10, Zeichensatz-Unterstützung.
In der
MyISAM-Indexdatei gibt es ein Flag, das anzeigt, ob die Tabelle ordentlich geschlossen wurde. Wenn mysqld mit der Option--myisam-recovergestartet wird, werdenMyISAM-Tabellen beim Öffnen automatisch überprüft und repariert, wenn sie nicht richtig geschlossen wurden.myisamchk markiert Tabellen als geprüft, wenn Sie es mit der Option
--update-stateausführen. myisamchk --fast prüft nur diejenigen Tabellen, die diese Markierung nicht tragen.myisamchk --analyze speichert Statistikdaten sowohl für Teilschlüssel als auch für vollständige Schlüssel.
myisampack kann
BLOB- undVARCHAR-Spalten packen.
MyISAM unterstützt auch folgende Funktionen:
Unterstützung für einen echten
VARCHAR-Typ; eineVARCHAR-Spalte beginnt mit einer Längenangabe, die in einem oder zwei Byte(s) gespeichert ist.Tabellen mit
VARCHAR-Spalten können Zeilen mit fester oder dynamischer Länge haben.Die Summe der Längen der
VARCHAR-undCHAR-Spalten in einer Tabelle kann bis zu 64KB betragen.Für
UNIQUEkann ein berechneter Hash-Index verwendet werden. So istUNIQUEfür jede beliebige Spaltenkombination in einer Tabelle zulässig. (Allerdings können auf einem berechnetenUNIQUE-Index keine Suchoperationen durchgeführt werden.)
Ein spezielles Forum für die Speicher-Engine
MyISAMfinden Sie unter http://forums.mysql.com/list.php?21.
Die folgenden Optionen von mysqld können
verwendet werden, um das Verhalten von
MyISAM-Tabellen zu ändern. Weitere
Informationen finden Sie unter Abschnitt 5.2.1, „Befehlsoptionen für mysqld“.
--myisam-recover=modeStellt den Modus für die automatische Wiederherstellung von abgestürzten
MyISAM-Tabellen ein.--delay-key-write=ALLZwischen den Schreibvorgängen werden die Schlüsselpuffer (Key-Buffer) für
MyISAM-Tabellen nicht auf die Festplatte zurückgeschrieben.Note: Wenn Sie dies tun, sollten Sie auf
MyISAM-Tabellen nicht von einem anderen Programm aus zugreifen (zum Beispiel von einem anderen MySQL-Server oder mit myisamchk), so lange die Tabellen in Gebrauch sind. Sonst riskieren Sie, dass der Index beschädigt wird. Diese Gefahr wird durch--external-lockingnicht gebannt.
Die folgenden Systemvariablen beeinflussen das Verhalten von
MyISAM-Tabellen. Weitere Informationen finden
Sie unter Abschnitt 5.2.2, „Server-Systemvariablen“.
bulk_insert_buffer_sizeDie Größe des bei der Optimierung von Massen-Einfügeoperationen verwendeten Tree-Caches. Hinweis: Dieser Wert gilt pro Thread!
myisam_max_sort_file_sizeZur Indexerstellung nicht die schnelle Index-Sortiermethode verwenden, wenn die temporäre Datei dadurch größer als dieser Wert würde. Hinweis: Dieser Parameter wird in Bytes angegeben.
myisam_sort_buffer_sizeStellt die Puffergröße für die Wiederherstellung von Tabellen ein.
Wenn Sie mysqld mit der Option
--myisam-recover starten, wird die automatische
Wiederherstellung aktiviert. Wenn der Server eine
MyISAM-Tabelle öffnet, prüft er, ob sie als
abgestürzt gekennzeichnet ist oder die Zählervariable für
Öffnungen von 0 verschieden ist und Sie den Server ohne externe
Sperren betreiben. Trifft eine dieser Bedingungen zu, so
geschieht folgendes:
Der Server überprüft die Tabelle auf Fehler.
Wenn der Server einen Fehler findet, versucht er eine schnelle Tabellenreparatur (mit Sortierung, aber ohne Neuerzeugung der Datendatei).
Scheitert die Reparatur wegen eines Fehlers in der Datendatei (zum Beispiel eines doppelten Schlüssels), versucht der Server erneut eine Reparatur, aber dieses Mal mit Neuerzeugung der Datendatei.
Scheitert auch diese Reparatur, versucht es der Server noch einmal mit der alten Reparaturmethode (zeilenweises Schreiben der Daten ohne Sortierung). Dieses Verfahren müsste in der Lage sein, jeden Fehler zu beheben und braucht nur wenig Festplattenspeicher.
Wenn die Wiederherstellung nicht alle Zeilen aus den zuvor
abgeschlossenen Anweisungen wiederherstellen kann und Sie im
Wert der Option --myisam-recover nicht
FORCE angegeben haben, bricht die
automatische Reparatur ab und schreibt folgende Fehlermeldung in
das Fehler-Log:
Error: Couldn't repair table: test.g00pages
Wenn Sie FORCE angeben, wird stattdessen
folgende Warnung in das Log geschrieben:
Warning: Found 344 of 354 rows when repairing ./test/g00pages
Beachten Sie: Wenn die automatische Wiederherstellung den Wert
BACKUP enthält, legt der
Wiederherstellungsprozess Dateien an, deren Namen die Form
tbl_name-datetime.BAK
MyISAM-Tabellen verwenden B-Baum-Indizes. Die
Größe der Indexdatei, summiert über alle Schlüssel, lässt
sich mit der Formel (key_length+4)/0.67
ungefähr berechnen. Das gilt für den ungünstigsten Fall, dass
alle Schlüssel in sortierter Reihenfolge eingefügt wurden und
die Tabelle keine komprimierten Schlüssel besitzt.
String-Indizes werden Leerzeichen-komprimiert. Ist der erste
Teil des Index ein String, so wird dieser zusätzlich
präfixkomprimiert. Durch Leerzeichen-Kompression wird die
Indexdatei kleiner als in den obigen Zahlen für den
ungünstigsten Fall dargestellt, wenn eine Stringspalte viele
Leerzeichen am Ende hat oder eine
VARCHAR-Spalte ist, die nicht immer in voller
Länge ausgenutzt wird. Eine Präfix-Kompression wird für
Schlüssel eingesetzt, die mit einem String anfangen. Die
Präfix-Kompression ist hilfreich, wenn mehrere Strings mit
identischem Präfix vorhanden sind.
In MyISAM-Tabellen können Sie auch Zahlen
präfixkomprimieren. Hierzu geben Sie beim Anlegen der Tabelle
die Tabellenoption PACK_KEYS=1 an. Das hilft,
wenn Sie viele Integer-Schlüssel mit identischem Präfix haben,
wenn die Zahlen mit dem höchstwertigen Byte zuerst gespeichert
werden.
MyISAM unterstützt drei verschiedene
Speicherformate. Zwei davon, das feste und das dynamische
Format, werden automatisch anhand des verwendeten Spaltentyps
gewählt. Das dritte, komprimierte Format kann nur mit der
Utility myisampack angelegt werden.
Wenn Sie CREATE TABLE oder ALTER
TABLE für eine Tabelle verwenden, die keine
BLOB- oder TEXT-Spalten
besitzt, können Sie mit der Tabellenoption
ROW_FORMAT ein FIXED- oder
DYNAMIC-Format erzwingen.
Um Tabellen zu dekomprimieren, geben Sie
ROW_FORMAT=DEFAULT mit ALTER
TABLE zusammen an.
Unter Abschnitt 13.1.5, „CREATE TABLE“ finden Sie Informationen
über ROW_FORMAT.
Das statische (Festlängen-) Format ist für
MyISAM-Tabellen voreingestellt. Es wird
verwendet, wenn die Tabelle keine Spalten mit variabler Länge
(VARCHAR-, VARBINARY-,
BLOB- oder TEXT-Spalten)
enthält. Jede Zeile wird dann mit einer festgelegten Anzahl
von Bytes gespeichert.
Von den drei Speicherformaten, die MyISAM
unterstützt, ist das statische Format das einfachste und
sicherste (für Schäden am wenigsten anfällige). Außerdem
bietet es wegen der Leichtigkeit, mit der die Zeilen der
Datendatei auf der Festplatte gefunden werden, auch den
schnellsten Festplattenzugriff. Um eine Zeile nach der
Index-Zeilennummer nachzuschlagen, multiplizieren Sie die
Nummer der Zeile mit ihrer Länge, um ihre Position zu
ermitteln. Darüber hinaus ist es beim Durchsuchen einer
Tabelle sehr einfach, mit jedem Festplattenzugriff eine
konstante Anzahl Zeilen zu lesen.
Die Sicherheit erweist sich, wenn Ihr Computer abstürzt,
während der MySQL-Server eine MyISAM-Datei
mit festgelegtem Format schreibt. In einem solchen Fall kann
myisamchk ganz leicht feststellen, wo die
Zeilen beginnen und enden. Normalerweise ist es dadurch in der
Lage, alle Zeilen außer der einen, die nur teilweise
geschrieben wurde, zurückzugewinnen. Beachten Sie, dass
MyISAM-Tabellenindizes immer anhand der
Datenzeilen rekonstruiert werden können.
Kennzeichen von statischen Tabellen:
CHAR-Spalten werden mit Leerzeichen bis zur Spaltenbreite aufgefüllt.BINARY-Spalten werden mit0x00-Bytes bis zur Spaltenbreite aufgefüllt.Sie sind sehr schnell.
Sie lassen sich leicht zwischenspeichern.
Sie sind nach einem Absturz einfach zu rekonstruieren, da sich die Datensätze an festen Positionen befinden.
Eine Reorganisation der Tabellen ist nicht erforderlich, es sei denn, Sie löschen sehr viele Zeilen und möchten dem Betriebssystem den frei gewordenen Speicherplatz zurückgeben. Hierzu verwenden Sie
OPTIMIZE TABLEoder myisamchk -r.Sie belegen normalerweise mehr Speicher als dynamische Tabellen.
Ein dynamisches Speicherformat wird verwendet, wenn eine
MyISAM-Tabelle Spalten variabler Länge
enthält (VARCHAR-,
VARBINARY-, BLOB- oder
TEXT-Spalten), oder wenn die Tabelle mit
der Tabellenoption ROW_FORMAT=DYNAMIC
angelegt wurde.
Das dynamische Format ist ein wenig komplizierter als das statische, da jede Zeile einen Header mit einer Längenangabe besitzt. Eine Zeile kann fragmentiert (an nicht-benachbarten Orten gespeichert) werden, wenn sie aufgrund eines Updates länger wird.
Mit OPTIMIZE TABLE oder myisamchk
-r lassen sich Tabellen defragmentieren. Wenn in
einer Tabelle, die auch Spalten variabler Länge besitzt,
Spalten mit festgelegter Länge vorliegen, die oft
angesprochen oder geändert werden, so empfiehlt es sich, die
Spalten mit variabler Länge in andere Tabellen auszulagern,
um Fragmentierung zu verhindern.
Kennzeichen von dynamischen Tabellen:
Alle String-Spalten sind dynamisch, außer jenen, deren Länge weniger als vier beträgt.
Vor jeder Zeile steht eine Bitmap, die für String-Spalten angibt, welche Spalten den leeren String enthalten, und für numerische Spalten, welche Spalten den Wert null enthalten. Beachten Sie, dass dies keine Spalten mit
NULL-Werten einbezieht. Wenn eine String-Spalte nach dem Entfernen angehängter Leerzeichen die Länge null hat oder eine numerischen Spalte den Wert Null hat, wird sie in der Bitmap markiert und nicht auf der Festplatte gespeichert. Nicht-leere Strings werden mit einem Längen-Byte plus dem String-Inhalt gespeichert.Sie benötigen normalerweise weniger Festplattenplatz als Festlängen-Tabellen.
Jede Zeile belegt nur so viel Platz wie nötig. Doch wenn eine Zeile wächst, wird sie aufgespalten, was zu Fragmentierung führt. Wenn Sie zum Beispiel eine Zeile mit Daten aktualisieren, die ihre Länge anwachsen lassen, so wird sie fragmentiert. In diesem Fall kann es erforderlich sein, gelegentlich
OPTIMIZE TABLEoder myisamchk -r auszuführen, um die Leistung zu verbessern. myisamchk -ei kann Ihnen Statistikdaten zu Ihrer Tabelle liefern.Sie sind nach einem Absturz schwerer zu rekonstruieren als Tabellen fester Länge, da die Zeilen unter Umständen in viele Stücke fragmentiert sind und Links (Fragmente) verlorengegangen sein könnten.
Die erwartete Zeilenlänge für dynamische Zeilen wird mit folgendem Ausdruck berechnet:
3 + (
number of columns+ 7) / 8 + (number of char columns) + (packed size of numeric columns) + (length of strings) + (number of NULL columns+ 7) / 8Für jeden Link kommen 6 Bytes hinzu. Eine dynamische Zeile wird immer dann verknüpft (verlinkt), wenn ein Update sie verlängert. Da jeder neue Link mindestens 20 Bytes hat, passt die nächste Verlängerung wahrscheinlich noch in denselben Link mit hinein. Wenn nicht, wird ein neuer Link angelegt. Die Anzahl der Links lässt sich mit myisamchk -ed feststellen. Alle Links können mit
OPTIMIZE TABLEoder myisamchk -r entfernt werden.
Das komprimierte Speicherformat ist ein nur-lesbares Format, das mit myisampack angelegt wird. Komprimierte Tabellen lassen sich mit myisamchk auch wieder dekomprimieren.
Kennzeichen von komprimierten Tabellen:
Sie belegen sehr wenig Platz auf der Festplatte. Dadurch wird der Speicherverbrauch minimiert, was bei der Verwendung langsamer Speichermedien (zum Beispiel CD-ROMs) praktisch ist.
Da jede Zeile separat komprimiert wird, funktioniert der Zugriff mit geringem Aufwand. Der Header für eine Zeile belegt ein bis drei Bytes, abhängig von der längsten Zeile der Tabelle. Jede Spalte wird anders komprimiert und normalerweise gibt es für jede Spalte einen unterschiedlichen Huffman-Baum. Einige der Kompressionsarten sind:
Suffix-Kompression (Komprimierung von Leerzeichen am Ende).
Präfix-Kompression (Komprimierung von Leerzeichen am Anfang).
Zahlen mit dem Wert Null werden in einem Bit gespeichert.
Wenn Werte in einer Integerspalte einen kleinen Wertebereich haben, wird die Spalte im kleinstmöglichen Typ gespeichert. So kann zum Beispiel eine
BIGINT-Spalte (acht Bytes) alsTINYINT-Spalte (ein Byte) gespeichert werden, wenn alle ihre Werte zwischen-128und127betragen.Hat eine Spalte nur eine kleine Menge möglicher Werte, wird ihr Datentyp in eine
ENUMkonvertiert.Eine Spalte kann eine beliebige Kombination der oben beschriebenen Komprimierungen verwenden.
Kann für Spalten fester oder dynamischer Länge verwendet werden.
Zwar wurde das von MySQL für die Datenspeicherung genutzte Dateiformat ausführlich getestet, aber es können immer Umstände auftreten, durch die Datenbanktabellen beschädigt werden. Im Folgenden wird erklärt, wie es dazu kommt und wie man damit umgeht.
Obwohl das Tabellenformat MyISAM sehr
zuverlässig ist (alle Änderungen, die eine SQL-Anweisung an
einer Tabelle vornimmt, werden geschrieben, ehe die Anweisung
zurückkehrt), können dennoch unter folgenden Umständen
Tabellen beschädigt werden:
Der mysqld-Prozess wird mitten in einem Schreibvorgang abgebrochen.
Der Computer wird unerwartet heruntergefahren (zum Beispiel ausgeschaltet).
Ein Hardware-Versagen.
Während eine Tabelle gerade vom Server modifiziert wird, ändern Sie dieselbe Tabelle mit einem externen Programm (zum Beispiel myisamchk).
Ein Software-Bug im Code von MySQL oder
MyISAM.
Die folgenden Symptome sind typisch für eine beschädigte Tabelle:
Beim Auswählen von Daten aus der Tabelle bekommen Sie folgende Fehlermeldung:
Incorrect key file for table: '...'. Try to repair it
Anfragen können Zeilen in der Tabelle nicht finden oder liefern unvollständige Ergebnisse zurück.
Mit der CHECK TABLE-Anweisung können Sie
die Integrität einer MyISAM-Tabelle
überprüfen und mit REPAIR TABLE können
Sie sie reparieren, wenn sie beschädigt ist. Wenn
mysqld nicht läuft, können Sie eine
Tabelle auch mit dem Befehlmyisamchk
prüfen oder reparieren Siehe hierzu auch
Abschnitt 13.5.2.3, „CHECK TABLE“, Abschnitt 13.5.2.6, „REPAIR TABLE“
und Abschnitt 8.2, „myisamchk — Hilfsprogramm für die Tabellenwartung von MyISAM“.
Werden Ihre Tabellen häufig beschädigt, so sollten Sie nach
den Ursachen forschen. Am wichtigsten ist es, festzustellen,
ob die Tabelle infolge eines Server-Absturzes beschädigt
wurde. Das können Sie leicht daran erkennen, dass im
Fehler-Log eine restarted mysqld-Nachricht
jüngeren Datums gespeichert ist. Wenn ja, dann wurde die
Tabelle wahrscheinlich durch den Absturz des Servers
beschädigt. Andernfalls kann der Schaden auch im normalen
Betrieb aufgetreten sein. Das wäre dann ein Bug. Versuchen
Sie in diesem Fall, einen reproduzierbaren Testfall zu
erstellen, der das Problem demonstriert. Siehe auch
Abschnitt A.4.2, „Was zu tun ist, wenn MySQL andauernd abstürzt“ und
Abschnitt E.1.6, „Erzeugen eines Testfalls, wenn Sie Tabellenbeschädigung feststellen“.
Jede MyISAM-Indexdatei
(.MYI-Datei) besitzt im Header einen
Zähler, an dem sich erkennen lässt, ob eine Tabelle
ordnungsgemäß geschlossen wurde. Liefert CHECK
TABLE oder myisamchk folgende
Warnung, so bedeutet dies, dass der Zähler nicht mehr
synchron läuft:
clients are using or haven't closed the table properly
Diese Warnung bedeutet zwar nicht unbedingt, dass die Tabelle beschädigt ist, aber Sie sollten zumindest eine Überprüfung vornehmen.
Der Zähler funktioniert folgendermaßen:
Wenn eine Tabelle in MySQL zum ersten Mal geändert wird, wird ein Zähler im Header der Indexdateien inkrementiert.
Bei nachfolgenden Änderungen bleibt der Zähler gleich.
Wenn die letzte Instanz einer Tabelle geschlossen wird (wegen einer
FLUSH TABLES-Operation oder weil im Tabellen-Cache kein Platz mehr ist), wird der Zähler dekrementiert, wenn die Tabelle an irgendeinem Punkt geändert wurde.Wenn Sie die Tabelle reparieren oder prüfen und für gut befinden, wird der Zähler wieder auf Null zurückgesetzt.
Um Abstimmungsprobleme mit anderen Prozessen zu verhindern, welche die Tabelle ebenfalls überprüfen, wird der Zähler beim Schließen nicht dekrementiert, wenn er den Wert null hatte.
Anders ausgedrückt: Der Zähler kann unter folgenden Bedingungen nicht mehr synchron sein:
Eine
MyISAM-Tabelle wird ohne vorherigesLOCK TABLESundFLUSH TABLESkopiert.MySQL ist zwischen einer Änderung und dem endgültigen Schließen der Tabelle abgestürzt. (Beachten Sie, dass auch in diesem Fall die Tabelle immer noch in Ordnung sein kann, da MySQL zwischen zwei Anweisungen immer alles schreibt.)
Eine Tabelle wurde von myisamchk --recover oder myisamchk --update-state geändert, während sie gleichzeitig von mysqld benutzt wurde.
Mehrere mysqld-Server benutzen die Tabelle und einer von ihnen hat
REPAIR TABLEoderCHECK TABLEauf ihr ausgeführt, während die anderen Server gerade auf sie zugriffen. In diesem Fall ist die Verwendung vonCHECK TABLEsicher, obwohl Sie vielleicht von anderen Servern eine Warnung bekommen.REPAIR TABLEsollten Sie allerdings vermeiden, denn wenn ein Server die Datendatei durch eine neue ersetzt, können die anderen Server dies nicht wissen.Normalerweise sollte man ein Data Directory nicht mit mehreren Servern gemeinsam nutzen. Weitere Hinweise finden Sie unter Abschnitt 5.13, „Mehrere MySQL-Server auf derselben Maschine laufen lassen“.
- 14.2.1. Überblick über InnoDB-Tabellen
- 14.2.2. Kontaktinformationen
- 14.2.3. Konfiguration
- 14.2.4.
InnoDB: Startoptionen und Systemvariablen - 14.2.5. InnoDB-Tablespace erzeugen
- 14.2.6.
InnoDB-Tabellen erzeugen - 14.2.7. Hinzufügen und Entfernen von InnoDB-Daten- und -Logdateien
- 14.2.8. Sichern und Wiederherstellen einer
InnoDB-Datenbank - 14.2.9. Eine InnoDB-Datenbank auf eine andere Maschine verschieben
- 14.2.10. InnoDB-Transaktionsmodell
- 14.2.11. Tipps zur Leistungssteigerung
- 14.2.12. Implementierung der Multiversionierung
- 14.2.13. Tabellen- und Indexstrukturen
- 14.2.14. Verwaltung von Speicherplatz für Dateien und von Festplattenein- und -ausgaben
- 14.2.15.
InnoDB-Fehlerbehandlung - 14.2.16. Beschränkungen von
InnoDB-Tabellen - 14.2.17.
InnoDB-Troubleshooting
Mit InnoDB verfügt MySQL über eine
transaktionssichere (ACID-konforme)
Speicher-Engine mit Commit-, Rollback- und
Datenwiederherstellungsfähigkeiten. InnoDB
beherrscht sowohl Zeilensperren als auch, ähnlich wie Oracle,
eine konsistente Leseoperation ohne Sperren für
SELECT-Anweisungen. Diese Features verbessern
die Mehrbenutzertauglichkeit und die Leistung.
InnoDB benötigt keine Sperreneskalation da
Zeilensperren sehr wenig Platz beanspruchen. Außerdem
unterstützt InnoDB die FOREIGN
KEY-Constraints. Sie können
InnoDB-Tabellen nach Belieben mit Tabellen aus
anderen MySQL-Speicher-Engines mischen, sogar in ein- und
derselben Anweisung.
InnoDB wurde für maximale Leistung bei der
Verarbeitung großer Datenmengen ausgelegt. Es gibt wohl keine
andere festplattengestützte Speicher-Engine für relationale
Datenbanken, die so effizient mit der CPU umgeht.
Die voll in den MySQL-Server integrierte
InnoDB-Speicher-Engine hat ihren eigenen
Bufferpool zur Speicherung von Daten und Indizes im Hauptspeicher.
InnoDB speichert ihre Tabellen und Indizes in
einem Tablespace, der aus mehreren Dateien (oder
Festplattenpartitionen) bestehen kann. Darin unterscheidet sie
sich beispielsweise von MyISAM, wo jede Tabelle
in separaten Dateien untergebracht wird.
InnoDB-Tabellen können beliebig groß sein,
selbst auf Betriebssystemen, deren Dateigröße auf 2GB
beschränkt ist.
InnoDB ist standardmäßig in
Binärdistributionen enthalten. Der Windows Essentials-Installer
macht InnoDB auf Windows zur
Standard-Speicher-Engine für MySQL.
InnoDB wird in einer Vielzahl großer
Produktionsdatenbanken eingesetzt, die hohe Anforderungen an die
Leistung stellen. Die bekannte Internet-Newssite Slashdot.org
läuft mit InnoDB. Mytrix speichert mehr als
1TB Daten in InnoDB und eine andere Site
verarbeitet durchschnittlich 800 Inserts/Updates pro Sekunde auf
InnoDB.
InnoDB unterliegt derselben GNU GPL License
Version 2 (von Juni 1991) wie MySQL. Weitere Informationen über
MySQL-Lizenzen finden Sie unter
http://www.mysql.com/company/legal/licensing/.
Ein spezielles
InnoDB-Forum finden Sie unter http://forums.mysql.com/list.php?22.
Mit Innobase Oy, dem Produzenten der
InnoDB-Engine können Sie wie folgt Kontakt
aufnehmen:
Web site: http://www.innodb.com/
Email: <sales@innodb.com>
Phone: +358-9-6969 3250 (office)
+358-40-5617367 (mobile)
Innobase Oy Inc.
World Trade Center Helsinki
Aleksanterinkatu 17
P.O.Box 800
00101 Helsinki
Finland
Die Speicher-Engine InnoDB ist nach
Voreinstellung aktiv. Wenn Sie keine
InnoDB-Tabellen verwenden möchten, setzen Sie
die Option skip-innodb in Ihre
MySQL-Optionsdatei.
Hinweis: Mit
InnoDB verfügt MySQL über eine
transaktionssichere (ACID-konforme)
Speicher-Engine mit Commit-, Rollback- und
Datenwiederherstellungsfähigkeiten. Diese
Fähigkeiten stehen jedoch nur dann zur Verfügung, wenn auch das
zugrunde liegende Betriebssystem und die Hardware
vorschriftsgemäß arbeiten.. Viele Betriebssysteme
oder Festplatten-Subsysteme verzögern Schreiboperationen oder
ordnen sie anders an, um die Leistung zu verbessern. Auf manchen
Betriebssystemen kann sogar der Systemaufruf selbst, der
eigentlich warten sollte, bis alle noch ungespeicherten Daten
einer Datei auf die Platte zurückgeschrieben wurden —
fsync() — bereits zurückkehren, ehe die
Daten in einen dauerhaften Speicher geschrieben wurden. So kann
zum Beispiel ein Betriebssystemabsturz oder ein Stromausfall
Daten, die gerade erst committet wurden, zerstören, oder im
schlimmsten Fall sogar die Datenbank schädigen, indem
Schreiboperationen in die verkehrte Reihenfolge gestellt werden.
Wenn Ihnen an der Integrität Ihrer Daten etwas liegt, sollten Sie
das Verhalten bei Stromausfall testen, ehe Sie etwas in die
Produktionsumgebung einführen. Auf Mac OS X 10.3 und höher
verwendet InnoDB eine spezielle
fcntl()-Methode, um Dateien auf die Festplatte
zurückzuschreiben. Unter Linux empfiehlt es sich, den
Write-Back-Cache zu deaktivieren.
Auf ATAPI-Festplatten kann es funktionieren, mit einem Befehl wie
hdparm -W0 /dev/hda den Write-Back-Cache zu
deaktivieren. Vorsicht! Manche Treiber oder
Festplattencontroller sind nicht in der Lage, den Write-Back-Cache
zu deaktivieren.
Zwei wichtige, von InnoDB verwalteten
Festplattenressourcen sind die Tablespace-Datendateien und die
Logdateien.
Hinweis: Wenn Sie
Konfigurationsoptionen für InnoDB angeben,
erzeugt MySQL eine sich selbst erweiternde, 10MB große Datendatei
namens ibdata1 und zwei 5MB große Logdateien
namens ib_logfile0 und
ib_logfile1 im MySQL Data Directory. Um eine
gute Performance zu erzielen, sollten Sie explizit die in den
folgenden Beispielen erwähnten
InnoDB-Parameter setzen, allerdings natürlich
angepasst an Ihre Hardware und Systemanforderungen.
Die folgenden Beispiele haben nur repräsentativen Charakter. In
Abschnitt 14.2.4, „InnoDB: Startoptionen und Systemvariablen“ erfahren Sie mehr über die
Konfigurationsparameter für InnoDB.
Die InnoDB-Tablespace-Dateien richten Sie ein,
indem Sie die Option innodb_data_file_path im
[mysqld]-Abschnitt der Optionsdatei
my.cnf einstellen. Auf Windows verwenden Sie
stattdessen my.ini. Der
innodb_data_file_path sollte eine Liste mit
einer oder mehreren Datendatei-Spezifikationen sein. Mehrere
Datendateien werden durch Semikola
(‘;’) getrennt:
innodb_data_file_path=datafile_spec1[;datafile_spec2]...
Eine Einstellung, die explizit einen Tablespace mit den Standardmerkmalen anlegt, wäre beispielsweise:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend
Diese Einstellung konfiguriert eine einzige 10MB große Datendatei
namens ibdata1, die sich selbsttätig
erweitert. Da kein Verzeichnis vorgegeben ist, legt
InnoDB sie im MySQL Data Directory an.
Größen geben Sie an, indem Sie das Suffix M
für MB oder G für GB verwenden.
Ein Tablespace mit einer 50MB großen Datendatei fester Größe
namens ibdata1 und einer 50MB großen,
selbsterweiternden Datei namens ibdata2 im
Data Directory kann folgendermaßen konfiguriert werden:
[mysqld] innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
Zur vollständigen Syntax einer Datendateispezifikation gehören Dateiname, Größe und mehrere optionale Attribute:
file_name:file_size[:autoextend[:max:max_file_size]]
autoextend und die folgenden Attribute können
nur für die letzte Datendatei auf der Zeile
innodb_data_file_path verwendet werden.
Wenn Sie die Option autoextend für die letzte
Datendatei angeben, erweitert InnoDB diese
Datei, sobald sie im Tablespace nicht mehr genug freien Platz hat,
in Inkrementierungsschritten, die auf 8MB voreingestellt sind.
Diese Einstellung kann in der Systemvariablen
innodb_autoextend_increment geändert werden.
Wenn die Platte vollläuft, müssen Sie eine andere Datendatei oder Festplatte hinzufügen. Eine Anleitung zur Rekonfiguration vorhandener Tablespaces finden Sie in Abschnitt 14.2.7, „Hinzufügen und Entfernen von InnoDB-Daten- und -Logdateien“.
Da InnoDB die maximale Dateigröße des
Dateisystems nicht kennt, müssen Sie aufpassen, wenn Ihr
Dateisystem nur einen relativ kleinen Wert wie etwa 2GB zulässt.
Eine Maximalgröße für eine selbsterweiternde Datendatei geben
Sie mit dem Attribut max an. In der folgenden
Konfiguration kann ibdata1 auf bis zu 500MB
anwachsen:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend:max:500M
InnoDB legt Ttablespace-Dateien standardmäßig
im MySQL Data Directory an. Um ein anderes Verzeichnis anzugeben,
verwenden Sie die Option innodb_data_home_dir.
Wenn sie zum Beispiel zwei Dateien namens
ibdata1 und ibdata2 im
Verzeichnis /ibdata anlegen möchten, müssen
Sie InnoDB wie folgt konfigurieren:
[mysqld] innodb_data_home_dir = /ibdata innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
Hinweis: Da
InnoDB keine Verzeichnisse erstellt, müssen
Sie dafür sorgen, dass /ibdata existiert,
ehe Sie den Server starten. Das gilt auch für
Logdateiverzeichnisse, die Sie konfigurieren. Mit dem Unix- oder
DOS-Befehl mkdir können Sie alle
erforderlichen Verzeichnisse anlegen.
InnoDB bildet Verzeichnispfade für
Datendateien, indem es den Wert von
innodb_data_home_dir mit dem Namen der
Datendatei verkettet, und wenn nötig ein Pfadtrennzeichen
(Schrägstrich oder Backslash) zwischen die Werte setzt. Wenn die
Option innodb_data_home_dir in
my.cnf gar nicht auftaucht, ist der
Standardwert das „Punkt“-Verzeichnis
./, also das MySQL Data Directory. (Der
MySQL-Server macht das Data Directory zum aktuellen
Arbeitsverzeichnis, wenn er seine Arbeit aufnimmt.)
Wenn Sie innodb_data_home_dir als leeren String
angeben, können Sie absolute Pfade für die Datendateien angeben,
die im Wert von innodb_data_file_path
aufgeführt sind. Das folgende Beispiel ist äquivalent zu dem
vorherigen:
[mysqld] innodb_data_home_dir = innodb_data_file_path=/ibdata/ibdata1:50M;/ibdata/ibdata2:50M:autoextend
Ein einfaches
my.cnf-Beispiel. Angenommen, Sie
haben einen Computer mit 128MB Arbeitsspeicher und einer
Festplatte. Das folgende Beispiel zeigt mögliche
Konfigurationsparameter in my.cnf oder
my.ini für InnoDB,
einschließlich des autoextend-Attributs. Das
Beispiel passt zu den meisten Unix- und Windows-Benutzern, die
ihre InnoDB-Datendateien und -Logdateien nicht
auf mehrere Festplatten verteilen möchten. Es legt eine
selbsterweiternde Datendatei namens ibdata1
und zwei InnoDB-Logdateien namens
ib_logfile0 und
ib_logfile1 im MySQL Data Directory an.
Außerdem wird die kleine, archivierte
InnoDB-Logdatei
ib_arch_log_0000000000, die
InnoDB automatisch erstellt, ins Data Directory
gespeichert.
[mysqld] # Hier können Sie Ihre übrigen MySQL-Server-Optionen angeben # ... # Datendateien müssen Daten und Indizes speichern können. # Achten Sie auf ausreichend freien Plattenplatz. innodb_data_file_path = ibdata1:10M:autoextend # # Bufferpool-Größe wird auf 50-80% vom Arbeitsspeicher eingestellt innodb_buffer_pool_size=70M innodb_additional_mem_pool_size=10M # # Logdateigröße wird auf 25% der Bufferpool-Größe eingestellt innodb_log_file_size=20M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1
Achten Sie darauf, dass der MySQL-Server die richtigen Berechtigungen hat, um Dateien im Data Directory anlegen zu können. Generell benötigt der Server Zugriffsrecht auf jedes Verzeichnis, in dem er Daten- oder Logdateien anlegen soll.
Beachten Sie, dass Datendateien in manchen Dateisystemen höchstens 2GB groß sein dürfen. Die kombinierte Größe aller Logdateien muss unter 4GB liegen und die kombinierte Größe der Datendateien mindestens 10MB betragen.
Wenn Sie zum ersten Mal einen InnoDB-Tablespace
anlegen, starten Sie den MySQL-Server am besten von der
Kommandozeile. Da InnoDB dann Informationen
über die Datenbankerstellung auf dem Bildschirm ausgibt, können
Sie sehen, was geschieht. Wenn beispielsweise auf Windows
mysqld-max im Verzeichnis C:\Program
Files\MySQL\MySQL Server 5.1\bin liegt,
können Sie folgendermaßen starten:
C:\> "C:\Program Files\MySQL\MySQL Server 5.1\bin\mysqld-max" --console
Wenn sie keine Serverausgabe an den Bildschirm schicken, müssen
Sie im Fehlerlog nachschauen, welche Meldungen
InnoDB beim Hochfahren ausgibt.
Unter Abschnitt 14.2.5, „InnoDB-Tablespace erzeugen“ sehen Sie ein Beispiel dafür,
welche Informationen InnoDB anzeigt.
Die InnoDB-Optionen können Sie in die
[mysqld]-Gruppe einer beliebigen Optionsdatei
legen, die Ihr Server beim Hochfahren liest. Speicherorte für
Optionsdateien werden in Abschnitt 4.3.2, „my.cnf-Optionsdateien“
beschrieben.
Wenn Sie MySQL auf Windows mit dem Installations- und
Konfigurationsassistenten installiert haben, liegen die Optionen
in der my.ini-Datei in Ihrem
MySQL-Installationsverzeichnis. Siehe
Abschnitt 2.3.5.14, „Speicherort der Datei my.ini“.
Wenn Ihr PC einen Bootloader nutzt und C:
nicht das Bootverzeichnis ist, haben Sie keine andere
Möglichkeit, als die my.ini-Datei in Ihrem
Windows-Verzeichnis zu benutzen (in der Regel
C:\WINDOWS oder
C:\WINNT). Verwenden Sie den Befehl
SET auf der Kommandozeile eines
Konsolenfensters, um den Wert von WINDIR
auszugeben:
C:\> SET WINDIR
windir=C:\WINDOWS
Wenn Sie sicherstellen möchten, dass
mysqld-Optionen nur aus einer bestimmten Datei
liest, verwenden Sie --defaults-option beim
Serverstart als erste Option auf der Kommandozeile:
mysqld --defaults-file=your_path_to_my_cnf
Ein
fortgeschrittenesmy.cnf-Beispiel.
Angenommen, Sie haben einen Linux-Computer mit 2GB RAM und drei
60GB-Festplatten mit den Verzeichnispfaden /,
/dr2 und /dr3. Das
folgende Beispiel zeigt, welche Konfigurationsparameter man in
my.cnf für InnoDB setzen
könnte.
[mysqld] # Hier können Sie Ihre übrigen MySQL-Server-Optionen angeben # ... innodb_data_home_dir = # # Datendateien müssen Daten und Indizes speichern können. innodb_data_file_path = /ibdata/ibdata1:2000M;/dr2/ibdata/ibdata2:2000M:autoextend # # Setzen Sie die Bufferpool-Größe auf 50-80% des Arbeitsspeichers, # aber achten Sie darauf, dass für Linux x86 die gesamte Speichernutzung < 2GB ist. innodb_buffer_pool_size=1G innodb_additional_mem_pool_size=20M innodb_log_group_home_dir = /dr3/iblogs # innodb_log_files_in_group = 2 # # Setzen Sie die Logdateigröße auf circa 25% der Bufferpool-Größe innodb_log_file_size=250M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1 innodb_lock_wait_timeout=50 # # Kommentieren Sie die nächsten Zeilen aus, wenn Sie sie nutzen möchten #innodb_thread_concurrency=5
In manchen Fällen steigt die Datenbank-Performance, wenn nicht
alle Daten auf derselben physikalischen Platte liegen. Oft ist es
gut für die Performance, wenn die Logdateien auf einer anderen
Festplatte liegen. Das Beispiel zeigt, wie das geht: Es speichert
zwei Dateien auf verschiedenen Festplatten und legt die Logdateien
auf eine dritte Platte. InnoDB füllt den
Tablespace beginnend mit der ersten Datendatei. Für einen
schnelleren Zugriff können Sie auch rohe Festplattenpartitionen
(Raw Devices) als InnoDB-Datendateien
verwenden. Siehe Abschnitt 14.2.3.2, „Verwendung von Raw Devices für den Shared Tablespace“.
Warnung: Auf 32-Bit GNU/Linux x86
dürfen Sie die Arbeitsspeichernutzung nicht zu hoch einstellen.
Wenn glibc den Prozess-Heap über die
Thread-Stacks hinauswachsen lässt, stürzt der Server ab. Wenn
der Wert des folgenden Ausdrucks 2GB erreicht oder übersteigt,
ist Gefahr in Verzug:
innodb_buffer_pool_size + key_buffer_size + max_connections*(sort_buffer_size+read_buffer_size+binlog_cache_size) + max_connections*2MB
Jeder Thread benutzt einen Stack (oft 2MB, aber in den Binaries
von MySQL AB nur 256KB) und im schlimmsten Fall auch
sort_buffer_size + read_buffer_size
zusätzlichen Arbeitsspeicher.
Indem Sie MySQL selbst kompilieren, können Sie bis zu 64GB
physikalischen Speicher in 32-Bit Windows verwenden. Siehe
Beschreibung von innodb_buffer_pool_awe_mem_mb
in Abschnitt 14.2.4, „InnoDB: Startoptionen und Systemvariablen“.
Wie werden die anderen mysqld-Serverparameter eingestellt? Die folgenden Werte sind typisch und eignen sich für die meisten Nutzer:
[mysqld]
skip-external-locking
max_connections=200
read_buffer_size=1M
sort_buffer_size=1M
#
# Setzen Sie key_buffer auf 5 - 50% Ihres Arbeitsspeichers, je nachdem, wie
# oft Sie MyISAM-Tabellen benutzen, aber behalten Sie key_buffer_size + InnoDB
# buffer pool size < 80% Ihres Arbeitsspeichers
key_buffer_size=value
Sie können jede InnoDB-Tabelle und ihre
Indizes in ihrer eigenen Datei speichern. Dieses Feature nennt
man „Multi-Tablespaces“ da im Endeffekt jede
Tabelle ihren eigenen Tablespace bekommt.
Multi-Tablespaces sind praktisch für Benutzer, die bestimmte
Tabellen auf separate physikalische Platten verlagern oder
Backups einzelner Tabellen rasch wiederherstellen möchten, ohne
die Arbeit mit den übrigen InnoDB-Tabellen
zu unterbrechen.
Aktivieren Sie Multi-Tablespaces mit folgender Zeile im
[mysqld]-Abschnitt von
my.cnf:
[mysqld] innodb_file_per_table
Nach dem Server-Neustart speichert InnoDB
jede neu erzeugte Tabelle in einer eigenen Datei
tbl_name.ibdMyISAM-Speicher-Engine, doch diese spaltet
die Tabellen in eine Datendatei
tbl_name.MYDtbl_name.MYIInnoDB werden Daten und Indizes gemeinsam
in der.ibd-Datei gespeichert. Die
tbl_name.frm
Wenn Sie die innodb_file_per_table-Zeile aus
my.cnf löschen und den Server neu starten,
erzeugt InnoDB die Tabellen wieder in Shared
Tablespace-Dateien.
innodb_file_per_table wirkt sich nur auf eine
einzelne Tabellenerzeugung aus, und beeinflusst nicht den
Zugriff auf bestehende Tabellen. Wenn Sie den Server mit dieser
Option starten, werden neue Tabellen mit
.ibd-Dateien angelegt, aber alte liegen
immer noch im Shared Tablespace. Entfernen Sie die Option wieder
und starten dann den Server neu, werden die neuen Tabellen im
Shared Tablespace angelegt, aber Tabellen, die mit
Multi-Tablespaces angelegt wurden, bleiben weiterhin
zugänglich.
InnoDB benötigt immer den Shared Tablespace,
da es sein internes Data Dictionary und seine Undo-Logs dort
speichert. Die .ibd-Dateien reichen
InnoDB zum Funktionieren nicht aus.
Hinweis: Sie können
.ibd-Dateien genau wie
MyISAM-Tabellendateien nach Belieben zwischen
Datenbankverzeichnissen hin- und herschieben, weil die im Shared
Tablespace von InnoDB gespeicherte
Tabellendefinition den Datenbanknamen enthält und weil
InnoDB die Konsistenz von Transaktions-IDs
und Lognummern beibehalten muss.
Um eine .ibd-Datei und die zugehörige
Tabelle von einer Datenbank in eine andere zu verlagern,
verwenden Sie eine RENAME TABLE-Anweisung:
RENAME TABLEdb1.tbl_nameTOdb2.tbl_name;
Wenn Sie über ein „sauberes“ Backup einer
.ibd-Datei verfügen, können Sie diese in
ihrer angestammten MySQL-Installation folgendermaßen
wiederherstellen:
Geben Sie folgende
ALTER TABLE-Anweisung:ALTER TABLE
tbl_nameDISCARD TABLESPACE;Vorsicht: Diese Anweisung löscht die aktuelle
.ibd-Datei.Speichern Sie die
.ibd-Backup-Datei zurück in das richtige Datenbankverzeichnis.Geben Sie folgende
ALTER TABLE-Anweisung:ALTER TABLE
tbl_nameIMPORT TABLESPACE;
Ein „sauberes“ Backup einer
.ibd-Datei bedeutet in diesem Zusammenhang:
Keine schwebenden Transaktionen in der
.ibd-Datei.Keine noch nicht zusammengeführten Insert-Puffer-Einträge in der
.ibd-Datei.Purge hat alle zum Löschen vorgemerkten Indexeinträge aus der
.ibd-Datei entfernt.mysqld hat alle geänderten Seiten der
.ibd-Datei aus dem Bufferpool in die Datei zurückgeschrieben.
Mit folgender Methode können Sie eine saubere
.ibd-Backup-Datei anlegen:
Beenden Sie alle Aktivitäten des mysqld-Servers und schreiben Sie alle Transaktionen fest.
Warten Sie, bis
SHOW ENGINE INNODB STATUSanzeigt, dass keine Transaktionen mehr in der Datenbank aktiv sind und der Status des Haupt-Threads vonInnoDBden WertWaiting for server activityangenommen hat. Dann können Sie die.ibd-Datei kopieren.
Eine andere Möglichkeit, an eine saubere Kopie einer
.ibd-Datei zu kommen, ist die Verwendung
eines kommerziellen InnoDB Hot Backup-Tools:
Legen Sie mit InnoDB Hot Backup ein Backup der
InnoDB-Installation an.Starten Sie einen zweiten mysqld-Server auf dem Backup und lassen Sie ihn die
.ibd-Dateien im Backup säubern.
Sie können auch rohe Festplattenpartitionen für die Datendateien im Shared Tablespace verwenden. So können sie ungepufferte E/A-Zugriffe ohne Dateisystem-Overhead auf Windows und einigen Unix-Systemen implementieren und die Performance dadurch steigern.
Wenn Sie eine neue Datendatei anlegen, müssen Sie in
innodb_data_file_path das Schlüsselwort
newraw direkt hinter die Größe der
Datendatei setzen. Die Partition muss mindestens die angegebene
Größe haben. Beachten Sie, dass 1MB in
InnoDB 1024 × 1024 Bytes sind, während
1MB in Festplattenspezifikationen normalerweise 1.000.000 Bytes
bedeutet.
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:3Gnewraw;/dev/hdd2:2Gnewraw
Wenn Sie den Server das nächste Mal starten, bemerkt
InnoDB das Schlüsselwort
newraw und initialisiert die neue Partition.
Sie dürfen jetzt aber noch keine
InnoDB-Tabellen ändern oder anlegen, sonst
reinitialisiert InnoDB beim nächsten
Serverstart die Partition und Ihre Änderungen gehen verloren.
(Als Sicherheitsmaßnahme hindert InnoDB die
Benutzer daran, irgendwelche Daten zu ändern, wenn eine
Partition mit newraw definiert wurde.)
Nachdem InnoDB die neue Partition
initialisiert hat, halten Sie den Server an und ändern
newraw in der Datendateispezifikation in
raw um:
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:5Graw;/dev/hdd2:2Graw
Wenn Sie nun den Server erneut starten, erlaubt
InnoDB auch Änderungen.
Auf Windows können Sie eine Festplattenpartition folgendermaßen als Datendatei zuweisen:
[mysqld] innodb_data_home_dir= innodb_data_file_path=//./D::10Gnewraw
Das //./ entspricht beim Zugriff auf
physikalische Platten der Windows-Syntax
\\.\.
Wenn Sie rohe Festplattenpartitionen benutzen, achten Sie bitte darauf, dass ihre Berechtigungseinstellungen dem vom MySQL-Server benutzten Konto auch Lese- und Schreiboperationen gestatten.
Dieser Abschnitt beschreibt die Befehlsoptionen und
Systemvariablen für InnoDB. Systemvariablen,
die true oder false sein können, werden beim Serverstart entweder
durch Nennung ihres Namens aktiviert oder mit dem Präfix
skip- deaktiviert. Um beispielsweise
InnoDB-Prüfsummen ein- oder auszuschalten,
verwenden Sie --innodb_checksums oder
--skip-innodb_checksums auf der Kommandozeile,
oder innodb_checksums oder
skip-innodb_checksums in einer Optionsdatei.
Systemvariablen, die einen numerischen Wert annehmen, können als
--
auf der Kommandozeile oder als
var_name=valuevar_name=value
InnoDB-Befehlsoptionen:
--innodbAktiviert die
InnoDB-Speicher-Engine, wenn der Server mitInnoDB-Unterstützung kompiliert wurde. Mit--skip-innodbkönnen SieInnoDBdeaktivieren.--innodb_status_fileVeranlasst
InnoDB, eine Datei namens<datadir>/innodb_status.<pid>InnoDBschreibt in regelmäßigen Abständen die Ausgabe vonSHOW ENGINE INNODB STATUSin diese Datei.
InnoDB-Systemvariablen:
innodb_additional_mem_pool_sizeDie Größe des von
InnoDBzum Speichern von Data Dictionary-Informationen und anderen internen Datenstrukturen verwendeten Arbeitsspeicherpools in Bytes. Je mehr Tabellen Ihre Anwendung hat, umso mehr Arbeitsspeicher müssen Sie hier zuweisen. WennInnoDBin diesem Pool der Speicher ausgeht, beginnt es, Arbeitsspeicher vom Betriebssystem abzuzweigen, und gibt Warnmeldungen in das MySQL-Fehlerlog aus. Der Standardwert beträgt 1MB.innodb_autoextend_incrementIn Inkrementen dieser Größe (in MB) wächst ein selbsterweiternder Tablespace, wenn er vollläuft. Der Standardwert beträgt 8.
innodb_buffer_pool_awe_mem_mbDie Größe des Bufferpools (in MB), wenn er im AWE-Speicher liegt. Dies gilt jedoch nur für 32-Bit Windows. Wenn Ihr 32-Bit Windows-Betriebssystem über die so genannten „Address Windowing Extensions“ mehr als 4GB Arbeitsspeichergröße unterstützt, können Sie den
InnoDB-Bufferpool im physikalischen AWE-Speicher mit dieser Variablen zuweisen. Der größtmögliche Wert der Variablen beträgt 63000. Ist er größer als 0, istinnodb_buffer_pool_sizedas Fenster im 32-Bit-Adressraum von mysqld, wobeiInnoDBdiesen AWE-Arbeitsspeicher abbildet. Ein guter Wert fürinnodb_buffer_pool_sizeist 500MB.Um den AWE-Speicher nutzen zu können, müssen Sie MySQL neu kompilieren. Welche Projekteinstellungen derzeit dazu erforderlich sind, entnehmen Sie bitte der Quelldatei
storage/innobase/os/os0proj.c.innodb_buffer_pool_sizeDie Größe des Arbeitsspeicherpuffers in Bytes, den
InnoDBzum Zwischenspeichern der Daten und Indizes seiner Tabellen benutzt. Je größer Sie diesen Wert einstellen, umso weniger Festplattenzugriffe sind für den Zugriff auf die Tabellendaten erforderlich. Für einen dedizierten Datenbankserver können Sie dies auf 80% des physikalischen Arbeitsspeichers heraufsetzen. Machen Sie ihn jedoch nicht zu groß, da ein Wettlauf um den physikalischen Speicher das Betriebssystem zum Paging veranlassen kann.innodb_checksumsInnoDBkann für alle von der Platte gelesenen Seiten eine Prüfsummenvalidierung verwenden, um eine zusätzliche Fehlertoleranz gegenüber Schäden an Hardware oder Datendateien zu gewährleisten. Diese Validierung ist standardmäßig eingeschaltet. Doch in einigen wenigen Fällen (zum Beispiel bei der Ausführung von Benchmarks) ist diese zusätzliche Sicherheitsvorkehrung überflüssig und kann mit--skip-innodb-checksumsdeaktiviert werden.innodb_commit_concurrencyDie Anzahl der Threads, die gleichzeitig committen können. Der Wert 0 schaltet die Nebenläufigkeitssteuerung aus.
innodb_concurrency_ticketsWie viele Threads gleichzeitig auf
InnoDBzugreifen können, hängt von der Einstellung derinnodb_thread_concurrency-Variablen ab. Ein Thread wird in eine Schlange gestellt, wenn er aufInnoDBzugreifen möchte und das Nebenläufigkeitslimit bereits erreicht ist. Wenn einem Thread der Eintritt inInnoDBerlaubt wird, bekommt eine Anzahl von „Freifahrscheine“, die der Anzahl derinnodb_concurrency_ticketsentspricht und kannInnoDBso lange nach Belieben betreten und verlassen, bis seine Freifahrscheine aufgebraucht sind. Danach wird der Thread wieder einer Prüfung unterzogen (und eventuell in die Schlange gestellt), wenn er das nächste Mal inInnoDBeintreten möchte.innodb_data_file_pathDie Pfade und Größen der einzelnen Datendateien. Der vollständige Verzeichnispfad zu den Datendateien entsteht, wenn
innodb_data_home_dirmit den einzelnen, hier angegebenen Pfaden verkettet wird. Die Dateigrößen werden in MB oder GB (1024MB) durch Anfügen vonModerGan den Größenwert angegeben. Die Summe der Dateigrößen muss mindestens 10MB betragen. Wenn Sie keineninnodb_data_file_pathangeben, wird standardmäßig eine einzige, selbsterweiternde, 10MB große Datendatei namensibdata1erzeugt. Wie groß die einzelnen Dateien werden können, entscheidet Ihr Betriebssystem. Auf Systemen, die große Dateien unterstützen, können Sie die Dateigröße auf mehr als 4GB setzen. Sie können auch rohe Festplattenpartitionen als Datendateien einsetzen. Siehe Abschnitt 14.2.3.2, „Verwendung von Raw Devices für den Shared Tablespace“.innodb_data_home_dirDer gemeinsame Teil des Verzeichnispfads für alle
InnoDB-Datendateien. Wenn Sie diesen Wert nicht einstellen, ist das MySQL Data Directory das Ziel. Geben Sie hier einen leeren String an, so können Sie ininnodb_data_file_pathabsolute Dateipfade verwenden.innodb_doublewriteNach Voreinstellung speichert
InnoDBalle Daten zweimal, nämlich zuerst in den Doublewrite-Puffer und dann in die eigentlichen Datendateien. Diese Variable ist standardmäßig eingeschaltet, kann aber mit der Option--skip-innodb_doublewriteausgeschaltet werden, wenn Sie Benchmarks ausführen oder Ihnen eine Top-Performance so wichtig ist, dass Sie sich für Datenintegrität und mögliche Systemabstürze weniger interessieren.innodb_fast_shutdownWenn Sie diese Variable auf 0 setzen, führt
InnoDBvor dem Herunterfahren eine vollständige Purge-Operation und Verschmelzung der Insert-Puffer durch. Diese Operationen können Minuten oder im Extremfall sogar Stunden in Anspruch nehmen. Setzen Sie diese Variable auf 1, übergehtInnoDBbeim Herunterfahren diese Operationen. Der Standardwert ist 1. Wenn Sie ihn auf 2 setzen, leertInnoDBnur die Logs und fährt dann kalt herunter, wie bei einem Absturz von MySQL. Es geht zwar keine committete Transaktion verloren, aber nach dem nächsten Hochfahren wird eine Wiederherstellung gefahren. Den Wert 2 können Sie nicht auf NetWare verwenden.innodb_file_io_threadsDie Anzahl der Dateizugriffs-Threads in
InnoDB. Normalerweise kann man den Standardwert 4 beibehalten, aber auf Windows kann eine größere Zahl die Festplattenzugriffe günstig beeinflussen. Auf Unix bleibt eine Erhöhung dieses Werts ohne Wirkung, daInnoDBimmer den Standardwert verwendet.innodb_file_per_tableWenn diese Variable eingeschaltet ist, erzeugt
InnoDBjede neue Tabelle mit ihrer eigenen.ibd-Datei zum Speichern von Daten und Indizes, anstatt im Shared Tablespace. Nach Voreinstellung werden die Tabellen im Shared Tablespace angelegt. Siehe Abschnitt 14.2.3.1, „Verwendung von Tabellen-Tablespaces (ein Tablespace pro Tabelle)“.innodb_flush_log_at_trx_commitHat
innodb_flush_log_at_trx_commitden Wert 0, wird einmal pro Sekunde der Logpuffer in die Logdatei geschrieben und diese auf die Festplatte zurückgespeichert, doch beim Committen einer Transaktion wird nichts veranlasst. Ist der Wert 1 (der Standard), wird bei jedem Commit der Logpuffer in die Logdatei und diese auf die Festplatte geschrieben. Ist der Wert 2, wird der Puffer bei jedem Commit in die Datei übertragen, aber diese nicht beim Commit, sondern einmal pro Sekunde auf die Festplatte zurückgeschrieben. Beachten Sie jedoch, dass dieser Schreibvorgang aus Gründen der Prozessplanung in Wirklichkeit nicht unbedingt exakt einmal pro Sekunde stattfindet.Der Standardwert dieser Variablen, nämlich 1, ist für die ACID-Fähigkeit erforderlich. Ein anderer Wert als 1 kann zwar die Performance steigern, aber um den Preis, dass Sie bei einem Systemabsturz eine Sekunde an Transaktionen verlieren. Ist der Wert 0, kann jeder Absturz des mysqld-Prozesses die Transaktionen der letzten Sekunde ausradieren. Ist der Wert 2, würde dieser Datenverlust bei einem Betriebssystemabsturz oder Stromausfall eintreten. Da allerdings die Wiederherstellungsfunktion von
InnoDBnicht beeinträchtigt wird, würde die Crash-Recovery unabhängig vom Wert dieser Variablen funktionieren. Beachten Sie jedoch, dass viele Betriebssysteme und einige Festplatten die Flush-to-Disk-Operation irreführen, indem sie mysqld weismachen, dass die Daten bereits auf die Festplatte geschrieben wurden, auch wenn das nicht der Fall ist. Die Dauerhaftigkeit von Transaktionen ist also selbst mit der Einstellung 1 nicht gewährleistet, und im schlimmsten Falle kann ein Stromausfall sogar dieInnoDB-Datenbank beschädigen. Ein batteriegestützter Festplatten-Cache im SCSI-Festplattencontroller oder in der Festplatte selbst kann das Zurückschreiben von Dateien auf die Festplatte beschleunigen und die Operation sicherer machen. Außerdem können Sie mit dem Unix-Befehl hdparm das Caching von Festplatten-Schreibvorgängen in Hardware-Caches deaktivieren oder einen anderen Hardware-spezifischen Befehl verwenden.innodb_flush_methodDie Standardeinstellung
fdatasyncsorgt dafür, dassInnoDBDaten- und Logdateien mitfsync()auf die Festplatte schreibt. Die EinstellungO_DSYNClässtInnoDBLogdateien mitO_SYNCöffnen und auf die Festplatte schreiben, aber für Datendateienfsync()verwenden. Die (auf einigen GNU/Linux-Versionen mögliche) EinstellungO_DIRECTveranlasstInnoDB, Datendateien mitO_DIRECTzu öffnen und Daten- und Logdateien mitfsync()auf die Festplatte schreiben. Beachten Sie, dassInnoDBdie Funktionfsync()anstelle vonfdatasync()benutzt undO_DSYNCnicht standardmäßig einsetzt, weil dies mit vielen Unix-Varianten bereits zu Problemen geführt hat. Diese Variable ist nur für Unix relevant. Auf Windows wird immer und unabänderlichasync_unbufferedzum Zurückschreiben von Daten auf die Festplatte verwendet.innodb_force_recoveryDer Crash-Recovery-Modus. Warnung: Diese Variable sollte nur im Notall, wenn Tabellen aus einer beschädigten Datenbank gesichert werden sollen, auf 0 gesetzt werden! Die Bedeutung der möglichen Werte 1 bis 6 wird in Abschnitt 14.2.8.1, „Erzwingen einer
InnoDB-Wiederherstellung (Recovery)“ erläutert. Als Sicherheitsmaßnahme verhindertInnoDBalle Änderungen an Daten, wenn diese Variable größer als 0 ist.innodb_lock_wait_timeoutGibt an, wie viele Sekunden eine
InnoDB-Transaktion auf eine Sperre wartet, ehe sie zurückgerollt wird.InnoDBentdeckt automatisch Transaktions-Deadlocks in seiner eigenen Sperrentabelle und macht dann die Transaktion rückgängig.InnoDBerkennt Sperren, die mit derLOCK TABLES-Anweisung gesetzt wurden. Die Standardeinstellung beträgt 50 Sekunden.Hinweis: Die größtmögliche Dauerhaftigkeit und Konsistenz in einer Replikationsumgebung mit
InnoDBund Transaktionen erzielen Sie, wenn Sie in dermy.cnf-Datei Ihres Masterserversinnodb_flush_log_at_trx_commit=1undsync_binlog=1einstellen.innodb_locks_unsafe_for_binlogDiese Variable steuert Next-Key-Locking in
InnoDB-Suchoperationen und Index-Scans. Standardmäßig ist diese Variable 0 (deaktiviert) und das Next-Key-Locking somit eingeschaltet.Normalerweise benutzt
InnoDBeinen Algorithmus namens Next-Key-Locking. Zeilensperren funktionieren inInnoDBfolgendermaßen: Wenn ein Tabellenindex durchsucht oder gescannt wird, errichtetInnoDBShared oder exklusive Sperren auf allen gefundenen Indexeinträgen. Somit sind die Zeilensperren in Wirklichkeit Sperren auf Indexeinträgen. Diese Sperren betreffen auch die „Lücke“, die den Indexeinträgen vorausgeht. Wenn ein Benutzer eine Shared oder exklusive Sperre auf Eintrag R eines Index hat, können andere Benutzer keine neuen Indexeinträge unmittelbar vor R in diesen Index einfügen. Ist diese Variable eingeschaltet, wird Next-Key-Locking vonInnoDBnicht nicht in Suchoperationen oder Index-Scans verwendet, wohl aber zur Sicherung von Fremdschlüssel-Constraints und Prüfung auf Schlüsselduplikate. Das Einschalten dieser Variablen kann Phantomprobleme verursachen: Angenommen, Sie möchten alle Kinder derchild-Tabelle, die einen Identifier-Wert größer 100 haben, lesen und sperren, da Sie vorhaben, in den ausgewählten Zeilen später eine Spalte zu ändern:SELECT * FROM child WHERE id > 100 FOR UPDATE;
Nehmen wir weiterhin an, auf der Spalte
idist ein Index definiert. Die Anfrage scannt diesen Index ab dem ersten Eintrag, in demidgrößer als 100 ist. Wenn die auf den Indexeinträgen errichteten Sperren Einfügungen in den Lücken nicht ausschließen, kann ein anderer Client eine neue Zeile in die Tabelle einfügen. Wenn Sie dasselbeSELECTin derselben Transaktion ausführen, sehen Sie in der Ergebnismenge eine neue Zeile. Das führt auch dazu, dassInnoDBbei Einfügung neuer Elemente in die Datenbank keine Serialisierbarkeit garantieren kann. Folglich gewährleistetInnoDBbei Einschaltung dieser Variablen maximal die IsolationsebeneREAD COMMITTED. (Die Konfliktserialisierbarkeit ist aber nach wie vor garantiert.)Die Einschaltung dieser Variablen hat noch einen Zusatzeffekt:
InnoDBsperrt in einemUPDATEoderDELETEnur die Zeilen, die aktualisiert bzw. gelöscht werden. Dadurch werden Deadlocks zwar sehr unwahrscheinlich, können aber immer noch auftreten. Beachten Sie, dass das Einschalten dieser Variablen nach wie vor nicht erlaubt, dassUPDATEandere, ähnliche Operationen (wie etwa ein anderesUPDATE) übernimmt, selbst dann nicht, wenn die beiden Operationen unterschiedliche Zeilen betreffen. Betrachten Sie das nächste Beispiel, das mit folgender Tabelle beginnt:CREATE TABLE A(A INT NOT NULL, B INT) ENGINE = InnoDB; INSERT INTO A VALUES (1,2),(2,3),(3,2),(4,3),(5,2); COMMIT;
Angenommen, ein Client führt folgende Anweisungen aus:
SET AUTOCOMMIT = 0; UPDATE A SET B = 5 WHERE B = 3;
Nehmen wir weiterhin an, dass danach ein anderer Client diese Anweisungen ausführt:
SET AUTOCOMMIT = 0; UPDATE A SET B = 4 WHERE B = 2;
In diesem Fall muss das zweite
UPDATEauf ein Commit oder Rollback des ersten warten. Das ersteUPDATEbesitzt eine exklusive Sperre auf Zeile (2,3) und das zweiteUPDATEversucht, während es die Zeilen scannt, für dieselbe Zeile ebenfalls eine Sperre zu erwerben, die es jedoch nicht bekommt. Das liegt daran, dass das zweiteUPDATEzuerst eine exklusive Sperre auf einer Zeile erwirbt und dann feststellt ob diese Zeile zur Ergebnismenge gehört. Wenn nicht, gibt es die überflüssige Sperre wieder frei, sofern die Variableinnodb_locks_unsafe_for_binlogeingeschaltet ist.Also führt
InnoDBdasUPDATENummer eins folgendermaßen aus:x-lock(1,2) unlock(1,2) x-lock(2,3) update(2,3) to (2,5) x-lock(3,2) unlock(3,2) x-lock(4,3) update(4,3) to (4,5) x-lock(5,2) unlock(5,2)
Das zweite
UPDATEführtInnoDBso aus:x-lock(1,2) update(1,2) to (1,4) x-lock(2,3) - wait for query one to commit or rollback
innodb_log_arch_dirDas Verzeichnis, in dem vollgeschriebene Logdateien archiviert werden, sofern die Archivierung von Logs eingeschaltet ist. Wenn ja, so sollte diese Variable auf denselben Wert wie
innodb_log_group_home_dirgesetzt werden. Das ist jedoch nicht obligatorisch.innodb_log_archiveGibt an, ob
InnoDB-Archivdateien protokolliert werden sollen. Diese Variable ist nur aus historischen Gründen noch vorhanden, wird aber nicht benutzt. Da MySQL die Backup-Recovery anhand seiner eigenen Logdateien durchführt, gibt es keinen Anlass,InnoDB-Logdateien zu archivieren. Die Variable hat den Standardwert 0.innodb_log_buffer_sizeGibt in Bytes die Größe des Puffers an, den
InnoDBbenutzt, um Logdateien auf die Platte zu schreiben. Werte von 1MB bis 8MB sind hier annehmbar. Der Standardwert ist 1MB. Wenn Sie einen großen Logpuffer haben, können umfangreiche Transaktionen zuende laufen, ohne dass das Log vor dem Committen auf die Festplatte zurückgeschrieben werden muss. In einer Umgebung mit großen Transaktionen können Sie also Festplattenzugriffe reduzieren, indem Sie den Logpuffer vergrößern.innodb_log_file_sizeDie Größe jeder Logdatei einer Loggruppe in Bytes. Die kombinierte Größe der Logdateien muss auf 32-Bit-Rechnren weniger als 4GB sein. Der Standard ist 5MB. Annehmbar sind Werte zwischen 1MB und 1/
N-tel der Größe des Bufferpools, wobeiNdie Anzahl der Dateien in einer Loggruppe ist. Je größer der Wert, umso weniger Checkpoint-Flushing ist im Bufferpool erforderlich, was wiederum Plattenzugriffe spart. Allerdings haben große Logdateien auch zur Folge, dass die Recovery nach einem Absturz langsamer läuft.innodb_log_files_in_groupDie Anzahl der Logdateien in der Loggruppe.
InnoDBbenutzt die Dateien in zirkulärer Weise. Der (empfehlenswerte) Standardwert ist 2.innodb_log_group_home_dirDer Verzeichnispfad zu den
InnoDB-Logdateien. Er muss denselben Wert haben wieinnodb_log_arch_dir. Wenn Sie keineInnoDB-Logvariablen angeben, werden nach Voreinstellung zwei 5MB große Dateien namensib_logfile0undib_logfile1im MySQL Data Directory angelegt.innodb_max_dirty_pages_pctEin Integer von 0 bis 100. Der Standardwert ist 90. Der Haupt-Thread in
InnoDBversucht, Seiten aus dem Bufferpool derart zu schreiben, dass der Prozentsatz von noch nicht geschriebenen Seiten diesen Wert nicht übersteigt.innodb_max_purge_lagDiese Variable gibt an, wie lange
INSERT-,UPDATE- undDELETE-Operationen aufgeschoben werden, wenn die Purge-Operationen hinterher hinken (siehe Abschnitt 14.2.12, „Implementierung der Multiversionierung“). Der Standardwert ist 0 (keine Verzögerungen).Das Transaktionssystem von
InnoDBpflegt eine Liste von Transaktionen, die Indexeinträge anhand vonUPDATE- oderDELETE-Operationen zum Löschen vorgemerkt haben. Die Länge dieser Liste seipurge_lag. Wennpurge_lagden Wertinnodb_max_purge_lagüberschreitet, wird jedeINSERT-,UPDATE- undDELETE-Operation um ((purge_lag/innodb_max_purge_lag)×10)–5 Millisekunden aufgeschoben. Diese Verzögerung wird alle zehn Sekunden am Anfang eines Purge-Batch berechnet. Die Operationen werden nicht aufgeschoben, wenn Purge nicht laufen kann, weil eine alte Consistent Read View die zu bereinigenden Zeilen sehen könnte.Eine typische Einstellung für eine problematische Arbeitslast wäre 1 Million, wenn die Transaktionen nur etwa 100 Bytes klein sind und wir 100MB unbereinigte Zeilen in unseren Tabellen gestatten können.
innodb_mirrored_log_groupsGibt an, wie viele identische Kopien von Loggruppen wir für die Datenbank bewahren. Zurzeit sollte dies auf 1 gesetzt werden.
innodb_open_filesDiese Variable ist nur dann von Belang, wenn Sie Multi-Tablespaces in
InnoDBbenutzen. Sie gibt an, wie viele.ibd-DateienInnoDBhöchstens gleichzeitig offen halten kann. Der Mindestwert ist 10 und der Standardwert 300.Die für
.ibd-Dateien verwendeten Dateideskriptoren sind ausschließlich fürInnoDBda. Sie haben nichts mit der Serveroption--open-files-limitzu tun und beeinflussen nicht die Arbeit des Tabellen-Caches.innodb_support_xaDie Einstellung
ONoder 1 (der Standard) schaltet dieInnoDB-Unterstützung für zweiphasigen Commit in XA-Transaktionen ein. Die Aktivierung voninnodb_support_xaverursacht eine zusätzliche Schreiboperation auf der Platte zur Vorbereitung der Transaktion. Wenn Sie sich für XA nicht interessieren, können Sie diese Variable mit der EinstellungOFFoder 0 deaktivieren, was die Schreibvorgänge auf der Festplatte reduziert und dieInnoDB-Performance erhöht.innodb_sync_spin_loopsGibt an, wie oft ein Thread auf die Freigabe eines
InnoDB-Mutex wartet, ehe er suspendiert wird.innodb_table_locksInnoDBbeachtetLOCK TABLES; MySQL kehrt vonLOCK TABLE .. WRITEerst zurück, wenn alle anderen Threads alle ihre Sperren auf der Tabelle freigegeben haben. Der Standardwert 1 bedeutet, dassLOCK TABLESInnoDBveranlasst, eine Tabelle intern zu sperren. In Anwendungen mitAUTOCOMMIT=1können die internen Tabellensperren vonInnoDBDeadlocks verursachen. Sie könneninnodb_table_locks=0in der Datei der Serveroptionen einstellen, um dieses Problem zu beheben.innodb_thread_concurrencyInnoDBversucht, die Anzahl der nebenläufigen Betriebssystem-Threads innerhalb vonInnoDBkleiner oder gleich dem in dieser Variablen festgelegten Höchstwert zu halten. Wenn Sie Performance-Probleme haben undSHOW ENGINE INNODB STATUSzeigt, dass viele Threads auf Semaphoren warten, haben Sie es vielleicht mit Thread-„Überlastung“ zu tun. In diesem Fall setzen sie diese Variable herunter oder herauf. Wenn Ihr Computer über viele Prozessoren und Festplatten verfügt, können Sie diesen Wert heraufsetzen, um Ihre Ressourcen besser auszunutzen. Ein empfehlenswerter Wert ist die Summe der Prozessoren und Festplatten, über die Ihr System verfügt. Beträgt der Wert 500 oder mehr, wird die Nebenläufigkeitsprüfung deaktiviert. Der Standardwert ist 20 und die Nebenläufigkeitsprüfung wird deaktiviert, wenn er auf größer oder gleich 20 eingestellt wird.innodb_thread_sleep_delayGibt in Mikrosekunden an, wie lange
InnoDB-Threads schlafen, bevor sie in dieInnoDB-Schlange eintreten. Der Standardwert ist 10.000. Der Wert 0 schaltet den Schlaf aus.sync_binlogHat diese Variable einen positiven Wert, synchronisiert der MySQL-Server sein Binärlog nach jedem
sync_binlogten Schreibvorgang mittelsfdatasync()auf die Festplatte. Im Autocommit-Modus entsteht pro Anweisung und ansonsten pro Transaktion ein Eintrag ins Binärlog. Der Standardwert 0 veranlasst keine Festplatten-Synchronisierung. Der Wert 1 ist am sichersten, da bei einem Absturz nur maximal eine Anweisung/Transaktion aus dem Binärlog verloren geht. Er ist aber auch am langsamsten (sofern nicht die Festplatte einen batteriegestützten Cache hat; dies würde die Synchronisierung sehr schnell machen).
Angenommen, Sie haben MySQL installiert und die notwendigen
Konfigurationsparameter für InnoDB in die
Konfigurationsdatei geschrieben. Bevor Sie MySQL nun starten,
müssen Sie überprüfen, ob die Verzeichnisse vorhanden sind, die
Sie für InnoDB-Daten- und Logdateien angegeben
haben, und ob der MySQL-Server Zugriffsrechte für diese
Verzeichnisse hat. InnoDB legt keine
Verzeichnisse, sondern nur Dateien an. Prüfen Sie außerdem, ob
Sie genug Platz auf der Festplatte haben, um die Daten- und
Logdateien zu speichern.
Wenn Sie Ihren MySQL-Server mit eingeschaltetem
InnoDB starten, führen Sie
mysqld am besten auf der Kommandozeile und
nicht mit dem Wrapper mysqld_safe oder als
Windows-Dienst aus. Dann können Sie nämlich die Ausgabe von
mysqld sehen und erkennen, was passiert. Auf
Unix rufen Sie einfach nur mysqld auf und auf
Windows verwenden Sie dafür die
--console-Option.
Wenn Sie MySQL-Server zum ersten Mal starten, nachdem Sie
InnoDB in Ihrer Optionsdatei konfiguriert
haben, erzeugt InnoDB Ihre Daten- und
Logdateien und gibt in etwa folgendes aus:
InnoDB: The first specified datafile /home/heikki/data/ibdata1 did not exist: InnoDB: a new database to be created! InnoDB: Setting file /home/heikki/data/ibdata1 size to 134217728 InnoDB: Database physically writes the file full: wait... InnoDB: datafile /home/heikki/data/ibdata2 did not exist: new to be created InnoDB: Setting file /home/heikki/data/ibdata2 size to 262144000 InnoDB: Database physically writes the file full: wait... InnoDB: Log file /home/heikki/data/logs/ib_logfile0 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile0 size to 5242880 InnoDB: Log file /home/heikki/data/logs/ib_logfile1 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile1 size to 5242880 InnoDB: Doublewrite buffer not found: creating new InnoDB: Doublewrite buffer created InnoDB: Creating foreign key constraint system tables InnoDB: Foreign key constraint system tables created InnoDB: Started mysqld: ready for connections
Jetzt hat InnoDB seinen Tablespace und seine
Logdateien initialisiert. Sie können mit dem MySQL-Server über
die üblichen MySQL-Clientprogramme wie mysql
Verbindung aufnehmen. Wenn Sie den MySQL-Server mit
mysqladmin shutdown herunterfahren, wird
folgendes ausgegeben:
010321 18:33:34 mysqld: Normal shutdown 010321 18:33:34 mysqld: Shutdown Complete InnoDB: Starting shutdown... InnoDB: Shutdown completed
Sie können die Datendatei und Logverzeichnisse anschauen und die
darin erstellten Dateien erkennen. Das Logverzeichnis enthält
außerdem eine kleine Datei namens
ib_arch_log_0000000000, die infolge der
Datenbankerstellung entstanden ist, nachdem
InnoDB die Logarchivierung abgeschaltet hat.
Wenn MySQL erneut gestartet wird, sind die Daten- und Logdateien
bereits vorhanden, sodass die Ausgabe viel knapper ausfällt:
InnoDB: Started mysqld: ready for connections
Wenn Sie die innodb_file_per_table-Option in
my.cnf hinzufügen, speichert
InnoDB jede Tabelle in einer eigenen
.ibd-Datei in demselben
MySQL-Datenbankverzeichnis, in dem auch die
.frm-Datei angelegt wurde. Siehe
Abschnitt 14.2.3.1, „Verwendung von Tabellen-Tablespaces (ein Tablespace pro Tabelle)“.
Wenn InnoDB während einer Dateioperation
einen Betriebssystemfehler ausgibt, hat das Problem in der Regel
eine der folgenden Ursachen:
Sie haben das
InnoDB-Datendatei- oder Logverzeichnis nicht angelegt.mysqld verfügt nicht über die notwendigen Berechtigungen, um Dateien in diesen Verzeichnissen anlegen zu können.
mysqld kann die richtige
my.cnf- odermy.ini-Optionsdatei nicht lesen und weiß deshalb nicht, welche Optionen Sie angegeben haben.Die Festplatte ist voll oder das Plattenkontingent überschritten.
Da Sie ein Unterverzeichnis angelegt haben, das genauso heißt wie die Datendatei, kann der Name nicht als Dateiname verwendet werden..
Ein Syntaxfehler hat sich in den Wert von
innodb_data_home_diroderinnodb_data_file_patheingeschlichen.
Wenn InnoDB beim Versuch scheitert, seinen
Tablespace oder seine Logdateien zu initialisieren, sollten Sie
alle von InnoDB erzeugten Dateien löschen.
Dazu gehören alle ibdata-Dateien und alle
ib_logfile-Dateien. Falls Sie bereits
InnoDB-Tabellen angelegt haben, müssen Sie
auch die .frm-Dateien (und, wenn Sie
Multi-Tablespaces benutzen, die
.ibd-Dateien) aus den
MySQL-Datenbankverzeichnissen löschen. Danach können Sie
erneut versuchen, die InnoDB-Datenbank
anzulegen. Am besten starten Sie den MySQL-Server von einer
Kommandozeile, um erkennen zu können, was geschieht.
Um eine InnoDB-Tabelle zu erzeugen, müssen Sie
die ENGINE = InnoDB-Option in der
CREATE TABLE-Anweisung angeben:
CREATE TABLE customers (a INT, b CHAR (20), INDEX (a)) ENGINE=InnoDB;
Der ältere Begriff TYPE wird als Synonym für
ENGINE aus Gründen der Abwärtskompatibilität
zwar weiter unterstützt, aber ENGINE ist der
bessere Begriff, während TYPE veraltet ist.
Die Anweisung erzeugt eine Tabelle und einen Index auf der Spalte
a im InnoDB-Tablespace, der
aus den in my.cnf angegebenen Datendateien
besteht. Außerdem legt MySQL die Datei
customers.frm im Verzeichnis
test an, das ein Unterverzeichnis des
MySQL-Datenbankverzeichnisses ist. Intern fügt
InnoDB in das Data Dictionary einen Eintrag
für diese Tabelle ein, der den Datenbanknamen enthält. Wenn
beispielsweise test die Datenbank ist, in der
die customers-Tabelle angelegt wurde, heißt
der Eintrag 'test/customers'. Das bedeutet,
dass Sie in einer anderen Datenbank eine gleichnamige
customers-Tabelle anlegen können, ohne dass es
in InnoDB zu Namenskonflikten kommt.
Wieviel Platz im InnoDB-Tablespace noch frei
ist, sagt Ihnen eine SHOW TABLE
STATUS-Anweisung für irgendeine
InnoDB-Tabelle. Der freie Platz im Tablespace
wird im Abschnitt Comment der Ausgabe von
SHOW TABLE STATUS angezeigt, beispielsweise:
SHOW TABLE STATUS FROM test LIKE 'customers'
Beachten Sie, dass die Statistikdaten, die SHOW
für InnoDB-Tabellen anzeigt, nur
Näherungswerte sind. Sie werden für die SQL-Optimierung
eingesetzt. Doch die reservierten Größen für Tabellen und
Indizes in Bytes werden präzise angegeben.
Standardmäßig startet jeder Client, der sich mit dem
MySQL-Server verbindet, mit eingeschaltetem Autocommit-Modus.
Das bedeutet, dass jede SQL-Anweisung direkt bei der Ausführung
automatisch in der Datenbank festgeschrieben wird. Um
Transaktionen zu verwenden, die aus mehreren Anweisungen
bestehen, schalten Sie Autocommit mit der SQL-Anweisung
SET AUTOCOMMIT = 0 aus und verwenden
COMMIT und ROLLBACK, um
Ihre Transaktionen zu committen oder zurückzurollen. Wenn Sie
Autocommit eingeschaltet lassen möchten, können Sie Ihre
Transaktionen zwischen START TRANSACTION und
entweder COMMIT oder
ROLLBACK einschließen. Das folgende Beispiel
zeigt zwei Transaktionen: Die erste wird committet und die
zweite zurückgerollt.
shell>mysql testmysql>CREATE TABLE CUSTOMER (A INT, B CHAR (20), INDEX (A))->ENGINE=InnoDB;Query OK, 0 rows affected (0.00 sec) mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO CUSTOMER VALUES (10, 'Heikki');Query OK, 1 row affected (0.00 sec) mysql>COMMIT;Query OK, 0 rows affected (0.00 sec) mysql>SET AUTOCOMMIT=0;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO CUSTOMER VALUES (15, 'John');Query OK, 1 row affected (0.00 sec) mysql>ROLLBACK;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM CUSTOMER;+------+--------+ | A | B | +------+--------+ | 10 | Heikki | +------+--------+ 1 row in set (0.00 sec) mysql>
In APIs wie PHP, Perl DBI, JDBC, ODBC oder der
Standardschnittstelle für C-Aufrufe von MySQL können Sie
Anweisungen zur Transaktionssteuerung wie etwa
COMMIT wie alle anderen SQL-Anweisungen,
beispielsweise SELECT oder
INSERT, als Strings an den MySQL-Server
senden. Manche APIs bieten auch eigene, spezielle
Transaktionsfunktionen oder -methoden für Commit und Rollback.
Wichtig: Bitte konvertieren Sie keine Systemtabellen von MySQL
in der mysql-Datenbank (wie etwa
user oder host) in den Typ
InnoDB. Diese Operation wird nicht
unterstützt. Die Systemtabellen müssen immer den Typ
MyISAM haben.
Wenn Sie alle Tabellen (außer den Systemtabellen) als
InnoDB-Tabellen anlegen möchten, fügen Sie
einfach die Zeile
default-storage-engine=innodb in den
[mysqld]-Abschnitt Ihrer Serveroptionsdatei
ein.
InnoDB kennt im Gegensatz zu
MyISAM keine spezielle Optimierung für eine
separate Indexerstellung. Daher lohnt es sich nicht, zuerst die
Tabellen zu exportieren und importieren und danach die Indizes
anzulegen. Der schnellste Weg, eine Tabelle in
InnoDB zu ändern, besteht darin, die
Einfügeoperationen direkt auf der
InnoDB-Tabelle vorzunehmen. Verwenden Sie
also ALTER TABLE … ENGINE=INNODB oder
erzeugen Sie eine leere InnoDB-Tabelle mit
denselben Definitionen und fügen Sie darin die Zeilen mit
INSERT INTO … SELECT * FROM …
ein.
Wenn Sie UNIQUE-Constraints auf
Sekundärschlüsseln haben, können Sie einen Tabellenimport
beschleunigen, indem Sie die Eindeutigkeitsprüfungen während
der Importoperation vorübergehend abschalten:
SET UNIQUE_CHECKS=0;
... import operation ...
SET UNIQUE_CHECKS=1;
Bei großen Tabellen spart das eine Menge Festplattenzugriffe,
da InnoDB dann seinen Insert-Puffer nutzen
kann, um die Sekundärindexeinträge in einer Batch-Operation zu
schreiben.
Um eine bessere Kontrolle über den Einfügungsprozess zu haben, ist es manchmal besser, Daten einer großen Tabelle in Stücken einzufügen:
INSERT INTO newtable SELECT * FROM oldtable WHERE yourkey > something AND yourkey <= somethingelse;
Wenn alle Datensätze eingefügt wurden, können Sie die Tabellen umbenennen.
Während der Konvertierung großer Tabellen sollten Sie den
InnoDB-Bufferpool vergrößern, damit weniger
Plattenzugriffe erforderlich sind. Reservieren Sie jedoch nicht
mehr als 80% des physikalischen Arbeitsspeichers. Sie können
auch die InnoDB-Logdateien vergrößern.
Achten Sie darauf, dass der Tablespace nicht vollläuft:
InnoDB-Tabellen brauchen auf der Festplatte
viel mehr Speicherplatz als MyISAM-Tabellen.
Wenn einer ALTER TABLE-Operation der Platz
ausgeht, startet sie ein Rollback, und das kann Stunden dauern,
wenn es an die Festplatte gebunden ist. Bei Inserts nutzt
InnoDB den Insert-Puffer, um
Sekundärindexeinträge in Batches mit dem Index
zusammenzuführen. Das spart viele Schreiboperationen auf der
Festplatte. Da für den Rollback kein solcher Mechanismus
existiert, kann dieser 30-mal länger als die
Einfügeoperationen dauern.
Wenn ein Rollback-Prozess außer Kontrolle gerät und Sie keine
wertvollen Daten in Ihrer Datenbank haben, ist es manchmal
ratsam, den Datenbankprozess anzuhalten, anstatt Millionen von
Lese/Schreiboperationen auf der Festplatte abzuwarten. Den
gesamten Vorgang können Sie unter
Abschnitt 14.2.8.1, „Erzwingen einer InnoDB-Wiederherstellung (Recovery)“ nachlesen.
Wenn Sie eine AUTO_INCREMENT-Spalte für eine
InnoDB-Tabelle definieren, enthält der
Tabellen-Handle im InnoDB-Data Dictionary
einen speziellen Zähler namens Auto-Increment-Zähler, der zur
Zuweisung neuer Werte zu dieser Spalte benutzt wird. Dieser
Zähler wird nur im Arbeitsspeicher und nicht auf der Festplatte
gespeichert.
InnoDB initialisiert den
Auto-Increment-Zähler für eine Tabelle T,
die eine AUTO_INCREMENT-Spalte namens
ai_col enthält, wie folgt: Nach dem
Serverstart führt InnoDB für die erste
Einfügung in die Tabelle T das Äquivalent
folgender Anweisung aus:
SELECT MAX(ai_col) FROM T FOR UPDATE;
InnoDB inkrementiert den von der Anweisung
abgerufenen Wert um eins und weist ihn der Spalte und dem
Auto-Increment-Zähler für die Tabelle zu. Ist die Tabelle
leer, verwendet InnoDB den Wert
1. Wenn ein Benutzer eine SHOW TABLE
STATUS-Anweisung gibt, die Ausgabe für die Tabelle
T anzeigt, und der Auto-Increment-Zähler
noch nicht initialisiert wurde, nimmt InnoDB
die Initialisierung vor, inkrementiert aber nicht den Wert und
speichert ihn nicht für spätere Einfügeoperationen. Beachten
Sie, dass für diese Initialisierung eine normale
Schreiboperation mit exklusiver Sperre auf der Tabelle
ausgeführt wird und die Sperre bis zum Ende der Transaktion
aufrecht erhalten bleibt.
Genauso geht InnoDB vor, wenn ein
Auto-Increment-Zähler für eine neu erzeugte Tabelle
initialisiert wird.
Wenn ein Auto-Increment-Zähler initialisiert wurde und ein
Benutzer nicht ausdrücklich einen Wert für eine
AUTO_INCREMENT-Spalte angibt, inkrementiert
InnoDB den Zähler um eins und weist der
Spalte den neuen Wert zu. Wenn der Benutzer eine Zeile einfügt,
die den Spaltenwert explizit angibt, und dieser Wert größer
als der aktuelle Zähler ist, wird der Zähler auf den
angegebenen Spaltenwert gesetzt.
Eventuell treten in der Abfolge der Werte einer
AUTO_INCREMENT-Spalte Lücken auf, wenn Sie
Transaktionen zurückrollen, die Nummern mithilfe des Zählers
zugewiesen haben.
Wenn der Benutzer in einem INSERT den Wert
NULL oder 0 für die
AUTO_INCREMENT-Spalte angibt, behandelt
InnoDB die betreffende Zeile, als wäre
überhaupt kein Wert vorhanden, und generiert einen neuen Wert
für sie.
Das Verhalten des Auto-Increment-Mechanismus ist nicht definiert, wenn ein Benutzer der Spalte einen negativen Wert zuweist, oder wenn der Wert die größte Ganzzahl übersteigt, die in dem angegebenen Integertyp gespeichert werden kann.
InnoDB benutzt für den Zugriff auf den
Auto-Increment-Zähler eine spezielle
AUTO-INC-Tabellensperre, die bis zum Ende der
laufenden SQL-Anweisung (nicht der Transaktion) gehalten wird.
Die spezielle Strategie zum Aufheben der Sperre wurde
eingefügt, um die Nebenläufigkeit von Einfügeoperationen in
Tabellen mit AUTO_INCREMENT-Spalten zu
verbessern. Es können nicht zwei Transaktionen zugleich auf
derselben Tabelle eine AUTO-INC-Sperre
halten.
InnoDB nutzt den speicherresidenten
Auto-Increment-Zähler so lange, wie der Server läuft. Wird der
Server angehalten und neu gestartet, initialisiert
InnoDB den Zähler bei der ersten
INSERT-Operation auf der Tabelle neu, wie
oben bereits beschrieben.
InnoDB unterstützt die Tabellenoption
AUTO_INCREMENT =
in NCREATE TABLE und ALTER
TABLE-Anweisungen, um den Anfangswert des Zählers
einzustellen oder seinen laufenden Wert zu ändern. Die Wirkung
dieser Option wird durch einen Neustart des Servers aufgehoben,
und zwar aus Gründen, die bereits weiter oben dargestellt
wurden.
InnoDB unterstützt auch
Fremdschlüssel-Constraints, die in InnoDB
mit folgender Syntax definiert werden:
[CONSTRAINTsymbol] FOREIGN KEY [id] (index_col_name, ...) REFERENCEStbl_name(index_col_name, ...) [ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION}] [ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
Für Fremdschlüsseldefinitionen gelten folgende Bedingungen:
Beide Tabellen müssen
InnoDB-Tabellen sein und dürfen keineTEMPORARY-Tabellen sein.In der referenzierenden Tabelle muss ein Index bestehen, in dem die Fremdschlüsselspalten als erste Spalten in derselben Reihenfolge aufgeführt sind. Ein solcher Index wird automatisch auf der referenzierenden Tabelle angelegt, wenn er noch nicht existiert.
In der referenzierten Tabelle muss ein Index bestehen, in dem die referenzierten Spalten als erste Spalten in derselben Reihenfolge aufgeführt sind.
Index-Präfixe auf Fremdschlüsselspalten werden nicht unterstützt. Dies hat unter anderem zur Folge, dass
BLOB- undTEXT-Spalten nicht in einen Fremdschlüssel eingebunden werden können, da Indizes auf diesen Spalten immer ein Längenpräfix haben müssen.Wenn die
CONSTRAINT-Klausel verwendet wird, muss dersymbolsymbol-Wert in der ganzen Datenbank einzigartig sein. Ist die Klausel nicht angegeben, erstelltInnoDBden Namen automatisch.
InnoDB weist jede INSERT-
oder UPDATE-Operation zurück, die versucht,
einen Fremdschlüsselwert in einer Kindtabelle anzulegen, wenn
kein passender Schlüsselwert in der Elterntabelle vorhanden
ist. Was InnoDB mit einer
INSERT- oder
UPDATE-Operation anfängt, die versucht, in
der Elterntabelle einen Schlüsselwert zu ändern oder zu
löschen, zu dem in der Kindtabelle passende Zeilen vorhanden
sind, hängt davon ab, welche
Referenzaktion in den Teilklauseln
ON UPDATE und ON DELETE
der FOREIGN KEY-Klausel angegeben ist. Wenn
der Benutzer versucht, in der Elterntabelle eine Zeile zu
ändern oder zu löschen, zu der in der Kindtabelle eine oder
mehr passende Zeilen vorhanden sind, bietet
InnoDB fünf mögliche Optionen:
CASCADE: Bei Löschung/Änderung einer Zeile der Elterntabelle werden automatisch die zugehörigen Zeilen der Kindtabelle auch gelöscht oder geändert. Es gibt sowohlON DELETE CASCADEals auchON UPDATE CASCADE. Zwischen zwei Tabellen sollten Sie bitte nicht mehrereON UPDATE CASCADE-Klauseln definieren, die auf derselben Spalte der Eltern- oder Kindtabelle arbeiten.SET NULL: Bei Löschung/Änderung einer Zeile der Elterntabelle werden automatisch die zugehörigen Fremdschlüsselspalten der Kindtabelle aufNULLgesetzt. Das gilt nur, wenn die Fremdschlüsselspalten nicht alsNOT NULLdefiniert sind. SowohlON DELETE SET NULLals auchON UPDATE SET NULLwird unterstützt.NO ACTION: Im Standard-SQL bedeutetNO ACTIONtatsächlich keine Aktion in dem Sinne, dass jeder Versuch, einen Primärschlüssel zu löschen oder zu ändern, unterbunden wird, wenn es dazu einen Fremschlüsselwert in der referenzierten Tabelle gibt.InnoDBweist dann die Lösch- oder Änderungsoperation auf der Elterntabelle zurück.RESTRICTweist die Lösch- oder Änderungsoperation auf der Elterntabelle zurück.NO ACTIONundRESTRICTsind dasselbe wie ein Auslassen derON DELETE- oderON UPDATE-Klausel. (Manche Datenbanksysteme kennen verzögerte Prüfungen (deferred checks), zu denen auchNO ACTIONgehört. Da in MySQL Fremdschlüssel-Constraints jedoch sofort geprüft werden, sindNO ACTIONundRESTRICThier dasselbe.)SET DEFAULT: Diese Aktion wird zwar vom Parser anerkannt, aberInnoDBweist Tabellendefinitionen mitON DELETE SET DEFAULT- oderON UPDATE SET DEFAULT-Klauseln zurück.
Beachten Sie, dass InnoDB
Fremdschlüsselreferenzen in einer Tabelle unterstützt. In
solchen Fällen sind „Datensätze der Kindtabelle“
in Wirklichkeit abhängige Datensätze in derselben Tabelle.
Da InnoDB Indizes auf Fremdschlüsseln und
referenzierten Schlüsseln verlangt, können
Fremdschlüsselprüfungen schnell durchgeführt werden und
erfordern keinen Tabellen-Scan. Der Index auf den
Fremdschlüsseln wird automatisch angelegt. Das war in manchen
älteren Versionen anders, wo Indizes explizit angelegt werden
mussten, da sonst keine Fremdschlüssel-Constraints angelegt
werden konnten.
Zusammengehörige Spalten im Fremdschlüssel und referenzierten
Schlüssel müssen in InnoDB ähnliche
Datentypen haben, damit sie sich ohne Typkonvertierung
vergleichen lassen. Die Größe und das Vorzeichen von
Integer-Typen müssen gleich sein. Die Länge von
String-Typen muss nicht unbedingt identisch sein. Wenn Sie
SET NULL verlangen, dürfen die
Spalten der Kindtabelle nicht als NOT NULL
deklariert sein.
Wenn MySQL die Fehlernummer 1005 aus einer CREATE
TABLE-Anweisung meldet und die Fehlermeldung sich auf
Fehlernummer 150 bezieht, schlug die Tabellenerstellung fehl,
weil ein Fremdschlüssel-Constraint nicht wohlgeformt war. Wenn
ein ALTER TABLE scheitert und auf
Fehlernummer 150 verweist, bedeutet dies, dass eine
Fremdschlüsseldefinition für die geänderte Tabelle nicht
korrekt war. Die Anweisung SHOW ENGINE INNODB
STATUS zeigt eine detaillierte Erklärung des letzten
InnoDB-Fremdschlüsselfehlers im Server an.
Hinweis:
InnoDB prüft Fremdschlüssel-Constraints
nicht auf Fremdschlüsseln oder referenzierten Schlüsseln, die
eine NULL-Spalte enthalten.
Hinweis: Trigger werden von kaskadierenden Fremdschlüsselaktionen derzeit nicht aktiviert.
Abweichung von SQL-Standards:
Wenn mehrere Zeilen in der Elterntabelle denselben
Referenzschlüsselwert haben verhält sich
InnoDB bei Fremdschlüsselprüfungen so, als
würden die anderen Zeilen der Elterntabelle, also die mit
demselben Schlüsselwert, gar nicht vorhanden. Wenn Sie
beispielsweise einen RESTRICT-Typ-Constraint
definiert haben und es eine Kindzeile mit mehreren Elternzeilen
gibt, verbietet InnoDB das Löschen
irgendeiner dieser Elternzeilen.
InnoDB führt kaskadierende Operationen mit
einem Depth-First-Algorithmus durch, beruhend auf Einträgen in
den Indizes, die zu den Fremdschlüssel-Constraints gehören.
Abweichung von SQL-Standards:
Ein FOREIGN KEY-Constraint, der einen
Nicht-UNIQUE-Schlüssel referenziert, ist
nicht Standard-SQL, sondern eine
InnoDB-Erweiterung dieses Standards.
Abweichung von SQL-Standards:
Wenn ON UPDATE CASCADE oder ON
UPDATE SET NULL rekursiv dieselbe
Tabelle ändert, die zuvor während der
kaskadierenden Änderung auch bereits aktualisiert wurde,
verhält es sich wie RESTRICT. Sie können
also keine rückbezüglichen ON UPDATE
CASCADE- oder ON UPDATE SET
NULL-Operationen ausführen. Dadurch sollen
Endlosschleifen wegen kaskadierender Updates verhindert werden.
Andererseits ist ein rückbezügliches ON DELETE SET
NULL jedoch möglich, nämlich als rückbezügliches
ON DELETE CASCADE. Die maximale
Schachtelungstiefe von kaskadierenden Operationen beträgt 15
Ebenen.
Abweichung von SQL-Standards:
Wie immer in MySQL prüft InnoDB für jede
SQL-Anweisung, die viele Zeilen einfügt, löscht oder ändert,
die UNIQUE- und FOREIGN
KEY-Constraints zeilenweise. Nach dem SQL-Standard
sollte eigentlich eine verzögerte Prüfung vorgenommen werden,
bei der Constraints erst nach der Verarbeitung der
gesamten SQL-Anweisung geprüft werden. Bis die
verzögerte Constraint-Prüfung auch in
InnoDB implementiert ist, werden einige Dinge
nicht möglich sein, etwa das Löschen eines Datensatzes, der
sich über einen Fremdschlüssel auf sich selbst bezieht.
In dem folgenden einfachen Beispiel sind
parent- und child-Tabellen
über einen Einzelspalten-Fremdschlüssel verbunden:
CREATE TABLE parent (id INT NOT NULL,
PRIMARY KEY (id)
) ENGINE=INNODB;
CREATE TABLE child (id INT, parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id) REFERENCES parent(id)
ON DELETE CASCADE
) ENGINE=INNODB;
Das folgende, komplexere Beispiel zeigt eine
product_order-Tabelle, die Fremdschlüssel
für zwei andere Tabellen besitzt. Ein Fremdschlüssel
referenziert einen Zwei-Spalten-Index in der
product-Tabelle und der andere einen
Ein-Spalten-Index in der customer-Tabelle:
CREATE TABLE product (category INT NOT NULL, id INT NOT NULL,
price DECIMAL,
PRIMARY KEY(category, id)) ENGINE=INNODB;
CREATE TABLE customer (id INT NOT NULL,
PRIMARY KEY (id)) ENGINE=INNODB;
CREATE TABLE product_order (no INT NOT NULL AUTO_INCREMENT,
product_category INT NOT NULL,
product_id INT NOT NULL,
customer_id INT NOT NULL,
PRIMARY KEY(no),
INDEX (product_category, product_id),
FOREIGN KEY (product_category, product_id)
REFERENCES product(category, id)
ON UPDATE CASCADE ON DELETE RESTRICT,
INDEX (customer_id),
FOREIGN KEY (customer_id)
REFERENCES customer(id)) ENGINE=INNODB;
InnoDB ermöglicht es, mit ALTER
TABLE einer Tabelle einen Fremdschlüssel-Constraint
hinzuzufügen:
ALTER TABLEtbl_nameADD [CONSTRAINTsymbol] FOREIGN KEY [id] (index_col_name, ...) REFERENCEStbl_name(index_col_name, ...) [ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION}] [ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
Bitte legen Sie immer zuerst die
erforderlichen Indizes an. Sie können einer Tabelle
mit ALTER TABLE auch einen rückbezüglichen
Fremdschlüssel-Constraint hinzufügen.
InnoDB ermöglicht es überdies, mit
ALTER TABLE Fremdschlüssel zu löschen:
ALTER TABLEtbl_nameDROP FOREIGN KEYfk_symbol;
Wenn die FOREIGN KEY-Klausel bei der
Erzeugung des Fremdschlüssels einen
CONSTRAINT-Namen enthielt, können Sie beim
Löschen dieses Fremdschlüssels denselben Namen nennen.
Ansonsten wird beim Anlegen des Fremdschlüssels intern ein
fk_symbol-Wert generiert. Um zum
Löschen eines Fremdschlüssels diesen Symbolwert zu ermitteln,
dient die SHOW CREATE TABLE-Anweisung. Ein
Beispiel:
mysql>SHOW CREATE TABLE ibtest11c\G*************************** 1. row *************************** Table: ibtest11c Create Table: CREATE TABLE `ibtest11c` ( `A` int(11) NOT NULL auto_increment, `D` int(11) NOT NULL default '0', `B` varchar(200) NOT NULL default '', `C` varchar(175) default NULL, PRIMARY KEY (`A`,`D`,`B`), KEY `B` (`B`,`C`), KEY `C` (`C`), CONSTRAINT `0_38775` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11a` (`A`, `D`) ON DELETE CASCADE ON UPDATE CASCADE, CONSTRAINT `0_38776` FOREIGN KEY (`B`, `C`) REFERENCES `ibtest11a` (`B`, `C`) ON DELETE CASCADE ON UPDATE CASCADE ) ENGINE=INNODB CHARSET=latin1 1 row in set (0.01 sec) mysql>ALTER TABLE ibtest11c DROP FOREIGN KEY `0_38775`;
Sie können einen Fremdschlüssel nicht in separaten Klauseln
derselben ALTER TABLE-Anweisung anlegen und
löschen. Hierzu sind zwei getrennte Anweisungen erforderlich.
Der Parser von InnoDB gestattet es, für
Tabellen- und Spaltenbezeichner in einer FOREIGN KEY
… REFERENCES …-Klausel Backticks als
Anführungszeichen zu verwenden. (Alternativ können doppelte
Anführungszeichen gesetzt werden, wenn der SQL-Modus
ANSI_QUOTES SQL eingeschaltet ist.) Außerdem
berücksichtigt der InnoDB-Parser die
Einstellung der Systemvariablen
lower_case_table_names.
InnoDB gibt die Fremdschlüsseldefinitionen
einer Tabelle im Rahmen der SHOW CREATE
TABLE-Anweisung zurück:
SHOW CREATE TABLE tbl_name;
mysqldump erstellt ebenfalls die korrekten Definitionen der Tabellen in der Dump-Datei und vergisst dabei auch die Fremdschlüssel nicht.
Die Fremdschlüssel-Constraints einer Tabelle können wie folgt angezeigt werden:
SHOW TABLE STATUS FROMdb_nameLIKE 'tbl_name';
Die Fremdschlüssel-Constraints stehen in der
Comment-Spalte der Ausgabe.
Bei den Fremdschlüsselprüfungen errichtet
InnoDB Shared-Sperren auf Zeilenebene auf den
relevanten Datensätzen der Kind- oder Elterntabellen.
InnoDB prüft die Fremdschlüssel-Constraints
sofort und nicht erst beim Committen der Transaktion.
Damit Dump-Dateien, die Fremdschlüsselbeziehungen haben,
leichter geladen werden können bindet
mysqldump automatisch in die Dump-Ausgabe
eine Anweisung ein, die FOREIGN_KEY_CHECKS
auf 0 setzt. So entstehen keine Probleme mit Tabellen, die beim
Neuladen der Dump-Dateien eigentlich in einer bestimmten
Reihenfolge geladen werden müssen. Diese Variable kann auch
manuell gesetzt werden:
mysql>SET FOREIGN_KEY_CHECKS = 0;mysql>SOURCEmysql>dump_file_name;SET FOREIGN_KEY_CHECKS = 1;
So können Sie die Tabellen in beliebiger Reihenfolge
importieren, wenn die Dump-Datei Tabellen enthält, die
eigentlich gemäß ihrer Fremdschlüssel nicht richtig geordnet
sind. Außerdem wird der Import beschleunigt. Auch in Fällen,
wo Sie Fremdschlüssel-Constraints in LOAD
DATA- und ALTER TABLE-Operationen
ignorieren möchten, kann es sinnvoll sein,
FOREIGN_KEY_CHECKS auf 0 zu setzen.
Mit InnoDB können Sie eine durch einen
FOREIGN KEY-Constraint referenzierte Tabelle
nur löschen, wenn SET FOREIGN_KEY_CHECKS=0
eingestellt wurde. Wenn Sie eine Tabelle löschen, werden die in
ihrer Erzeugungsanweisung definierten Constraints mit gelöscht.
Wenn Sie eine gelöschte Tabelle wiederherstellen, muss ihre Definition zu den auf sie bezogenen Fremdschlüssel-Constraints passen. Sie muss die richtigen Spaltennamen und -typen sowie Indizes auf den referenzierten Schlüsseln haben. Ist dies nicht der Fall, gibt MySQL die Fehlernummer 1005 zurück und nennt die Fehlernummer 150 in der Fehlermeldung.
In MySQL funktioniert die Replikation mit
InnoDB-Tabellen wie mit
MyISAM-Tabellen. Es sind auch
Replikationsumgebungen möglich, bei denen der Slave eine andere
Speicher-Engine als der Master verwendet. So können Sie
beispielsweise Änderungen, die auf dem Master an einer
InnoDB-Tabelle vorgenommen werden, in einer
MyISAM-Tabelle auf dem Slave replizieren.
Um einen neuen Slave für den Master einzurichten, müssen Sie
den InnoDB-Tablespace und die Logdateien
sowie die .frm-Dateien der
InnoDB-Tabellen kopieren und diese Kopien auf
den Slave übertragen. Wenn die Variable
innodb_file_per_table eingeschaltet ist,
müssen auch die .ibd-Dateien kopiert
werden. Wie dies genau geht, erfahren Sie unter
Abschnitt 14.2.8, „Sichern und Wiederherstellen einer InnoDB-Datenbank“.
Wenn Sie den Master oder einen vorhandenen Slave herunterfahren,
können Sie ein kaltes Backup des
InnoDB-Tablespace und der Logdateien
erstellen und damit einen Slave einrichten. Um einen neuen Slave
aufzusetzen, ohne gleich den Server herunterzufahren, können
Sie das kommerzielle (also kostenpflichtige) Tool
InnoDB
Hot Backup verwenden.
Die InnoDB-Replikation wird mit der
LOAD TABLE FROM MASTER-Anweisung
eingerichtet, die allerdings nur mit
MyISAM-Tabellen funktioniert. Dafür gibt es
jedoch zwei Workarounds:
Sie können einen Tabellen-Dump auf dem Master vornehmen und die Dump-Datei in den Slave importieren.
Sie können auf dem Master
ALTER TABLEeinstellen, bevor Sie die Replikation mittbl_nameENGINE=MyISAMLOAD TABLEstarten, und danach die Master-Tabelle mittbl_nameFROM MASTERALTER TABLEwieder inInnoDBkonvertieren. Tun Sie das aber nicht mit Tabellen, die Fremdschlüsseldefinitionen haben, da diese Definitionen sonst verlorengehen.
Transaktionen, die auf dem Master scheitern, haben auf die
Replikation keinerlei Auswirkungen. Die Replikation beruht in
MySQL auf dem Binärlog, wo die SQL-Anweisungen, die Daten
modifizieren, festgehalten werden. Eine Transaktion, die
scheitert (beispielsweise wegen Verstoß gegen einen
Fremdschlüssel-Constraint oder weil sie zurückgerollt wird),
gelangt gar nicht ins Binärlog und ergo auch nicht auf die
Slaves. Siehe Abschnitt 13.4.1, „BEGIN/COMMIT/ROLLBACK“.
Dieser Abschnitt beschreibt, was Sie tun können, wenn Ihr
InnoDB-Tablespace nicht mehr genug Platz hat
oder Sie die Größe der Logdateien ändern möchten.
Am einfachsten lässt sich der
InnoDB-Tablespace vergrößern, wenn er von
Anfang an als selbsterweiternd konfiguriert wird. Hierzu geben Sie
das autoextend-Attribut für die letzte
Datendatei in der Tablespace-Definition an. Dann lässt
InnoDB diese Datei automatisch in Inkrementen
von 8MB anwachsen, wenn ihr der Platz ausgeht. Die
Inkrement-Größe kann mit der Systemvariablen
innodb_autoextend_increment in MB eingestellt
werden.
Sie können Ihren Tablespace jedoch auch vergrößern, indem Sie
eine weitere Datendatei hinzufügen. Hierzu müssen sie den
MySQL-Server herunterfahren, der Tablespace-Konfiguration am Ende
von innodb_data_file_path eine neue Datendatei
hinzufügen, und den Server wieder neu starten.
Wenn die letzte Datendatei mit dem Schlüsselwort
autoextend definiert worden ist, müssen Sie
bei der Rekonfiguration des Tablespaces berücksichtigen, auf
welches Maß diese letzte Datendatei angewachsen ist. Ermitteln
Sie die Größe der Datendatei, runden Sie sie auf das nächste
Vielfache von 1024 × 1024 bytes (= 1MB) ab und geben Sie
diesen gerundeten Wert explizit in
innodb_data_file_path an. Dann können Sie eine
weitere Datendatei hinzufügen. Denken Sie daran, dass Sie nur die
letzte Datendatei in innodb_data_file_path als
selbsterweiternd definieren können.
Nehmen wir beispielsweise an, der Tablespace hat nur eine
selbsterweiternde Datendatei namens ibdata1:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:10M:autoextend
Diese Datei sei nun mit der Zeit auf 988MB angewachsen. Hier sehen Sie die Konfigurationszeile, nachdem die ursprüngliche Datendatei als nicht mehr selbsterweitend definiert und eine neue, selbsterweiternde Datendatei hinzugefügt wurde:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
Wenn Sie der Tablespace-Konfiguration eine neue Datei hinzufügen,
achten Sie darauf, dass diese noch nicht existiert.
InnoDB wird die Datei erzeugen und
initialisieren, wenn der Server neu gestartet wird.
Gegenwärtig ist es nicht möglich, eine Datendatei aus dem Tablespace zu löschen. Wenn Sie Ihren Tablespace verkleinern möchten, gehen Sie folgendermaßen vor:
Mit mysqldump erstellen Sie einen Dump aller
InnoDB-Tabellen.Halten Sie den Server an.
Löschen Sie alle vorhandenen Tablespace-Dateien.
Konfigurieren Sie einen neuen Tablespace.
Starten Sie den Server neu.
Importieren Sie die Dump-Dateien.
Wenn Sie die Anzahl oder Größe Ihrer
InnoDB-Logdateien ändern möchten, halten Sie
den MySQL-Server an und achten darauf, dass er ohne Fehler
herunterfährt (um zu gewährleisten, dass in den Logs keine Daten
unvollendeter Transaktionen hängen bleiben). Dann kopieren Sie
die Logdateien an einen sicheren Ort, nur für den Fall, dass beim
Herunterfahren etwas schiefgeht und Sie den Tablespace
wiederherstellen müssen. Löschen Sie die alten Logdateien aus
dem Logdateiverzeichnis, ändern Sie die Logdateikonfiguration in
my.cnf und starten Sie den MySQL-Server neu.
mysqld erkennt beim Hochfahren, dass keine
Logdateien vorhanden sind, und teilt Ihnen mit, dass neue angelegt
werden.
Der Schlüssel zu einem sicheren Datenbankmanagement sind regelmäßige Backups.
InnoDB Hot Backup ist ein Online-Backup-Tool
mit dem Sie eine InnoDB-Datenbank bei laufendem
Betrieb sichern können. InnoDB Hot Backup
verlangt nicht, dass Sie die Datenbank herunterfahren, setzt keine
Sperren und stört nicht die normale Datenbankverarbeitung.
InnoDB Hot Backup ist ein kostenpflichtiges
(kommerzielles) Add-on, das pro Jahr und pro MySQL-Server-Computer
€390 kostet. Genauere Informationen und Screenshots finden
Sie unter
InnoDB Hot
Backup home page.
Wenn Sie in der Lage sind, Ihren MySQL-Server herunterzufahren,
können Sie auch ein Binär-Backup aller Dateien erstellen, die
InnoDB zur Verwaltung seiner Tabellen
benötigt. Gehen Sie folgendermaßen vor:
Fahren Sie den MySQL-Server herunter und achten Sie darauf, dass dabei keine Fehler auftreten.
Kopieren Sie alle Datendateien (
ibdata-Dateien und.ibd-Dateien) an einen sicheren Ort.Kopieren Sie alle
ib_logfile-Dateien an einen sicheren Ort.Kopieren Sie Ihre
my.cnf-Konfigurationsdatei(en) an einen sicheren Ort.Kopieren Sie alle
.frm-Dateien für IhreInnoDB-Tabellen an einen sicheren Ort.
Da die Replikation mit InnoDB-Tabellen
funktioniert, können Sie die Replikationsfähigkeiten von MySQL
nutzen, um in Hochverfügbarkeitsumgebungen eine Kopie Ihrer
Datenbank zu halten.
Zusätzlich zu den Binär-Backups sollten Sie auch regelmäßig
mit mysqldump Dump-Kopien der Tabellen anlegen,
da eine Binärdatei beschädigt werden kann, ohne dass man es
merkt. Dump-Dateien hingegen werde in Textdateien gespeichert, die
für Menschen lesbar sind. So lassen sich Schäden leichter
erkennen. Außerdem ist die Gefahr einer ernsten Datenkorruption
geringer, da das Format einfacher ist.
mysqldump besitzt zudem die
--single-transaction-Option, mit der Sie
konsistente Snapshots anlegen können, ohne andere Clients
auszusperren.
Um überhaupt in der Lage zu sein, eine
InnoDB-Datenbank aus dem Binär-Backup
wiederherzustellen, müssen Sie den MySQL-Server mit
eingeschaltetem Binär-Logging betreiben. Dann können Sie das
Binärlog auf die Datenbanksicherung übertragen, um eine
Point-in-Time-Recovery zu fahren:
mysqlbinlog yourhostname-bin.123 | mysql
Um den MySQL-Server nach einem Absturz wiederherzustellen, müssen
Sie ihn lediglich neu starten. InnoDB schaut
automatisch in die Logs und versetzt die Datenbank wieder in den
aktuellen Zustand (Roll-forward). InnoDB rollt
unbestätigte Transaktionen, die zum Zeitpunkt des Absturzes
anhängig waren, automatisch zurück. Während der
Wiederherstellung zeigt mysqld so etwas wie
dieses an:
InnoDB: Database was not shut down normally. InnoDB: Starting recovery from log files... InnoDB: Starting log scan based on checkpoint at InnoDB: log sequence number 0 13674004 InnoDB: Doing recovery: scanned up to log sequence number 0 13739520 InnoDB: Doing recovery: scanned up to log sequence number 0 13805056 InnoDB: Doing recovery: scanned up to log sequence number 0 13870592 InnoDB: Doing recovery: scanned up to log sequence number 0 13936128 ... InnoDB: Doing recovery: scanned up to log sequence number 0 20555264 InnoDB: Doing recovery: scanned up to log sequence number 0 20620800 InnoDB: Doing recovery: scanned up to log sequence number 0 20664692 InnoDB: 1 uncommitted transaction(s) which must be rolled back InnoDB: Starting rollback of uncommitted transactions InnoDB: Rolling back trx no 16745 InnoDB: Rolling back of trx no 16745 completed InnoDB: Rollback of uncommitted transactions completed InnoDB: Starting an apply batch of log records to the database... InnoDB: Apply batch completed InnoDB: Started mysqld: ready for connections
Wenn Ihre Datenbank beschädigt wurde oder Ihre Festplatte abstürzt, müssen Sie ein Backup zur Wiederherstellung verwenden. Sind Schäden aufgetreten, müssen Sie ein Backup suchen, das unbeschädigt ist. Nach der Wiederherstellung der Sicherungsdateien aus dem Backup müssen Sie mit mysqlbinlog und mysql die Änderungen, die nach dem Backup eingetreten sind, aus den Binärlogs anwenden.
In manchen Fällen, in denen Daten beschädigt wurden, reicht es
aus, die beschädigten Tabellen zu dumpen, zu löschen und neu zu
erzeugen. Mit der SQL-Anweisung CHECK TABLE
finden Sie die meisten Schäden heraus, allerdings nicht jede nur
denkbare Art von Datenkorruption. Der
innodb_tablespace_monitor prüft die
Integrität des Dateiraum-Managements in den Tablespace-Dateien.
Manchmal ist ein scheinbarer Datenbankschaden in Wirklichkeit ein Schaden, den das Betriebssystem an seinem eigenen Datei-Cache verursacht hat, während die Daten auf der Festplatte nach wie vor in Ordnung sind. Am besten versuchen Sie als Erstes, den Computer neu zu starten. So können Sie Fehler eliminieren, die nur scheinbar einen Schaden an Datenbankseiten verursachten.
Wenn Schäden an Datenbankseiten vorhanden sind, sollten Sie
Ihre Tabellen mit SELECT INTO OUTFILE dumpen.
Normalerweise sind die meisten auf diese Weise geretteten Daten
intakt. Trotzdem kann der Schaden dazu führen, dass
SELECT * FROM
-Anweisungen oder
tbl_nameInnoDB-Hintergrundoperationen abstürzen oder
sich durchsetzen oder gar die Roll-forward-Recovery von
InnoDB abstürzen lassen. Sie können einen
Neustart von InnoDB erzwingen und
gleichzeitig die Hintergrundoperationen anhalten, sodass ein
Tabellen-Dump möglich ist. Zum Beispiel könnten Sie dem
Abschnitt [mysqld] Ihrer Optionsdatei vor dem
Server-Neustart folgende Zeile hinzufügen:
[mysqld] innodb_force_recovery = 4
Weiter unten erfahren Sie, welche von null verschiedenen Werte
innodb_force_recovery annehmen kann.
Größere Werte schließen alle Sicherheitsmaßnahmen der
kleineren Werte mit ein. Wenn Sie in der Lage sind, Ihre
Tabellen mit einem Optionswert von höchstens 4 zu dumpen,
können Sie davon ausgehen, dass nur wenige Daten auf einzelnen
beschädigten Seiten verloren gegangen sind. Der Wert 6 ist
schon drastischer: Hier bleiben Datenbankseiten in einem
obsoleten Zustand zurück, was zu zusätzlichen Schäden in
B-Bäumen und anderen Datenbankstrukturen führen kann.
1(SRV_FORCE_IGNORE_CORRUPT)Server soll auch dann weiter laufen, wenn er eine beschädigte Seite entdeckt. Versuchen Sie,
SELECT * FROMbeschädigte Indexeinträge und Seiten überspringen zu lassen, da dies den Tabellen-Dump erleichtert.tbl_name2(SRV_FORCE_NO_BACKGROUND)Unterbindet den Haupt-Thread. Wenn während der Purge-Operation ein Absturz passiert, wird dieser Recovery-Wert das verhindern.
3(SRV_FORCE_NO_TRX_UNDO)Nach der Recovery keine Transaktionen zurückrollen.
4(SRV_FORCE_NO_IBUF_MERGE)Verhindert auch Merge-Operationen auf Insert-Puffern. Wenn diese einen Absturz herbeiführen würden werden sie nicht durchgeführt. Es wird keine Tabellenstatistik berechnet.
5(SRV_FORCE_NO_UNDO_LOG_SCAN)Beim Starten der Datenbank nicht in die Undo-Logs schauen:
InnoDBbehandelt dann auch unvollständige Transaktionen als abgeschlossen.6(SRV_FORCE_NO_LOG_REDO)Keinen Roll-forward der Logs in Verbindung mit der Recovery durchführen.
Selbst bei einer erzwungenen Recovery können Sie Tabellen mit
SELECT dumpen oder sie mit
DROP löschen oder mit
CREATE anlegen. Wenn Sie wissen, dass eine
bestimmte Tabelle beim Zurückrollen einen Absturz verursacht,
können Sie sie löschen. Oder Sie verwenden diese Option, um
ein Rollback anzuhalten, das wegen eines gescheiterten
Massen-Imports oder einer fehlgeschlagenen ALTER
TABLE-Operation außer Kontrolle geraten ist. Sie
können den mysqld-Prozess anhalten und
innodb_force_recovery auf
3 setzen, um die Datenbank ohne den Rollback
wieder ans Laufen zu bringen, und dann mit
DROP die Tabelle löschen, die den
Endlos-Rollback verursacht hatte.
Die Datenbank darf auf keine andere Weise mit einem
von null verschiedenen
innodb_force_recovery-Wert benutzt
werden. Zur Sicherheit hindert
InnoDB die Benutzer an
INSERT-, UPDATE- und
DELETE-Operationen, wenn
innodb_force_recovery größer als 0 ist.
InnoDB implementiert einen
„fuzzy“ Checkpoint-Mechanismus.
InnoDB schreibt Datenbankseiten, die
geändert wurden, in kleinen Batches aus dem Bufferpool auf die
Platte. Es ist nicht nötig, den Bufferpool in einem einzigen,
großen Batch auf die Platte zu schreiben, da dies in der Praxis
dazu führen würde, dass Benutzer während des
Checkpointing-Prozesses keine SQL-Anweisungen erteilen können.
Bei einer Recovery sucht InnoDB ein
Checkpoint-Label in den Logdateien, da es weiß, dass alle
Datenbankmodifikationen, die diesem Label vorausgingen, im
Disk-Image der Datenbank vorhanden sind. Dann scannt
InnoDB die Logdateien von dem Checkpoint aus
nach vorne durch und wendet die dort protokollierten
Modifikationen auf die Datenbank an.
InnoDB schreibt Daten in rotierender Weise in
seine Logdateien. Alle committeten Modifikationen, die dazu
führen, dass Datenbankseiten im Bufferpool von den Images auf
der Festplatte abweichen, müssen in den Logdateien vorhanden
sein, falls InnoDB einmal eine Recovery
durchführen muss. Wenn InnoDB eine Logdatei
benutzt, muss es also dafür sorgen, dass die
Datenbankseiten-Images auf der Platte die in der für die
Recovery verwendeten Logdatei protokollierten Modifikationen
enthalten. Mit anderen Worten muss InnoDB
einen Checkpoint anlegen, wozu häufig modifizierte
Datenbankseiten auf die Platte zurückgeschrieben werden
müssen.
Dies erklärt auch, warum sehr große Logdateien die Plattenzugriffe beim Checkpointing reduzieren. Oft ist es sinnvoll, die Gesamtgröße der Logdateien auf die Größe des Bufferpools oder sogar einen noch höheren Wert einzustellen. Der Nachteil großer Logdateien: Die Recovery kann dann länger dauern, da mehr Informationen in die Datenbank eingebracht werden müssen.
Auf Windows speichert InnoDB die Namen von
Datenbanken und Tabellen intern immer in Kleinbuchstaben. Um
Datenbanken in einem Binärformat von Unix auf Windows oder von
Windows auf Unix zu verlagern, sollten Sie alle Tabellen- und
Datenbanknamen auf Kleinschrift umstellen. Dies können Sie ganz
bequem erreichen, indem Sie dem
[mysqld]-Abschnitt Ihrer
my.cnf- oder
my.ini-Datei folgende Zeile hinzufügen,
bevor Sie irgendwelche Datenbanken oder Tabellen erzeugen:
[mysqld] lower_case_table_names=1
Wie MyISAM-Datendateien sind auch die Daten-
und Logdateien von InnoDB auf allen
Plattformen, die dasselbe Fließkommazahlenformat haben, binär
kompatibel. Sie können eine InnoDB-Datenbank
einfach verschieben, indem Sie alle in
Abschnitt 14.2.8, „Sichern und Wiederherstellen einer InnoDB-Datenbank“ aufgelisteten relevanten Dateien
kopieren. Wenn die Fließkommaformate unterschiedlich sind, aber
keine FLOAT- oder
DOUBLE-Datentypen in den Tabellen verwendet
werden, ist die Prozedur dieselbe: Kopieren Sie einfach die
relevanten Dateien. Sind aber sowohl die Formate unterschiedlich,
als auch Fließkommawerte in den Tabellen vorhanden, so müssen
Sie Ihre Tabellen mit mysqldump auf der einen
Maschine dumpen und dann diese Dump-Dateien auf die andere
Maschine übertragen.
Eine bessere Performance erzielen Sie, wenn Sie den Autocommit-Modus beim Datenimport abschalten, immer vorausgesetzt, der Tablespace hat genug Platz für das große Rollback-Segment, das Import-Transaktionen generieren. Den Commit-Befehl geben Sie nachträglich, wenn Sie eine Tabelle oder ein Tabellensegment importiert haben.
- 14.2.10.1.
InnoDB-Sperrmodi - 14.2.10.2.
InnoDBundAUTOCOMMIT - 14.2.10.3.
InnoDBundTRANSACTION ISOLATION LEVEL - 14.2.10.4. Konsistentes Lesen
- 14.2.10.5. Lesevorgänge sperren
- 14.2.10.6. Nächsten Schlüssel sperren: Wie das Phantom-Problem vermieden wird
- 14.2.10.7. Ein Beispiel, wie konsistentes Lesen bei InnoDB funktioniert
- 14.2.10.8. Sperren, die in InnoDB durch unterschiedliche SQL-Anweisungen gesetzt werden
- 14.2.10.9. Implizites Commit und Rollback von Transaktionen
- 14.2.10.10. Blockierungserkennung und Rollback
- 14.2.10.11. Vom Umgang mit Deadlocks
Das Transaktionsmodell von InnoDB soll die
besten Eigenschaften einer Multiversionierungsdatenbank mit dem
traditionellen zweiphasigen Sperren verbinden.
InnoDB errichtet Sperren auf Zeilenebene und
führt Anfragen standardmäßig als nicht-sperrende, konsistente
Leseoperationen nach Art von Oracle aus. Die Sperrentabelle in
InnoDB wird so platzsparend gespeichert, dass
keine Sperreneskalation erforderlich ist: Einzelne Zeilen oder
beliebige Teile der Zeilen in der Datenbank können von mehreren
Benutzern gesperrt werden, ohne dass InnoDB der
Speicherplatz ausgeht.
InnoDB implementiert zwei Arten von
Standard-Zeilensperren:
Eine Shared-Sperre (
S) erlaubt einer Transaktion, eine Zeile (ein Tupel) zu lesen.Eine exklusive (
X) Sperre erlaubt einer Transaktion, eine Zeile zu ändern oder zu löschen.
Wenn die Transaktion T1 eine Shared-Sperre
(S) auf dem Tupel
t hält, dann
kann einer Forderung einer anderen Transaktion
T2nach einerS-Sperre auftsofort stattgegeben werden. Danach halten sowohlT1als auchT2eineS-Sperre auft.kann einer Forderung einer anderen Transaktion
T2nach einerX-Sperre auftnicht sofort stattgegeben werden.
Wenn eine Transaktion T1 eine exklusive
(X) Sperre auf Tupel
t hält, kann einer Forderung einer anderen
Transaktion T2 nach einer Sperre egal welchen
Typs auf t nicht sofort stattgegeben werden.
Transaktion T2 muss warten, bis Transaktion
T1 ihre Sperre auf Tupel t
wieder freigegeben hat.
Außerdem unterstützt InnoDB
Multigranuläre Sperren: So können Zeilen
und Tabellensperren koexistieren. Um Sperren auf mehreren
Granularitätsebenen in die Praxis umzusetzen, gibt es die so
genannten Intention Locks. Mithilfe dieser
intendierten Sperren kann eine Transaktion anzeigen, welchen
Sperrentyp (Shared oder exklusiv) sie später auf einer Zeile
einer Tabelle benötigt. In InnoDB werden
zwei Arten von Intention Locks verwendet (wir gehen davon aus,
dass Transaktion T eine Sperre des
angegebenen Typs auf Tabelle R) angefordert
hat:
Intention Shared (
IS): TransaktionTwillS-Sperren einzelner Zeilen von TabelleRerwerben.Intention Exclusive (
IX): TransaktionTwillX-Sperren auf diesen Zeilen erwerben.
Das Protokoll für Intention Locking ist wie folgt:
Bevor eine Transaktion eine
S-Sperre auf einer gegebenen Zeile errichten kann, muss sie eineIS- oder stärkere Sperre auf der Tabelle, zu der die Zeile gehört, erwerben.Bevor eine Transaktion eine
X-Sperre auf einer gegebenen Zeile errichten kann, muss sie eineIX-Sperre auf der Tabelle, zu der die Zeile gehört, erwerben.
Diese Regeln lassen sich gut in einer Matrix der Sperrtypenkompatibilität zusammenfassen:
X | IX | S | IS | |
X | Konflikt | Konflikt | Konflikt | Konflikt |
IX | Konflikt | Kompatibel | Konflikt | Kompatibel |
S | Konflikt | Konflikt | Kompatibel | Kompatibel |
IS | Konflikt | Kompatibel | Kompatibel | Kompatibel |
Der Sperranforderung einer Transaktion wird stattgegeben, wenn die Sperre mit den bereits vorhandenen Sperren kompatibel ist. Ihr wird nicht stattgegeben, wenn die Sperre mit den vorhandenen in Konflikt treten würde. Dann muss die Transaktion abwarten, bis die andere Sperre, die den Konflikt verursachen würde, freigegeben wurde. Wenn eine Sperranforderung mit einer vorhandenen Sperre in Konflikt tritt und nicht gewährt werden kann, weil sie einen Deadlock verursachen würde, wird ein Fehler ausgelöst.
Somit können Intention Locks nichts blockieren, außer
vielleicht Sperranforderungen für ganze Tabellen
(beispielsweise LOCK TABLES … WRITE).
IX und IS
sollen vor allem anzeigen, dass jemand eine Tabellenzeile sperrt
oder sperren wird.
Das folgende Beispiel zeigt, wie ein Fehler ausgelöst wird, wenn eine Sperranforderung einen Deadlock zur Folge haben würde. An dem Beispiel sind zwei Clients beteiligt, nämlich A und B.
Zuerst legt Client A eine Tabelle mit einer Zeile an und beginnt
dann eine Transaktion. Inmitten der Transaktion erwirbt A eine
S-Sperre auf der Zeile, indem er im
Shared-Modus ein Select auf ihr ausführt:
mysql>CREATE TABLE t (i INT) ENGINE = InnoDB;Query OK, 0 rows affected (1.07 sec) mysql>INSERT INTO t (i) VALUES(1);Query OK, 1 row affected (0.09 sec) mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM t WHERE i = 1 LOCK IN SHARE MODE;+------+ | i | +------+ | 1 | +------+ 1 row in set (0.10 sec)
Dann beginnt Client B eine Transaktion und versucht, die Zeile aus der Tabelle zu löschen:
mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>DELETE FROM t WHERE i = 1;
Die Löschoperation macht eine
X-Sperre erforderlich. Diese kann
jedoch nicht erteilt werden, da sie mit der
S-Sperre von Client A inkompatibel
ist. So wird der Request in die Schlange der Sperranforderungen
auf diese Zeile gestellt und Client B wird blockiert.
Endlich versucht Client A ebenfalls, die Zeile aus der Tabelle zu löschen:
mysql> DELETE FROM t WHERE i = 1;
ERROR 1213 (40001): Deadlock found when trying to get lock;
try restarting transaction
Hier tritt der Deadlock auf, da Client A eine
X-Sperre benötigt, um die Zeile
sperren zu können. Diese Sperre kann jedoch nicht gewährt
werden, da Client B schon vorher eine
X-Sperre angefordert hatte, und nur
noch darauf wartet, dass A seine
S-Sperre freigibt. Doch auch die
S-Sperre von A kann nicht auf eine
X-Sperre hochgesetzt werden, da B
schon vorher eine X-Sperre
angefordert hatte. Infolgedessen meldet
InnoDB dem Client A einen Fehler und gibt
dessen Sperre frei. Jetzt kann der Sperranforderung von Client B
stattgegeben werden und B löscht die Zeile aus der Tabelle.
In InnoDB findet jegliche Benutzeraktivität
in einer Transaktion statt. Wenn der Autocommit-Modus
eingeschaltet ist, bildet jede SQL-Anweisung eine eigene
Transaktion. Standardmäßig ist dieser Modus immer aktiv, wenn
MySQL hochfährt.
Wird Autocommit mit SET AUTOCOMMIT = 0
ausgeschaltet, gehen wir davon aus, dass der Benutzer immer eine
Transaktion offen hat. Eine COMMIT- oder
ROLLBACK-Anweisung beendet die laufende
Transaktion und eine neue beginnt. COMMIT
bedeutet, dass die Änderungen, die in der aktuellen Transaktion
vorgenommen wurden, in der Datenbank dauerhaft festgeschrieben
und für andere Benutzer sichtbar gemacht werden. Eine
ROLLBACK-Anweisung hingegen macht alle
Änderungen in der aktuellen Transaktion rückgängig. Beide
Anweisungen geben auch alle InnoDB-Sperren
frei, die in der Transaktion gesetzt wurden.
Wenn auf einer Verbindung Autocommit eingeschaltet ist, kann der
Benutzer dennoch Transaktionen aus mehreren Anweisungen
ausführen, wenn er sie mit einem expliziten START
TRANSACTION oder BEGIN einleitet
und mit COMMIT oder
ROLLBACK beendet.
Was die Transaktionsisolationsebenen von SQL:1992 angeht, so hat
InnoDB die Standardeinstellung
REPEATABLE READ. InnoDB
bietet alle vier Transaktionsisolationsebenen des SQL-Standards.
Die Standardisolationsebene können Sie mit der
--transaction-isolation-Option auf der
Kommandozeile oder in einer Optionsdatei einstellen. So können
Sie beispielsweise im [mysqld]-Abschnitt
einer Optionsdatei folgendes eintragen:
[mysqld]
transaction-isolation = {READ-UNCOMMITTED | READ-COMMITTED
| REPEATABLE-READ | SERIALIZABLE}
Ein Benutzer kann die Isolationsebene für eine einzelne Session
oder alle neuen Verbindungen mit der SET
TRANSACTION-Anweisung einstellen, die folgende Syntax
hat:
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL
{READ UNCOMMITTED | READ COMMITTED
| REPEATABLE READ | SERIALIZABLE}
Beachten Sie, dass in den Namen der Ebenen in der
--transaction-isolation-Option Bindestriche
verwendet werden, aber nicht in der SET
TRANSACTION-Anweisung.
Standardmäßig wird die Isolationsebene immer für die nächste
(noch nicht begonnene) Transaktion eingestellt. Mit dem
Schlüsselwort GLOBAL stellt die Anweisung
die Standard-Transaktionsebene global für alle neuen
Verbindungen ein, die ab diesem Punkt aufgebaut werden (aber
nicht für die schon bestehenden Verbindungen). Um dies zu tun,
benötigen Sie die SUPER-Berechtigung. Das
Schlüsselwort SESSION stellt die
Standard-Transaktionsebene für alle zukünftigen Transaktionen
auf aktuellen Verbindung ein.
Jeder Client kann die Session-Isolationsebene (sogar inmitten einer Transaktion), oder die Isolationsebene der nächsten Transaktion haben.
Ob die Transaktionsisolationsebene global oder für die einzelne
Session eingestellt wurde, können Sie anhand der
Systemvariablen tx_isolation mit folgenden
Anweisungen ermitteln:
SELECT @@global.tx_isolation; SELECT @@tx_isolation;
Für Zeilensperren verwendet InnoDB
Next-Key-Locking. Das bedeutet, dass InnoDB
zusätzlich zu den Indexeinträgen auch die
„Lücke“ vor einem Indexeintrag sperrt, um zu
verhindern, dass andere Benutzer gerade dort etwas einfügen.
Eine Next-Key-Sperre ist eine Sperre, die nicht nur den
Indexeintrag, sondern auch die Lücke vor diesem blockiert. Eine
Gap-Sperre ist eine Sperre, die lediglich die Lücke vor einem
Indexeintrag betrifft.
Im Folgenden werden die Isolationsebenen in
InnoDB genauer erläutert:
READ UNCOMMITTEDSELECT-Anweisungen werden ohne Sperren ausgeführt, wobei es jedoch möglich ist, dass eine ältere Version eines Eintrags verwendet wird. Also sind Leseoperationen mit dieser Isolationsebene nicht konsistent (man bezeichnet dies auch als „Dirty Read“). Ansonsten funktioniert diese Isolationsebene wieREAD COMMITTED.READ COMMITTEDEine Oracle-ähnliche Isolationsebene. Alle
SELECT … FOR UPDATE- undSELECT … LOCK IN SHARE MODE-Anweisungen sperren nur die Indexeinträge und nicht die Lücken davor. So können neben den gesperrten Einträgen nach Belieben neue Datensätze eingefügt werden.UPDATE- undDELETE-Anweisungen, die einen eindeutigen Index mit einer eindeutigen Suchbedingung verwenden, können nur den gefundenen Indexeintrag, aber nicht die Lücke davor, sperren. In Bereichs-UPDATEs undDELETEs mussInnoDBNext-Key- oder Gap-Sperren setzen und Einfügungen anderer Benutzer in die Lücken, die in dem Bereich liegen, blockieren. Dies ist erforderlich, da die Replikation und Recovery von MysQL nur funktioniert, wenn keine „Phantomzeilen“ vorhanden sind.Konsistente Leseoperationen verhalten sich wie in Oracle: Jede konsistente Leseoperation, sogar innerhalb derselben Transaktion, setzt und liest ihren eigenen, frischen Snapshot. Siehe Abschnitt 14.2.10.4, „Konsistentes Lesen“.
REPEATABLE READDie Standardisolationsebene von
InnoDB.SELECT … FOR UPDATE-,SELECT … LOCK IN SHARE MODE-,UPDATE- undDELETE-Anweisungen, die einen eindeutigen Index mit einer eindeutigen Suchbedingung verwenden, sperren nur den gefundenen Indexeintrag, aber nicht die Lücke davor. Für andere Suchbedingungen setzen diese Operationen Next-Key-Locking ein oder sperren den durchsuchten Indexbereich mit Next-Key- oder Gap-Sperren und blockieren dadurch Einfügungen anderer Benutzer.In konsistenten Leseoperationen gibt es einen wichtigen Unterschied zur Isolationsebene
READ COMMITTED: Alle konsistenten Leseoperationen innerhalb derselben Transaktion lesen denselben Snapshot, der von der ersten Leseoperation eingerichtet wurde. Daraus folgt: Wenn Sie mehrere einfacheSELECT-Anweisungen innerhalb derselben Transaktion erteilen, sind dieseSELECT-Anweisungen auch untereinander konsistent. Siehe Abschnitt 14.2.10.4, „Konsistentes Lesen“.SERIALIZABLEWie
REPEATABLE READ, nur dassInnoDBimplizit alle einfachenSELECT-Anweisungen zuSELECT … LOCK IN SHARE MODEcommittet.
Bei einer konsistenten Leseoperation verwendet
InnoDB Multiversionierung, um einer Anfrage
einen Snapshot der Datenbank für einen bestimmten Zeitpunkt
(Point-in-Time) zu präsentieren. Die Anfrage erkennt die
Änderungen, die Transaktionen vor diesem Zeitpunkt vorgenommen
hatten, aber keine Änderungen späterer oder noch unvollendeter
Transaktionen. Die Ausnahme: Änderungen von früheren
Anweisungen in derselben Transaktion sind für die Anweisung
sichtbar.
Wenn Sie die Standardisolationsebene REPEATABLE
READ benutzen, lesen alle konsistenten Leseoperationen
innerhalb derselben Transaktion den Snapshot, der durch die
erste Leseoperation in dieser Transaktion erzeugt wurde. Einen
frischeren Snapshot für Ihre Anfragen erhalten Sie, indem Sie
die laufende Transaktion committen und danach neue Anfragen
absetzen.
Konsistentes Lesen ist der Standardmodus, in dem
InnoDB SELECT-Anfragen auf
den Isolationsebenenen READ COMMITTED und
REPEATABLE READ verarbeitet. Konsistentes
Lesen errichtet keine Sperren auf den benutzten Tabellen, sodass
andere Benutzer diese Tabellen nach Belieben modifizieren
können, während eine konsistente Leseoperation auf ihnen
abläuft.
Beachten Sie, dass konsistente Leseoperationen nicht mit
DROP TABLE und ALTER TABLE
funktionieren. Mit DROP TABLE nicht, weil
MySQL eine Tabelle, die gelöscht wurde, nicht mehr benutzen
kann und InnoDB sie zerstört, und mit
ALTER TABLE nicht, weil dieser Befehl
innerhalb einer Transaktion ausgeführt wird, die eine neue
Tabelle anlegt und Zeilen aus der alten Tabelle in sie einfügt.
Wenn Sie die konsistente Leseoperation neu ausführen, kann sie
die Zeilen der neuen Tabelle nicht erkennen, da sie in einer
Transaktion eingefügt wurden, die in dem von der konsistenten
Leseoperation verwendeten Snapshot nicht sichtbar war.
In manchen Fällen ist eine konsistente Leseoperation nicht das
Richtige. Vielleicht möchten Sie ja eine neue Zeile in Ihre
child-Tabelle einfügen und dabei
sicherstellen, dass das Kind in der Tabelle
parent auch wirklich ein Elternteil hat. Das
folgende Beispiel zeigt, wie Sie referenzielle Integrität in
Ihren Anwendungscode implementieren können.
Angenommen, Sie verwenden eine konsistente Leseoperation, um die
Tabelle parent zu lesen, und sehen auch
tatsächlich die Elternzeile des Kindes in der Tabelle. Können
Sie die Kindzeile nun auch beruhigt in die Tabelle
child einfügen? Nein, denn es kann ja sein,
dass irgendein anderer Benutzer zwischenzeitlich die Elternzeile
aus der Tabelle parent gelöscht hat, ohne
dass Sie es merkten.
Die Lösung: Sie führen das SELECT in dem
Sperrmodus LOCK IN SHARE MODE aus:
SELECT * FROM parent WHERE NAME = 'Jones' LOCK IN SHARE MODE;
Wird eine Leseoperation im Share-Modus ausgeführt, so liest sie
die aktuellsten verfügbaren Daten und errichtet eine
Shared-Sperre auf den Zeilen, die sie liest. Diese verhindert,
dass andere Benutzer die Zeile ändern oder löschen. Wenn die
Daten zu einer noch unvollendeten Transaktion einer anderen
Clientverbindung gehören, warten wir, bis die Transaktion
committet ist. wenn wir gesehen haben, dass die obige Anfrage
den Parent 'Jones' zurückgibt, können wir
unseren Eintrag beruhigt in die child-Tabelle
einfügen und unsere Transaktion committen.
Betrachten wir ein anderes Beispiel: Wir haben in der Tabelle
child_codes ein Zählerfeld eines
Integer-Typs, das wir dazu benutzen, jedem Kind, das der
child-Tabelle hinzugefügt wird, eine
eindeutige Kennnummer zu geben. Da wäre es natürlich keine
gute Idee, den Wert des Zählers mit einer konsistenten
Leseoperation oder im Shared-Modus zu lesen, da zwei
Datenbanknutzer dann vielleicht denselben Zählerwert sehen und
einen Fehler wegen Schlüsselduplikaten auslösen, sofern sie
versuchen, Kindeinträge mit derselben Nummer in die Tabelle
einzufügen.
Hier ist LOCK IN SHARE MODE keine gute
Lösung. Denn wenn zwei Benutzer gleichzeitig den Zähler lesen,
könnte mindestens einer von ihnen in einen Deadlock geraten,
wenn er versucht, den Zähler zu aktualisieren.
Hier haben Sie zwei gute Möglichkeiten, das Lesen und
Inkrementieren des Zählers zu implementieren: (1) Sie
inkrementierten zuerst den Zähler um 1 und führen erst dann
die Leseoperation durch, oder (2) Sie lesen den Zähler zuerst
im Sperrmodus FOR UPDATE und inkrementieren
ihn danach. Der zweite Ansatz kann folgendermaßen implementiert
werden:
SELECT counter_field FROM child_codes FOR UPDATE; UPDATE child_codes SET counter_field = counter_field + 1;
Ein SELECT … FOR UPDATE liest die
neuesten verfügbaren Daten und errichtet eine exklusive Sperre
auf jeder Zeile, die es liest. Somit setzt es dieselben Sperren,
die auch ein Searched SQL UPDATE auf den
Zeilen erwerben würde.
Die obige Beschreibung ist nur ein Beispiel dafür, wie
SELECT … FOR UPDATE funktioniert. In
MySQL können Sie einen eindeutigen Identifier grundsätzlich
mit nur einem einzigen Tabellenzugriff generieren:
UPDATE child_codes SET counter_field = LAST_INSERT_ID(counter_field + 1); SELECT LAST_INSERT_ID();
Die SELECT-Anweisung ruft nur die
Identifier-Information ab (die für die aktuelle Verbindung
spezifisch ist). Sie greift auf keine Tabellen zu.
Sperren von IN SHARE MODE- und FOR
UPDATE-Leseoperationen werden freigegeben, wenn die
Transaktion committet oder zurückgerollt wird.
In Zeilensperren verwendet InnoDB einen
Algorithmus namens Next-Key-Locking.
InnoDB sperrt Zeilen so, dass es beim
Durchsuchen oder Scannen eines Tabellenindex Shared- oder
exklusive Sperren auf den gefundenen Indexeinträgen errichtet.
Also sind die Zeilensperren in Wirklichkeit
Indexeintragssperren.
Die Sperren, die InnoDB auf Indexeinträgen
errichtet, betreffen auch die „Lücke“ vor den
Einträgen. Wenn ein Benutzer eine Shared- oder exklusive Sperre
auf Eintrag R eines Index hält, kann kein
anderer Benutzer unmittelbar vor R einen
Eintrag in die Indexreihenfolge einfügen. Durch dieses so
genannte „Gap-Locking“ wird das
„Phantom-Problem“ gelöst. Angenommen, Sie wollten
alle Kinder der child-Tabelle lesen und
sperren, deren Identifier-Wert größer als 100 ist, um später
eine Spalte in den ausgewählten Zeilen zu ändern:
SELECT * FROM child WHERE id > 100 FOR UPDATE;
Angenommen, Sie haben einen Index auf der Spalte
id. Die Anfrage scannt diesen Index ab dem
ersten Eintrag, dessen id größer als 100
ist. Wenn die Sperren auf den Indexeinträgen Einfügungen in
die Lücken nicht verhindern würden, könnte in der
Zwischenzeit eine neue Zeile in die Tabelle eingefügt werden.
Wenn Sie dasselbe SELECT in derselben
Transaktion ein zweites Mal ausführten, hätten Sie plötzlich
eine zusätzliche Zeile in der Ergebnismenge. Das verstößt
aber gegen das Isolationsprinzip von Transaktionen: Eine
Transaktion muss so ablaufen, dass sich die Daten, die sie
liest, während ihrer Laufzeit nicht ändern können. Wenn wir
eine Zeilenmenge als ein Datenelement betrachten, würde die
neue „Phantomzeile“ dieses Isolationsprinzip
verletzen.
Wenn InnoDB einen Index scannt, kann es auch
die Lücke hinter dem letzten Eintrag im Index sperren. Genau
dies geschieht auch im obigen Beispiel: Die von
InnoDB gesetzten Sperren verhindern jede
Einfügung in die Tabelle an Stellen, deren
id größer als 100 ist.
Mit Next-Key-Locking können Sie eine Eindeutigkeitsprüfung in Ihrer Anwendung implementieren. Wenn Sie Ihre Daten im Share-Modus lesen und kein Duplikat der Zeile sehen, die Sie einfügen möchten, dann können Sie die Einfügung beruhigt ausführen und wissen, dass die Next-Key-Sperre auf dem Nachfolger Ihrer Zeile verhindert, dass in der Zwischenzeit jemand anders ein Duplikat Ihrer Zeile einfügt.
Angenommen, Sie verwenden die Standardisolationsebene
REPEATABLE READ. Wenn Sie eine konsistente
Leseoperation ausführen (also eine normale
SELECT-Anweisung), weist
InnoDB Ihrer Transaktion einen Zeitpunkt zu,
an dem Ihre Anfrage die Datenbank sieht. Wenn eine andere
Transaktion nach diesem Zeitpunkt eine Zeile löscht und
committet, können Sie dies nicht sehen. Einfügungen und
Änderungen werden genauso behandelt.
Sie können Ihren Zeitpunkt aktualisieren, indem Sie Ihre
Transaktion committen und eine neue
SELECT-Anfrage starten.
Dies bezeichnet man als Nebenläufigkeitssteuerung mit Multiversionierung.
User A User B
SET AUTOCOMMIT=0; SET AUTOCOMMIT=0;
time
| SELECT * FROM t;
| empty set
| INSERT INTO t VALUES (1, 2);
|
v SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
---------------------
| 1 | 2 |
---------------------
1 row in set
In diesem Beispiel sieht Benutzer A die von Benutzer B eingefügte Zeile erst dann, wenn sowohl B als auch A ihre Operationen committet haben, sodass der Zeitpunkt sich auf die Zeit nach dem Commit von B verschiebt.
Wenn Sie den „frischsten“ Zustand der Datenbank
sehen möchten, stellen Sie entweder die Isolationsebene
READ COMMITTED oder einen Locking-Read ein:
SELECT * FROM t LOCK IN SHARE MODE;
Ein Locking Read, ein UPDATE oder ein
DELETE errichten normalerweise Zeilensperren
auf jedem Indexeintrag, der bei der Verarbeitung der SQL-Anfrage
gescannt wird. Ob irgendwelche
WHERE-Bedingungen in der Anfrage die Zeile
eigentlich ausschließen würden, spielt keine Rolle.
InnoDB merkt sich nicht die genaue
WHERE-Bedigungn, sondern weiß nur, welche
Indexbereiche gescannt werden. Die Sperren auf den Einträgen
sind normalerweise Next-Key-Sperren, die auch Einfügungen in
die „Lücke“ vor dem Eintrag blockieren.
Wenn exklusive Sperren errichtet werden, ruft
InnoDB immer auch den geclusterten
Indexeintrag ab und sperrt ihn.
Wenn Sie nicht die geeigneten Indizes für Ihre Anweisung haben und MySQL die gesamte Tabelle scannen muss, um die Anfrage zu verarbeiten, werden alle Tabellenzeilen und somit auch alle Einfügeoperationen anderer Benutzer auf der Tabelle gesperrt. Es ist also wichtig, gute Indizes anzulegen, damit Ihre Anfragen nicht unnötig viele Zeilen scannen müssen.
InnoDB setzt bestimmte Arten von Sperren wie
folgt:
SELECT … FROMist ein konsistenter Lesevorgang, der einen Snapshot der Datenbank betrachtet und nur dann Sperren errichtet, wenn die TransaktionsisolationsebeneSERIALIZABLEist. In diesem Fall werden Shared Next-Key-Sperren auf die gefundenen Indexeinträge gesetzt.SELECT … FROM … LOCK IN SHARE MODEsetzt Shared Next-Key-Sperren auf alle Indexeinträge, die der Lesevorgang findet.SELECT … FROM … FOR UPDATEsetzt exklusive Next-Key-Sperren auf alle Indexeinträge, die der Lesevorgang findet.INSERT INTO … VALUES (…)setzt eine exklusive Sperre auf die eingefügte Zeile. Beachten Sie, dass diese Sperre keine Next-Key-Sperre ist und daher andere Benutzer nicht daran hindert, in die Lücke vor der neuen Zeile etwas einzufügen. Wenn ein Fehler wegen Schlüsselduplikaten auftritt, wird eine Shared-Sperre auf dem Duplikat-Indexeintrag gesetzt.Bei der Initialisierung einer zuvor angegebenen
AUTO_INCREMENT-Spalte auf einer Tabelle setztInnoDBeine exklusive Sperre auf das Ende des mit dieserAUTO_INCREMENT-Spalte verbundenen Index. Für den Zugriff auf den Auto-Increment-Zähler nutztInnoDBeinen bestimmten Tabellensperrmodus namensAUTO-INC, mit dem die Sperre nur bis zum Ende der aktuellen SQL-Anweisung und nicht der gesamten Transaktion aufrecht erhalten bleibt. Siehe Abschnitt 14.2.10.2, „InnoDBundAUTOCOMMIT“.InnoDBruft den Wert einer initialisiertenAUTO_INCREMENT-Spalte ab, ohne Sperren zu setzen.INSERT INTO T SELECT … FROM S WHERE …errichtet eine exklusive Sperre (keine Next-Key-Sperre) auf jeder inTeingefügten Zeile.InnoDBerwirbt Shared Next-Key-Sperren aufS, wenn nichtinnodb_locks_unsafe_for_binlogaktiviert ist. In diesem Fall durchsucht esSmit einer konsistenten Leseoperation.InnoDBmuss im zweiten Fall Sperren setzen: Bei einer Roll-forward-Recovery von einem Backup muss jede SQL-Anweisung in genau derselben Weise wie ursprünglich ausgeführt werden.CREATE TABLE … SELECT …führt dasSELECTals konsistente Leseoperation oder mit Shared-Sperren durch, wie oben beschrieben.REPLACEwird wie ein Insert ausgeführt, wenn keine Konflikte auf einem eindeutigen Schlüssel entstehen. Andernfalls wird eine exklusive Next-Key-Sperre auf der zu aktualisierenden Zeile errichtet.UPDATE … WHERE …setzt eine exklusive Next-Key-Sperre auf jeden bei der Suche gefundenen Datensatz.DELETE FROM … WHERE …setzt eine exklusive Next-Key-Sperre auf jeden bei der Suche gefundenen Datensatz.Wenn ein
FOREIGN KEY-Constraint auf einer Tabelle definiert ist, setzt jedes Insert, Update oder Delete, bei dem die Constraint-Bedingung geprüft werden muss, Shared-Zeilensperren auf die betrachteten Datensätze, um den Constraint zu überprüfen.InnoDBsetzt diese Sperren auch dann, wenn der Constraint versagt.LOCK TABLESsetzt Tabellensperren, allerdings auf der MySQL-Ebene, die höher als dieInnoDB-Ebene liegt.InnoDBweiß von den Tabellensperren, wenninnodb_table_locks=1(die Standardeinstellung) undAUTOCOMMIT=0eingestellt ist, und die MySQL-Ebene oberhalb vonInnoDBweiß ebenso von den Zeilensperren. Sonst kann die automatische Deadlock-Erkennung vonInnoDBkeine Deadlocks erkennen, an denen solche Tabellensperren beteiligt sind. Außerdem wäre es dann möglich, eine Tabellensperre auf einer Tabelle zu errichten, in der ein anderer Benutzer gleichzeitig Zeilensperren hält, weil die höhere MySQL-Ebene diese Zeilensperren nicht kennt. Dies bedroht allerdings nicht die Transaktionsintegrität, wie in Abschnitt 14.2.10.10, „Blockierungserkennung und Rollback“ erläutert. Siehe auch Abschnitt 14.2.16, „Beschränkungen vonInnoDB-Tabellen“.
Nach Voreinstellung beginnt MySQL jede Clientverbindung mit
eingeschaltetem Autocommit. Dabei wird nach jeder fehlerfrei
gelaufenen SQL-Anweisung ein Commit durchgeführt. Gibt die
Anweisung einen Fehler zurück, so entscheidet die Art des
Fehlers darüber, ob ein Commit oder ein Rollback ausgeführt
wird. Siehe Abschnitt 14.2.15, „InnoDB-Fehlerbehandlung“.
Wenn Sie Autocommit ausgeschaltet haben und eine Verbindung schließen, ohne explizit die letzte Transaktion zu committen, rollt MySQL diese Transaktion zurück.
Jede der folgenden Anweisungen (und ihre Synonyme) beendet
implizit eine Transaktion, als hätten Sie
COMMIT gesagt:
ALTER FUNCTION,ALTER PROCEDURE,ALTER TABLE,BEGIN,CREATE DATABASE,CREATE FUNCTION,CREATE INDEX,CREATE PROCEDURE,CREATE TABLE,DROP DATABASE,DROP FUNCTION,DROP INDEX,DROP PROCEDURE,DROP TABLE,LOAD MASTER DATA,LOCK TABLES,RENAME TABLE,SET AUTOCOMMIT=1,START TRANSACTION,TRUNCATE,UNLOCK TABLES.UNLOCK TABLEScommittet eine Transaktion nur dann, wenn Tabellen gesperrt sind.Die
CREATE TABLE-Anweisung inInnoDBwird als eine einzelne Transaktion ausgeführt. Dies bedeutet, dass einROLLBACKvom Benutzer nicht die im Lauf der Transaktion erteiltenCREATE TABLE-Anweisungen rückgängig macht.
Transaktionen können nicht geschachtelt werden. Dies ist eine
Konsequenz des impliziten COMMIT, das jede
laufende Transaktion ausführt, wenn Sie eine START
TRANSACTION-Anweisung oder ein Synonym erteilen.
InnoDB erkennt automatisch einen Deadlock von
Transaktionen und rollt eine oder mehrere Transaktion(en)
zurück, um den Deadlock aufzulösen. InnoDB
versucht, für den Rollback kleine Transaktionen herauszusuchen,
wobei die Größe einer Transaktion anhand der Anzahl der Zeilen
bestimmt wird, die sie einfügt, ändert oder löscht.
InnoDB weiß von Tabellensperren, wenn
innodb_table_locks=1 (die
Standardeinstellung) und AUTOCOMMIT=0
eingestellt ist, und die MySQL-Ebene oberhalb von
InnoDB weiß ebenso von den Zeilensperren.
Sonst kann die automatische Deadlock-Erkennung von
InnoDB keine Deadlocks erkennen, wenn eine
von der MySQL-Anweisung LOCK TABLES gesetzte
Tabellensperre oder eine von einer anderen Speicher-Engine als
InnoDB gesetzte Sperre beteiligt ist. Solche
Situationen müssen Sie durch Einstellen der Systemvariablen
innodb_lock_wait_timeout beherrschen.
Wenn InnoDB eine Transaktion vollständig
zurückrollt, werden alle von ihr gehaltenen Sperren
freigegeben. Wird jedoch nur eine einzige SQL-Anweisung infolge
eines Fehlers zurückgerollt, bleiben manche von ihr errichteten
Sperren eventuell erhalten, da InnoDB
Zeilensperren in einem Format speichert, an dem es später nicht
mehr erkennen kann, welche Anweisung welche Sperren gesetzt hat.
Deadlocks in Transaktionsdatenbanken sind ein klassisches Problem. Gefährlich werden sie aber erst dann, wenn sie so häufig auftreten, dass bestimmte Transaktionen nicht mehr möglich sind. Normalerweise müssen Sie Ihre Anwendungen so erstellen, dass sie immer bereit sind, eine Transaktion neu zu starten, wenn sie wegen eines Deadlocks zurückgerollt wurde.
InnoDB benutzt automatische Zeilensperren.
Deadlocks können sogar bei Transaktionen auftreten, die nur
eine einzige Zeile einfügen oder löschen. Da diese Operationen
nicht wirklich „atomar“ sind, errichten sie
automatisch Sperren auf den (vielleicht mehreren)
Indexeinträgen der eingefügten oder gelöschten Zeile.
Folgende Techniken helfen Ihnen, mit Deadlocks fertigzuwerden und ihre Zahl zu reduzieren:
SHOW ENGINE INNODB STATUSverrät Ihnen den Grund des letzten Deadlocks. Dies kann Ihnen helfen, Ihre Anwendung so zu tunen, dass Deadlocks vermieden werden.Seien Sie immer bereit, eine Transaktion, die wegen eines Deadlocks scheiterte, neu zu starten. Deadlocks sind nichts Schlimmes. Versuchen Sie es einfach noch einmal.
Committen Sie Ihre Transaktionen oft. Kleine Transaktionen sind nicht so konfliktanfällig.
Wenn Sie Lesesperren (
SELECT … FOR UPDATEoder… LOCK IN SHARE MODE) setzen, versuchen Sie, eine niedrigere Isolationsebene einzustellen, beispielsweiseREAD COMMITTED.Greifen Sie in einer festgelegten Reihenfolge auf Ihre Tabellen und Zeilen zu. Dann bilden die Transaktionen ordentliche Schlangen und können sich nicht gegenseitig blockieren.
Versehen Sie Ihre Tabellen mit guten Indizes. Dann müssen Ihre Anfragen weniger Indexeinträge scannen und folglich auch weniger Sperren setzen. Mit
EXPLAIN SELECTkönnen Sie feststellen, welche Indizes nach Ansicht Ihres MySQL-Servers für Ihre Anfragen die besten sind.Sperren Sie nicht so viel. Wenn Sie es sich leisten können, dass ein
SELECTDaten aus einem älteren Snapshot zurückgibt, verzichten Sie auf die KlauselFOR UPDATEoderLOCK IN SHARE MODE. Die IsolationsebeneREAD COMMITTEDist gut geeignet, da jede konsistente Leseoperation innerhalb derselben Transaktion Daten aus einem eigenen, frischen Snapshot liest.Wenn sonst nichts hilft, serialisieren Sie Ihre Transaktionen mit Tabellensperren. Um
LOCK TABLESmit Transaktionstabellen wie etwaInnoDB-Tabellen zu verwenden, setzen SieAUTOCOMMIT = 0und rufenUNLOCK TABLESerst auf, nachdem Sie die Transaktion explizit committet haben. Wenn Sie beispielsweise in die Tabellet1schreiben und aus der Tabellet2lesen möchten, tun Sie dies wie folgt:SET AUTOCOMMIT=0; LOCK TABLES t1 WRITE, t2 READ, ...;
... do something with tables t1 and t2 here ...COMMIT; UNLOCK TABLES;Tabellensperren sorgen dafür, dass Ihre Transaktions brav Schlange stehen und Deadlocks vermieden werden.
Sie können Transaktionen auch serialisieren, indem Sie eine „Semaphoren“-Hilfstabelle mit nur einer einzigen Zeile anlegen. Sorgen Sie dafür, dass jede Transaktion diese Zeile aktualsieren muss, ehe sie auf andere Tabellen zugreifen darf. Auf diese Weise laufen alle Transaktionen nacheinander ab. Beachten Sie, dass der Deadlock-Erkennungsalgorithmus von
InnoDBauch in diesem Falle funktioniert, da die serialisierende Sperre auf Zeilenebene arbeitet. Bei MySQL-Tabellensperren muss die Timeout-Methode eingesetzt werden, um Deadlocks aufzulösen.In Anwendungen, die den
LOCK TABLES-Befehl verwenden errichtet MySQL keineInnoDB-Tabellensperren, wennAUTOCOMMIT=1.
Wenn das Unix-Tool
topoder der Windows Task Manager zeigt, dass die CPU-Last unter 70% liegt, läuft Ihre Arbeit wahrscheinlich festplattengebunden ab. Vielleicht committen Sie zu oft Transaktionen oder Ihr Bufferpool ist zu klein. Diesen zu vergrößern könnte helfen, aber stellen sie ihn nicht auf 80% des physikalischen Speichers oder gar mehr ein.Verpacken Sie mehrere Modifikationen in eine einzige Transaktion.
InnoDBmuss bei jedem Committ einer Transaktion, die etwas an der Datenbank änderte, die Logs auf die Festplatte zurückschreiben. Da diese meist mit einer Geschwindigkeit von höchstens 167 Umdrehungen/Sekunde rotiert, ist diese 167tel Sekunde auch für Committs die Obergrenze, wenn die Festplatte es nicht schafft, das Betriebssystem zu „überlisten“.Wenn Sie es sich leisten können, im Falle eines Absturzes einige Ihrer zuletzt committeten Transaktionen zu verlieren, können Sie den
innodb_flush_log_at_trx_commit-Parameter auf 0 setzen.InnoDBversucht ohnehin, das Log einmal pro Sekunde auf die Platte zu schreiben, auch wenn dies nicht immer klappt.Machen Sie Ihre Logdateien groß, vielleicht genauso groß wie den Bufferpool. Wenn
InnoDBdie Logdateien vollgeschrieben hat, muss es den neuen Inhalt des Bufferpools in einem Checkpoint auf die Platte schreiben. Kleine Logdateien verursachen viele überflüssige Schreibvorgänge auf der Festplatte. Der Nachteil großer Logdateien ist die längere Recovery-Zeit.Machen Sie auch den Logpuffer recht groß (etwa 8MB).
Verwenden Sie zur Speicherung von Strings variabler Länge oder wenn die Spalte
NULL-Werte enthalten kann,VARCHARstattCHARals Datentyp. EineCHAR(-Spalte speichert immerN)NZeichen, selbst wenn der String kürzer oder sein WertNULList. Kleinere Tabellen passen besser in den Bufferpool und reduzieren die Schreibvorgänge auf der Festplatte.Wenn Sie die Standardeinstellung
row_format=compactfür das Datensatzformat von MySQL 5.1 Zeichensätze variabler Länge wie etwautf8odersjisverwenden, belegtCHAR(eine variable Menge Speicherplatz, allerdings mindestensN)NBytes.In manchen Versionen von GNU/Linux und Unix geht es erstaunlich langsam, Daten mit dem Unix-Aufruf
fsync()(denInnoDBstandardmäßig verwendet) und anderen, ähnlichen Methoden auf die Platte zu schreiben. Wenn Sie mit der Schreibleistung Ihrer Datenbank unzufrieden sind, setzen Sie deninnodb_flush_method-Parameter aufO_DSYNC. Zwar scheintO_DSYNCauf den meisten Systemen die langsamere Variante zu sein, aber vielleicht ist es gerade auf Ihrem schneller.Wenn Sie
InnoDBauf Solaris 10 for x86_64 (AMD Opteron) einsetzen, ist es wichtig, alle zum Speichern vonInnoDB-Dateien verwendeten Dateisysteme mit derforcedirectio-Option zu mounten (die standardmäßig auf Solaris 10/x86_64 nicht benutzt wird). Wenn Sie dies nicht tun, läuftInnoDBauf dieser Plattform sehr viel langsamer und hat eine geringere Performance.Wenn Sie
InnoDBmit einem großeninnodb_buffer_pool_size-Wert auf Solaris 2.6 und höher auf einer beliebigen Plattform (sparc/x86/x64/amd64) einsetzen, können Sie die Performance massiv steigern, indem Sie dieInnoDB-Daten- und -Logdateien auf Raw Devices oder einem separaten UFS-Dateisystem mit Direkt-E/A speichern (und zwar mit der Mount-Optionforcedirectio, siehemount_ufs(1M)). Wer das Veritas-Dateisystem VxFS hat, sollte die Mount-Optionconvosync=directsetzen.Andere MySQL-Datendateien, wie etwa die für
MyISAM-Tabellen, sollten nicht in einem Dateisystem mit Direkt-E/A abgelegt werden. Executables oder Bibliotheken dürfen niemals in einem Dateisystem mit Direkt-E/A abgelegt werdenBeim Datenimport in
InnoDBmüssen Sie darauf achten, dass MySQL nicht im Autocommit-Modus läuft, da dieser bei jedem Insert die Logs auf die Festplatte zurückschreibt. Um während der Import-Operation Autocommit auszuschalten, schließen Sie die Operation inSET AUTOCOMMITundCOMMIT-Anweisungen ein:SET AUTOCOMMIT=0;
... SQL import statements ...COMMIT;Mit der mysqldump-Option
--opterhalten Sie Dump-Dateien, die sich in eineInnoDB-Tabelle ganz schnell importieren lassen, selbst ohne den Import in die AnweisungenSET AUTOCOMMITundCOMMITzu verpacken.Hüten Sie sich vor umfangreichen Rollbacks von Masseneinfügeoperationen:
InnoDBbenutzt den Insert-Puffer zwar bei den Einfügungen, um Schreibvorgänge zu minimieren, aber nicht bei den zugehörigen Rollbacks. Ein festplattengebundener Rollback kann 30-mal so lange wie der zugehörige Insert brauchen. Dabei hilft es auch nichts, den Datenbankprozess anzuhalten, da der Rollback beim Hochfahren des Servers wieder von vorne beginnt. Die einzige Möglichkeit, einen außer Kontrolle geratenen Rollback aufzuhalten, besteht darin, den Bufferpool so groß anzusetzen, dass der Rollback CPU-gebunden und somit schneller läuft, oder eine spezielle Prozedur einzusetzen. Siehe Abschnitt 14.2.8.1, „Erzwingen einerInnoDB-Wiederherstellung (Recovery)“.Hüten Sie sich auch vor anderen umfangreichen festplattengebundenen Operationen. Verwenden Sie zum Leeren einer Tabelle
DROP TABLEundCREATE TABLE, aber nichtDELETE FROM.tbl_nameMit dem mehrzeiligen
INSERTkönnen Sie den Kommunikationsaufwand zwischen Client und Server minimieren, wenn Sie viele Zeilen einfügen müssen:INSERT INTO yourtable VALUES (1,2), (5,5), ...;
Dieser Tipp gilt übrigens für Einfügungen in alle möglichen Tabellen, nicht nur in
InnoDB-Tabellen.Wenn Sie
UNIQUE-Constraints auf Sekundärschlüsseln haben, können Sie Tabellenimporte beschleunigen, indem Sie die Eindeutigkeitsprüfung während der Import-Session vorübergehend abschalten:SET UNIQUE_CHECKS=0;
... import operation ...SET UNIQUE_CHECKS=1;Bei großen Tabellen spart dies eine Menge Plattenzugriffe, da
InnoDBseine Insert-Puffer dazu benutzen kann, Sekundärindexeinträge als Batch zu verarbeiten.Wenn Ihre Tabellen
FOREIGN KEY-Constraints haben, können Sie Tabellenimporte beschleunigen, indem Sie für die Dauer der Import-Session die Fremschlüsselprüfungen abschalten:SET FOREIGN_KEY_CHECKS=0;
... import operation ...SET FOREIGN_KEY_CHECKS=1;Bei großen Tabellen spart dies eine Menge Plattenzugriffe.
Wenn Sie oft wiederkehrende Anfragen auf Tabellen haben, die sich nur selten ändern, nutzen Sie den Query-Cache:
[mysqld] query_cache_type = ON query_cache_size = 10M
InnoDB hat Monitore, die Informationen über
den internen Zustand von InnoDB ausgeben. Sie
können jederzeit eine SHOW ENGINE INNODB
STATUS-Anweisung erteilen, um die Ausgabe des
InnoDB-Standardmonitors in Ihren SQL-Client
zu holen. Diese Informationen sind nützlich für das
Performance-Tuning. (Wenn Sie den interaktiven SQL-Client
mysql benutzen, ist die Ausgabe einfacher zu
lesen, wenn Sie das übliche Semikolon am Ende von Anweisungen
durch \G ersetzen.) Die Sperrmodi von
InnoDB werden in
Abschnitt 14.2.10.1, „InnoDB-Sperrmodi“ erklärt.
mysql> SHOW ENGINE INNODB STATUS\G
Eine andere Möglichkeit, InnoDB-Monitore zu
nutzen, besteht darin, sie in regelmäßigen Abständen Daten in
die Standardausgabe des mysqld-Servers
schreiben zu lassen. In diesem Fall wird keine Ausgabe an die
Clients gesandt. Wenn sie eingeschaltet sind, geben
InnoDB-Monitore etwa alle 15 Sekunden Daten
aus. Die Server-Ausgabe wird normalerweise an das
.err-Log im MySQL Data Directory geschickt.
Diese Daten sind nützlich für das Performance-Tuning. Auf
Windows müssen Sie den Server von einer Eingabeaufforderung in
einem Konsolenfenster mit der --console-Option
starten, wenn Sie die Ausgabe an das Fenster statt in das
Fehlerlog schicken wollen.
Die Monitorausgabe enthält folgende Informationen:
Tabellen- und Zeilensperren, die von den aktiven Transaktionen gehalten werden
Wartende Sperranforderungen von Transaktionen (Lock Waits)
Auf Semaphoren wartende Threads
Noch schwebende E/A-Requests
Statistikdaten über den Bufferpool
Aktivitäten des
InnoDB-Haupt-Threads zur Verschmelzung von Purge- und Insert-Puffern
Damit der InnoDB-Standardmonitor seine Daten
an die Standardausgabe von mysqld sendet,
geben Sie folgende SQL-Anweisung:
CREATE TABLE innodb_monitor (a INT) ENGINE=INNODB;
Folgende Anweisung hält den Monitor an:
DROP TABLE innodb_monitor;
Die CREATE TABLE-Syntax ist nur eine
Möglichkeit, über den SQL-Parser von MySQL einen Befehl an
InnoDB zu übergeben. Es ist nur wichtig,
dass der Tabellenname innodb_monitor und der
Tabellentyp InnoDB ist. Die Tabellenstruktur
ist für den InnoDB-Monitor nicht von Belang.
(Diese Syntax kann beim Herunterfahren des Servers wichtig sein,
der Monitor fährt bei einem Neustart des Servers nicht
automatisch wieder hoch. Sie müssen die Monitortabelle löschen
und eine neue CREATE TABLE-Anweisung geben,
um den Monitor zu starten. Das kann sich in einem künftigen
Release noch ändern.)
innodb_lock_monitor kann ähnlich eingesetzt
werden. Dieser gleicht dem innodb_monitor,
nur dass er außerdem viele Sperrinformationen gibt. Ein
separater innodb_tablespace_monitor gibt eine
Liste der angelegten Dateisegmente im Tablespace aus und
validiert die Zuweisung der Datenstrukturen im Tablespace.
Zusätzlich gibt es den innodb_table_monitor,
mit dem Sie den Inhalt des internen Data Dictionary von
InnoDB ausgeben können.
Hier sehen Sie eine Beispielausgabe des
InnoDB-Monitors:
mysql> SHOW ENGINE INNODB STATUS\G
*************************** 1. row ***************************
Status:
=====================================
030709 13:00:59 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 18 seconds
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 413452, signal count 378357
--Thread 32782 has waited at btr0sea.c line 1477 for 0.00 seconds the
semaphore: X-lock on RW-latch at 41a28668 created in file btr0sea.c line 135
a writer (thread id 32782) has reserved it in mode wait exclusive
number of readers 1, waiters flag 1
Last time read locked in file btr0sea.c line 731
Last time write locked in file btr0sea.c line 1347
Mutex spin waits 0, rounds 0, OS waits 0
RW-shared spins 108462, OS waits 37964; RW-excl spins 681824, OS waits
375485
------------------------
LATEST FOREIGN KEY ERROR
------------------------
030709 13:00:59 Transaction:
TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195, OS thread id 34831
inserting
15 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
Foreign key constraint fails for table test/ibtest11a:
,
CONSTRAINT `0_219242` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11b` (`A`,
`D`) ON DELETE CASCADE ON UPDATE CASCADE
Trying to add in child table, in index PRIMARY tuple:
0: len 4; hex 80000101; asc ....;; 1: len 4; hex 80000005; asc ....;; 2:
len 4; hex 6b68446b; asc khDk;; 3: len 6; hex 0000114e0edc; asc ...N..;; 4:
len 7; hex 00000000c3e0a7; asc .......;; 5: len 4; hex 6b68446b; asc khDk;;
But in parent table test/ibtest11b, in index PRIMARY,
the closest match we can find is record:
RECORD: info bits 0 0: len 4; hex 8000015b; asc ...[;; 1: len 4; hex
80000005; asc ....;; 2: len 3; hex 6b6864; asc khd;; 3: len 6; hex
0000111ef3eb; asc ......;; 4: len 7; hex 800001001e0084; asc .......;; 5:
len 3; hex 6b6864; asc khd;;
------------------------
LATEST DETECTED DEADLOCK
------------------------
030709 12:59:58
*** (1) TRANSACTION:
TRANSACTION 0 290252780, ACTIVE 1 sec, process no 3185, OS thread id 30733
inserting
LOCK WAIT 3 lock struct(s), heap size 320, undo log entries 146
MySQL thread id 21, query id 4553379 localhost heikki update
INSERT INTO alex1 VALUES(86, 86, 794,'aA35818','bb','c79166','d4766t',
'e187358f','g84586','h794',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),7
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290252780 lock mode S waiting
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) TRANSACTION:
TRANSACTION 0 290251546, ACTIVE 2 sec, process no 3190, OS thread id 32782
inserting
130 lock struct(s), heap size 11584, undo log entries 437
MySQL thread id 23, query id 4554396 localhost heikki update
REPLACE INTO alex1 VALUES(NULL, 32, NULL,'aa3572','','c3572','d6012t','',
NULL,'h396', NULL, NULL, 7.31,7.31,7.31,200)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks rec but not gap
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks gap before rec insert intention
waiting
Record lock, heap no 82 RECORD: info bits 0 0: len 7; hex 61613335373230;
asc aa35720;; 1:
*** WE ROLL BACK TRANSACTION (1)
------------
TRANSACTIONS
------------
Trx id counter 0 290328385
Purge done for trx's n:o < 0 290315608 undo n:o < 0 17
Total number of lock structs in row lock hash table 70
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0 0, not started, process no 3491, OS thread id 42002
MySQL thread id 32, query id 4668737 localhost heikki
show innodb status
---TRANSACTION 0 290328384, ACTIVE 0 sec, process no 3205, OS thread id
38929 inserting
1 lock struct(s), heap size 320
MySQL thread id 29, query id 4668736 localhost heikki update
insert into speedc values (1519229,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgjg
jlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjfh
---TRANSACTION 0 290328383, ACTIVE 0 sec, process no 3180, OS thread id
28684 committing
1 lock struct(s), heap size 320, undo log entries 1
MySQL thread id 19, query id 4668734 localhost heikki update
insert into speedcm values (1603393,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgj
gjlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjf
---TRANSACTION 0 290328327, ACTIVE 0 sec, process no 3200, OS thread id
36880 starting index read
LOCK WAIT 2 lock struct(s), heap size 320
MySQL thread id 27, query id 4668644 localhost heikki Searching rows for
update
update ibtest11a set B = 'kHdkkkk' where A = 89572
------- TRX HAS BEEN WAITING 0 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 65556 n bits 232 table test/ibtest11a index
PRIMARY trx id 0 290328327 lock_mode X waiting
Record lock, heap no 1 RECORD: info bits 0 0: len 9; hex 73757072656d756d00;
asc supremum.;;
------------------
---TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195, OS thread id
34831 rollback of SQL statement
ROLLING BACK 14 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
---TRANSACTION 0 290327208, ACTIVE 1 sec, process no 3190, OS thread id
32782
58 lock struct(s), heap size 5504, undo log entries 159
MySQL thread id 23, query id 4668732 localhost heikki update
REPLACE INTO alex1 VALUES(86, 46, 538,'aa95666','bb','c95666','d9486t',
'e200498f','g86814','h538',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),
---TRANSACTION 0 290323325, ACTIVE 3 sec, process no 3185, OS thread id
30733 inserting
4 lock struct(s), heap size 1024, undo log entries 165
MySQL thread id 21, query id 4668735 localhost heikki update
INSERT INTO alex1 VALUES(NULL, 49, NULL,'aa42837','','c56319','d1719t','',
NULL,'h321', NULL, NULL, 7.31,7.31,7.31,200)
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread)
I/O thread 1 state: waiting for i/o request (log thread)
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (write thread)
Pending normal aio reads: 0, aio writes: 0,
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0
Pending flushes (fsync) log: 0; buffer pool: 0
151671 OS file reads, 94747 OS file writes, 8750 OS fsyncs
25.44 reads/s, 18494 avg bytes/read, 17.55 writes/s, 2.33 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf for space 0: size 1, free list len 19, seg size 21,
85004 inserts, 85004 merged recs, 26669 merges
Hash table size 207619, used cells 14461, node heap has 16 buffer(s)
1877.67 hash searches/s, 5121.10 non-hash searches/s
---
LOG
---
Log sequence number 18 1212842764
Log flushed up to 18 1212665295
Last checkpoint at 18 1135877290
0 pending log writes, 0 pending chkp writes
4341 log i/o's done, 1.22 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 84966343; in additional pool allocated 1402624
Buffer pool size 3200
Free buffers 110
Database pages 3074
Modified db pages 2674
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages read 171380, created 51968, written 194688
28.72 reads/s, 20.72 creates/s, 47.55 writes/s
Buffer pool hit rate 999 / 1000
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
Main thread process no. 3004, id 7176, state: purging
Number of rows inserted 3738558, updated 127415, deleted 33707, read 755779
1586.13 inserts/s, 50.89 updates/s, 28.44 deletes/s, 107.88 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
Einige Hinweise zu dieser Ausgabe:
Wenn der
TRANSACTIONS-Teil Lock Waits meldet, ist Ihre Anwendung vielleicht durch Sperren blockiert. Die Ausgabe kann auch helfen, die Gründe für Transaktions-Deadlocks festzustellen.Der
SEMAPHORES-Teil meldet Threads, die auf Semaphoren warten, und Statistikdaten darüber, wie oft Threads einen Spin oder Wait auf einen Mutex oder eine Semaphpre einer Lese/Schreib-Sperre benötigt haben. Wenn viele Threads auf Semaphoren warten, kann dies am Festplatten-E/A liegen, oder auch an Verstopfungsproblemen inInnoDB. Verstopfungen können durch viele parallele Anfragen oder Probleme im Thread-Management des Betriebssystems bedingt sein. In solchen Situationen kann es helfen,innodb_thread_concurrencyauf einen kleineren als den Standardwert zu setzen.Der Abschnitt
BUFFER POOL AND MEMORYverrät Ihnen, wie viele Seiten gelesen und geschrieben werden. Aus diesen Zahlen können Sie berechnen, wie viele Datendateizugriffe Ihre Anfragen gerade ausführen.Der Abschnitt
ROW OPERATIONSzeigt, was der Haupt-Thread gerade tut.
InnoDB sendet Diagnose-Ausgabe an
stderr oder an Dateien anstatt an die
stdout-Ausgabe oder Arbeitsspeicherpuffer
fester Größe, um Puffer-Überläufe zu verhindern. Als
Nebeneffekt wird die Ausgabe von SHOW ENGINE INNODB
STATUS alle 15 Sekunden in eine Statusdatei im MySQL
Data Directory geschrieben. Diese Datei heißt
innodb_status.,
wobei pidpid die Server-Prozess-ID ist.
InnoDB entfernt diese Datei bei einem
normalen Shutdown. Bei einem unnormalen Shutdown können
Instanzen dieser Statusdateien überleben und müssen manuell
gelöscht werden. Bevor Sie dies tun, sollten Sie allerdings
hineinschauen, um zu sehen ob sie irgendwelche Hinweise auf die
Ursache der unnormalen Shutdowns enthalten. Die Datei
innodb_status.
wird nur angelegt, wenn die Konfigurationsoption
pidinnodb_status_file=1 gesetzt ist.
Da InnoDB eine Speicher-Engine mit
Multiversionierung ist, muss sie Informationen über ältere
Versionen der Zeilen im Tablespace bewahren. Diese Informationen
werden in einer Datenstruktur gespeichert, die wie in Oracle
Rollback-Segment heißt.
Internally fügt InnoDB jeder Zeile, die in der
Datenbank gespeichert wird, zwei Felder hinzu: ein 6 Byte großes
Feld mit dem Transaktions-Identifier der letzten Transaktion, mit
der die Zeile eingefügt oder geändert worden ist (eine Löschung
wird intern wie eine Änderung behandelt, bei der ein bestimmtes
Bit in der Zeile gesetzt wird, um sie als gelöscht zu
kennzeichnen), und ein 7-Byte-Feld namens Rollpointer. Dieser
zeigt auf einen Undo-Logeintrag, der in das Rollback-Segment
geschrieben wurde. Wenn die Zeile geändert wurde, enthält dieser
Undo-Logeintrag die Daten, die erforderlich sind, um ihren Inhalt
von vor der Änderung wiederherzustellen.
InnoDB benutzt die Informationen aus dem
Rollback-Segment, um die für ein Transaktions-Rollback
erforderlichen Wiederherstellungsoperationen auszuführen.
Außerdem dienen die Informationen der Erstellung älterer
Versionen einer Zeile für eine konsistente Leseoperation.
Undo-Logs im Rollback-Segment sind in Insert- und Update-Undo-Logs
getrennt. Insert-Undo-Logs werden nur für das
Transaktions-Rollback gebraucht und können gelöscht werden,
sobald die Transaktion committet wird. Update-Undo-Logs werden
auch für konsistente Leseoperationen benutzt, können aber
verworfen werden, wenn keine Transaktion mehr läuft, für die
InnoDB einen Snapshot zugewiesen hat, der für
eine konsistente Leseoperation die Daten des Update-Undo-Logs
benötigen könnte, um eine ältere Version der Datenbankzeile
wiederherzustellen.
Bitte denken Sie daran, Ihre Transaktionen regelmäßig zu
committen, einschließlich derjenigen Transaktionen, die nur
konsistente Leseoperationen ausgeben. Andernfalls kann
InnoDB die Daten aus dem Update-Undo-Log nicht
verwerfen und das Rollback-Segment kann so stark anwachsen, dass
es Ihren Tablespace ganz ausfüllt.
Die physikalische Größe eines Undo-Logeintrags im Rollback-Segment ist normalerweise kleiner als die zugehörige eingefügte oder geänderte Zeile. Mit diesen Informationen können Sie berechnen, wie viel Platz für Ihr Rollback-Segment erforderlich ist.
In der Multiversionierung von InnoDB wird eine
Zeile nicht sofort physikalisch aus der Datenbank entfernt, wenn
Sie sie mit einer SQL-Anweisung löschen. Erst wenn
InnoDB den für die Löschung erstellten
Update-Undo-Logeintrag entfernen kann, kann es auch die Zeile und
ihre Indexeinträge physikalisch aus der Datenbank entfernen.
Diese Löschoperation bezeichnet man als Purge. Sie läuft sehr
schnell, ungefähr genauso schnell wie die SQL-Löschanweisung.
In einem Szenario, in dem der Benutzer Zeilen in kleinen,
ungefähr gleichen Batches aus der Tabelle löscht, kann es
passieren, dass der Purge-Thread beginnt, hinterherzuhinken, und
die Tabelle immer größer wird, wodurch sich alle
Festplattenoperationen stark verlangsamen. Selbst Tabellen, die
nur 10MB an brauchbaren Daten aufweisen, können mit allen
„toten“ Zeilen auf 10GB anwachsen. In solchen Fällen
wäre es gut, neue Zeilenoperationen zurückzufahren und dem
Purge-Thread mehr Ressourcen zuzuweisen. Genau zu diesem Zweck
gibt es die Systemvariable
innodb_max_purge_lag. Weitere Informationen
finden Sie unter Abschnitt 14.2.4, „InnoDB: Startoptionen und Systemvariablen“.
MySQL speichert seine Data Dictionary-Informationen über Tabellen
in .frm-Dateien in Datenbankverzeichnissen.
Das gilt für alle Speicher-Engines von MySQL. Doch jede
InnoDB-Tabelle hat auch einen eigenen Eintrag
im internen InnoDB-Data Dictionary innerhalb
des Tablespace. Wenn MySQL eine Tabelle oder Datenbank löscht,
muss es sowohl die .frm-Datei(en) als auch
die zugehörigen Einträge im InnoDB-Data
Dictionary löschen. Daher dürfen Sie auch
InnoDB-Tabellen nicht einfach durch Verschieben
der .frm-Dateien von einer Datenbank in die
andere übertragen.
Jede InnoDB-Tabelle besitzt einen speziellen,
so genannten geclusterten Index, der die
Daten über die Zeilen speichert. Wenn Sie einen PRIMARY
KEY auf Ihrer Tabelle definieren, ist der Index dieses
Primärschlüssels der geclusterte Index.
Wenn Sie keinen PRIMARY KEY für Ihre Tabelle
definieren, wählt MySQL den ersten
UNIQUE-Index, der nur NOT
NULL-Spalten hat, als Primärschlüssel aus, und
InnoDB verwendet diesen als geclusterten Index.
Wenn die Tabelle keinen solchen Index besitzt, wird intern von
InnoDB ein geclusterter Index generiert, in dem
die Zeilen nach der Zeilen-ID geordnet sind, die
InnoDB den Zeilen derartiger Tabellen zuweist.
Die Zeilen-ID ist ein 6-Byte-Feld, das monoton wächst, wenn neue
Zeilen eingefügt werden. Somit stehen die nach Zeilen-ID
geordneten Zeilen physikalisch in der Reihenfolge ihrer
Einfügung.
Über einen geclusterten Index ist eine Zeile schnell zu erreichen, da die Zeilendaten auf derselben Seite liegen, zu der die Indexsuche hinführt. Wenn eine Tabelle groß ist, speichert die Clustered-Index-Architektur im Vergleich zu der traditionellen Lösung oft Plattenzugriffe. (In vielen Datenbanksystemen sind die Daten auf einer anderen Seite gespeichert als der Indexeintrag.)
In InnoDB enthalten die Datensätze in
nicht-geclusterten Indizes (auch Sekundärindizes genannt) den
Primärschlüsselwert für die Zeile. InnoDB
benutzt diesen Primärschlüsselwert, um die Zeile in dem
geclusterten Index zu suchen. Beachten Sie: Wenn der
Primärschlüssel lang ist, brauchen die Sekundärindizes mehr
Platz.
InnoDB vergleicht unterschiedlich lange
CHAR- und VARCHAR-Strings,
indem es die Längendifferenz im kürzeren String als mit
Leerzeichen ausgefüllt betrachtet.
Alle InnoDB-Indizes sind B-Trees, wobei die
Indexeinträge in den Blattseiten des Baums gespeichert werden.
Die Standardgröße einer Indexseite beträgt 16KB. Wenn neue
Einträge eingefügt werden, versucht InnoDB,
1/16 der Seite für zukünftige Einfügungen und Änderungen der
Indexeinträge frei zu halten.
Wenn Indexeinträge in (auf- oder absteigender) sequenzieller
Reihenfolge eingefügt werden, werden die Indexseiten zu 15/16
voll. Werden die Einträge in zufälliger Reihenfolge
eingefügt, werden die Seiten nur zu 1/2 bis 15/16 voll. Wenn
der Füllstand einer Indexseite unter 1/2 fällt, versucht
InnoDB mit dem Indexbaum zu vereinbaren, dass
die Seite freigegeben wird.
In Datenbankanwendungen kommt es häufig vor, dass ein Primärschlüssel ein eindeutiger Identifier ist und neue Zeilen in der aufsteigenden Reihenfolge des Primärschlüssels eingefügt werden. So sind für Einfügungen in den geclusterten Index keine willkürlichen Lesezugriffe auf eine Festplatte erforderlich.
Dagegen sind Sekundärindizes normalerweise nicht-eindeutig und
Einfügungen in sie finden in relativ willkürlicher Reihenfolge
statt. Dies würde eine Menge willkürlicher E/A-Operationen auf
der Festplatte erfordern, wenn es in InnoDB
nicht einen speziellen Mechanismus gäbe.
Wenn ein Indexeintrag in einen nicht-eindeutigen Sekundärindex
eingefügt werden soll, prüft InnoDB, ob
dieser Sekundärindex im Bufferpool liegt. Wenn ja, führt
InnoDB die Einfügung direkt auf der
Indexseite durch. Wenn nicht, fügt InnoDB
den Eintrag in eine spezielle Insert-Puffer-Struktur ein. Der
Insert-Puffer wird so klein gehalten, dass er komplett in den
Bufferpool passt und Einfügungen sehr schnell erledigt werden
können.
Dieser Insert-Puffer wird regelmäßig mit den Sekundärindexbäumen in der Datenbank zusammengeführt. Oft können mehrere Einfügeoperationen auf derselben Seite des Indexbaums gleichzeitig zusammengeführt werden, was Festplattenzugriffe spart. Messungen haben ergeben, dass der Insert-Puffer Einfügungen in eine Tabelle bis zu 15-mal schneller laufen lässt.
Das Zusammenführen von Insert-Puffer-Daten kann auch dann
weitergehen, nachdem die einfügende
Transaktion committet wurde, ja sogar nach dem Herunterfahren
und Neustart des Servers (siehe
Abschnitt 14.2.8.1, „Erzwingen einer InnoDB-Wiederherstellung (Recovery)“).
Das Zusammenführen von Insert-Puffer-Daten kann viele Stunden dauern, wenn viele Sekundärindizes aktualisiert werden müssen und viele Zeilen eingefügt wurden. In dieser Zeit erhöht sich die E/A-Aktivität, sodass festplattengebundene Anfragen eventuell viel langsamer laufen. Eine andere, wichtige E/A-Hintergrundoperation ist der Purge-Thread (siehe Abschnitt 14.2.12, „Implementierung der Multiversionierung“).
Wenn eine Tabelle fast komplett in den Hauptspeicher passt, sind
Hash-Indizes das schnellste Mittel, um Anfragen auszuführen.
InnoDB hat einen Mechanismus, der
Index-Suchen auf den Indizes einer Tabelle beobachtet. Wenn
InnoDB bemerkt, dass Anfragen von einem
Hash-Index profitieren könnten, baut es automatisch einen auf.
Beachten Sie, dass der Hash-Index immer auf einem vorhandenen
B-Baum-Index der Tabelle aufbaut. InnoDB kann
einen Hash-Index auf einem beliebig langen Präfix des für den
B-Baum definierten Schlüssels aufbauen, je nachdem, welches
Suchmuster InnoDB für den B-Baum-Index
beachtet. Ein Hash-Index kann auch partiell sein: Es ist nicht
notwendig, den gesamten B-Baum-Index im Bufferpool zu cachen.
InnoDB baut Hash-Indizes nach Bedarf für
diejenigen Indexseiten auf, die oft angesprochen werden.
In gewissem Sinne legt sich InnoDB durch den
anpassungsfähigen Hash-Index-Mechanismus selbst auf einen
großen Arbeitsspeicher hin aus und kommt dadurch der
Architektur von Hauptspeicher-Datenbanken näher.
Datensätze von InnoDB-Tabellen haben
folgende Merkmale:
Jeder Indexeintrag hat einen sechs Bytes großen Header, der benutzt wird, um aufeinanderfolgende Datensätze zu verknüpfen, und auch in Zeilensperren zum Einsatz kommt.
Einträge im geclusterten Index enthalten Felder für alle benutzerdefinierten Spalten. Zusätzlich gibt es ein sechs Bytes großes Feld für die Transaktions-ID und ein sieben Bytes großes für den Rollpointer.
Wenn für eine Tabelle kein Primärschlüssel definiert wurde, enhält jeder geclusterte Indexeintrag auch ein sechs Bytes großes Feld mit der Zeilen-ID.
Jeder Sekundärindexeintrag enthält auch alle Felder, die für den geclusterten Indexschlüssel definiert worden sind.
Ein Datensatz enthält auch einen Zeiger auf die einzelnen Felder des Datensatzes. Wenn deren Gesamtlänge 128 Bytes nicht übersteigt, ist der Zeiger ein Byte, ansonsten zwei Bytes groß. Das Array dieser Zeiger bezeichnet man als Record Directory. Der Bereich, auf den sie zeigen, ist der Datenteil des Datensatzes.
Intern speichert
InnoDBZeichenspalten fester Breite, wie beispielsweiseCHAR(10), in einem Format mit fester Länge.InnoDBkappt Leerzeichen am Ende vonVARCHAR-Spalten.Ein SQL-
NULL-Wert reserviert 1 oder 2 Bytes im Record Directory und null Bytes im Datenteil des Eintrags, wenn er in einer Spalte mit variabler Länge gespeichert ist. In einer Spalte fester Länge reserviert er diese festgelegte Länge auch fürNULL-Werte, damit eine Aktualisierung, die die Spalte vonNULLauf einen anderen Wert setzt, vor Ort ohne Fragmentierung der Indexseite ausgeführt werden kann.
InnoDB verwendet simulierte, asynchrone
Festplattenein- und -ausgaben (E/A) und erzeugt mehrere Threads
für E/A-Operationen wie beispielsweise Read-ahead.
Es gibt zwei Read-ahead-Heuristiken in
InnoDB:
Beim sequenziellen Read-ahead schickt
InnoDB, wenn es bemerkt, dass ein Segment im Tablespace ein sequenzielles Zugriffsmuster aufweist, im Voraus einen Batch Leseoperationen auf Datenbankseiten an das E/A-System.Beim willkürlichen Read-ahead schickt
InnoDB, wenn es bemerkt, dass ein Bereich im Tablespace im Begriff ist, vollständig in den Bufferpool eingelesen zu werden, die restlichen Leseoperationen an das E/A-System.
InnoDB verwendet eine neue Technik namens
Doublewrite, um Dateien auf die
Festplatte zurückzuschreiben. Dadurch wird die Recovery nach
einem Betriebssystemabsturz oder einem Stromausfall sicherer und
die Leistung der meisten Unix-Varianten besser, da nicht mehr so
viele fsync()-Operationen nötig sind.
Doublewrite sorgt dafür, dass InnoDB Seiten
nicht gleich in die Datendatei, sondern zuerst in einen
zusammenhängenden Tablespace-Bereich namens Doublewrite-Puffer
schreibt. Erst wenn dieser Vorgang abgeschlossen ist, werden die
Seiten in ihre angestammten Plätze in der Datendatei
geschrieben. Stürzt das Betriebssystem mitten im Schreiben
einer Seite ab, kann InnoDB später bei der
Recovery eine gute Kopie der Seite im Doublewrite-Puffer finden.
Die in der Konfigurationsdatei definierten Datendateien bilden
den Tablespace von InnoDB. Die Dateien werden
einfach aneinander gehängt, um diesen Tablespace zu bilden. Es
wird kein Striping verwendet. Zurzeit können Sie noch nicht
bestimmen, an welche Stelle des Tablespaces Ihre Tabellen
zugewiesen werden. Doch in einem neuen Tablespace wird der Platz
beginnend mit der ersten Datendatei zugewiesen.
Der Tablespace besteht aus Datenbankseiten mit einer
Standardgröße von 16KB. Die Seiten werden zu Extents von 64
aufeinander folgenden Seiten zusammengefasst. Die
„Dateien“ eines Tablespace nennt man in
InnoDB Segmente. Der
Begriff „Rollback-Segment“ ist etwas irreführend,
da er in Wirklichkeit viele Tablespace-Segmente umfasst.
Für jeden Index in InnoDB werden zwei
Segmente zugewiesen. eines für Nicht-Blattknoten und das andere
für Blattknoten des B-Baums. Dadurch wird eine bessere Abfolge
der Blattknoten, die die eigentlichen Daten enthalten, erreicht.
Wenn ein Segment im Tablespace anwächst, weist ihm
InnoDB die ersten 32 Seiten einzeln zu, und
danach nur noch vollständige Extents. InnoDB
kann einem großen Segment bis zu 4 Extents zugleich zuweisen,
um eine gute Datensequenzialität zu gewährleisten.
Da manche Seiten im Tablespace Bitmaps anderer Seiten enthalten,
können einige Extents eines
InnoDB-Tablespace den Segmenten nicht als
Ganzes, sondern nur in Form einzelner Seiten zugewiesen werden.
Wenn Sie mit einer SHOW TABLE
STATUS-Anweisung fragen, wie viel Platz in einem
Tablespace noch frei ist, meldet InnoDB nur
die Extents, die darin definitiv noch nicht belegt sind.
InnoDB reserviert immer einige Extents für
die Reinigungsaufgaben und andere interne Zwecke. Diese
reservierten Extents sind in dem freien Platz nicht inbegriffen.
Wenn Sie Daten aus einer Tabelle löschen, kontrahiert
InnoDB die entsprechenden B-Baum-Indizes. Ob
der frei gewordene Platz für ander Benutzer verfügbar wird,
hängt davon ab, ob das Löschungsmuster einzelne Seiten oder
ganze Extents des Tablespace freigibt. Wenn Sie eine Tabelle
oder alle in ihr befindlichen Zeilen löschen, dann wird
garantiert der Platz für andere Benutzer freigegeben, aber
vergessen Sie nicht, dass gelöschte Zeilen physikalisch erst in
einer (automatischen) Purge-Operation entfernt werden, wenn sie
auch für Transaktions-Rollbacks und konsistente Leseoperationen
nicht mehr gebraucht werden. (Siehe
Abschnitt 14.2.12, „Implementierung der Multiversionierung“.)
Wenn willkürliche Einfügungen oder Löschungen in den Indizes einer Tabelle vorgenommen werden, können diese Indizes fragmentiert werden. Fragmentierung bedeutet, dass die physikalische Reihenfolge der Indexseiten auf der Platte nicht der Reihenfolge des Index für die Datensätze der Seiten entspricht, oder dass viele ungenutzte Seiten in den 64-Seiten-Blöcken vorhanden sind, die dem Index zugewiesen wurden.
Ein Fragmentierungssymptom liegt vor, wenn eine Tabelle mehr
Platz belegt, als sie „sollte“. Wieviel mehr, das
ist in der Praxis schwer zu sagen. Alle
InnoDB-Daten und -Indizes werden in B-Bäumen
gespeichert und ihr Füllfaktor kann zwischen 50% und 100%
variieren. Ein anderes Symptom für Fragmentierung wäre es,
wenn ein Tabellenscan wie dieser mehr Zeit braucht, als er
„sollte“:
SELECT COUNT(*) FROM t WHERE a_non_indexed_column <> 12345;
(In der obigen Anfrage „überlisten“ wir die SQL-Optimierung, damit sie statt des Sekundärindex den geclusterten Index durchsucht.) Die meisten Festplatten können 10 bis 50MB/s lesen. Anhand dieses Werts können sie einschätzen, wie schnell ein Tabellenscan eigentlich laufen sollte.
Index-Scans können schneller laufen, wenn Sie regelmäßig eine
„Null“-ALTER TABLE-Operation
durchführen:
ALTER TABLE tbl_name ENGINE=INNODB
Dies veranlasst MySQL, die Tabelle neu zu erstellen. Eine andere Möglichkeit für eine Defragmentierungsoperation wäre es, die Tabelle mit mysqldump in eine Textdatei zu dumpen, zu löschen und aus der Dump-Datei neu zu laden.
Wenn die Einfügungen in einen Index immer in aufsteigender
Reihenfolge und Löschungen nur an seinem Ende stattfinden,
garantiert der Dateiraumverwaltungs-Algorithmus von
InnoDB, dass keine Fragmentierung in diesem
Index auftreten kann.
Die Fehlerbehandlung in InnoDB entspricht nicht
immer dem SQL-Standard. Nach dem Standard müsste jeder Fehler,
der während einer SQL-Anweisung auftritt, den Rollback dieser
Anweisung zur Folge haben. InnoDB rollt jedoch
manchmal nur einen Teil der Anweisung zurück, oder aber auch die
ganze Transaktion. Die folgenden Einträge beschreiben die
Fehlerbehandlung von InnoDB:
Wenn Ihr Tablespace vollläuft, tritt ein MySQL
Table is full-Fehler auf undInnoDBrollt die SQL-Anweisung zurück.Ein Transaktions-Deadlock lässt
InnoDBdie gesamte Transaktion zurückrollen. Im Fall eines Lock Wait Timeout rolltInnoDBnur die letzte SQL-Anweisung zurück.Wenn wegen eines Deadlocks oder Lock Wait Timeouts eine Transaktion zurückgerollt wird, so werden die in dieser Transaktion ausgeführten Anweisungen wirkungslos. Wenn jedoch die Startanweisung der Transaktion
START TRANSACTIONoderBEGINwar, so wird die Anweisung durch den Rollback nicht betroffen. Weitere SQL-Anweisungen werden dann zu einem Teil der Transaktion, bis einCOMMIT,ROLLBACKoder eine andere SQL-Anweisung eintritt, die einen impliziten Commit verursacht.Ein Schlüsselduplikat-Fehler rollt die SQL-Anweisung zurück, wenn Sie nicht die
IGNORE-Option in der Anweisung angegeben haben.Ein
row too long errorrollt die SQL-Anweisung zurück.Andere Fehler werden zumeist auf der MySQL-Ebene erkannt (also oberhalb der Ebene von
InnoDB), und rollen die zugehörige SQL-Anweisung zurück. Sperren werden bei einem Rollback einer einzelnen SQL-Anweisung nicht freigegeben.
Während eines impliziten Rollback und während der Ausführung
eines expliziten ROLLBACK-Befehls von SQL zeigt
SHOW PROCESSLIST den Wert Rolling
back in der State-Spalte der
betreffenden Verbindung an.
Es folgt eine (nicht vollständige) Liste häufiger
InnoDB-spezifischer Fehler, einschließlich
ihrer Ursachen und Lösungsmöglichkeiten.
1005 (ER_CANT_CREATE_TABLE)Tabelle kann nicht angelegt werden. Wenn die Fehlermeldung auf
errno150 verweist, schlug die Tabellenerzeugung fehl, weil ein Fremdschlüssel-Constraint nicht richtig gebildet wurde.1016 (ER_CANT_OPEN_FILE)Die
InnoDB-Tabelle kann in denInnoDB-Datendateien nicht gefunden werden, obwohl die.frm-Datei für die Tabelle existiert. Siehe Abschnitt 14.2.17.1, „Troubleshooting vonInnoDBbei Data Dictionary-Operationen“.1114 (ER_RECORD_FILE_FULL)InnoDBhat keine Platz im Tablespace mehr frei. Rekonfigurieren Sie den Tablespace, indem Sie eine neue Datendatei hinzufügen.1205 (ER_LOCK_WAIT_TIMEOUT)Lock Wait Timeout ist abgelaufen. Transaktion wurde zurückgerollt.
1213 (ER_LOCK_DEADLOCK)Transaktions-Deadlock. Führen Sie die Transaktion erneut aus.
1216 (ER_NO_REFERENCED_ROW)Sie versuchen, eine neue Zeile einzufügen, aber da es keine Elternzeile gibt, wird ein Fremdschlüssel-Constraint verletzt. Fügen Sie als Erstes die Elternzeile ein.
1217 (ER_ROW_IS_REFERENCED)Sie versuchen, eine Elternzeile zu löschen, die Kinder hat, wodurch ein Fremdschlüssel-Constraint verletzt wird. Löschen Sie zuerst die Kinder.
Die Bedeutung einer Betriebssystem-Fehlernummer können Sie mit dem Programm perror ermitteln, das zur MySQL-Distribution gehört.
Die folgende Tabelle enthält eine Liste der häufigsten Systemfehlercodes von Linux. Eine vollständigere Aufstellung finden Sie unter Linux-Quellcode.
1 (EPERM)Operation nicht gestattet
2 (ENOENT)Datei oder Verzeichnis nicht vorhanden
3 (ESRCH)Prozess nicht vorhanden
4 (EINTR)Unterbrochener Systemaufruf
5 (EIO)E/A-Fehler
6 (ENXIO)Device oder Adresse nicht vorhanden
7 (E2BIG)Argumenteliste zu lang
8 (ENOEXEC)Exec-Format-Fehler
9 (EBADF)Dateinummer stimmt nicht
10 (ECHILD)Kein Kindprozess
11 (EAGAIN)Versuchen Sie es erneut
12 (ENOMEM)Kein Arbeitsspeicher mehr frei
13 (EACCES)Berechtigung verweigert
14 (EFAULT)Adresse stimmt nicht
15 (ENOTBLK)Block-Device erforderlich
16 (EBUSY)Device oder Ressource ist belegt
17 (EEXIST)Datei vorhanden
18 (EXDEV)Cross-Device-Link
19 (ENODEV)Device nicht vorhanden
20 (ENOTDIR)Ist kein Verzeichnis
21 (EISDIR)Ist ein Verzeichnis
22 (EINVAL)Ungültiges Argument
23 (ENFILE)Dateitabellenüberlauf
24 (EMFILE)Zu viele geöffnete Dateien
25 (ENOTTY)Unpassender ioctl für Device
26 (ETXTBSY)Textdatei belegt
27 (EFBIG)Datei zu groß
28 (ENOSPC)Device hat keinen Platz mehr frei
29 (ESPIPE)Unzulässige Suche
30 (EROFS)Schreibgeschütztes Dateisystem
31 (EMLINK)Zu viele Links
Die folgende Tabelle enthält eine Liste häufiger Windows-Systemfehlercodes. Eine vollständigere Aufstellung finden Sie auf der Website von Microsoft.
1 (ERROR_INVALID_FUNCTION)Funktion nicht korrekt
2 (ERROR_FILE_NOT_FOUND)System kann die Datei nicht finden
3 (ERROR_PATH_NOT_FOUND)System kann den Pfad nicht finden
4 (ERROR_TOO_MANY_OPEN_FILES)System kann die Datei nicht öffnen
5 (ERROR_ACCESS_DENIED)Zugriff verweigert
6 (ERROR_INVALID_HANDLE)Ungültiger Handle
7 (ERROR_ARENA_TRASHED)Speichersteuerungsblöcke wurden zerstört
8 (ERROR_NOT_ENOUGH_MEMORY)Zu wenig Speicher, um diesen Befehl zu verarbeiten
9 (ERROR_INVALID_BLOCK)Speichersteuerungsblock-Adresse ist ungültig
10 (ERROR_BAD_ENVIRONMENT)Die Umgebung ist nicht korrekt
11 (ERROR_BAD_FORMAT)Versuch, ein Programm mit einem unzulässigen Format zu laden
12 (ERROR_INVALID_ACCESS)Zugriffscode ist ungültig
13 (ERROR_INVALID_DATA)Daten sind ungültig
14 (ERROR_OUTOFMEMORY)Nicht genug Speicher vorhanden, um die Operation auszuführen
15 (ERROR_INVALID_DRIVE)System kann das angegebene Laufwerk nicht finden
16 (ERROR_CURRENT_DIRECTORY)Verzeichnis kann nicht entfernt werden
17 (ERROR_NOT_SAME_DEVICE)System kann die Datei nicht auf ein anderes Festplattenlaufwerk verlagern
18 (ERROR_NO_MORE_FILES)Keine weiteren Dateien vorhanden
19 (ERROR_WRITE_PROTECT)Schreibgeschütztes Speichermedium
20 (ERROR_BAD_UNIT)System kann das angegebene Gerät nicht finden
21 (ERROR_NOT_READY)Gerät ist nicht bereit
22 (ERROR_BAD_COMMAND)Gerät erkennt den Befehl nicht
23 (ERROR_CRC)Datenfehler (zyklische Redundanzprüfung)
24 (ERROR_BAD_LENGTH)Das Programm hat einen Befehl gegeben, dessen Länge nicht stimmt
25 (ERROR_SEEK)Das Laufwerk konnte einen bestimmten Bereich oder Track auf der Festplatte nicht finden
26 (ERROR_NOT_DOS_DISK)Kein Zugriff auf die Platte oder Diskette
27 (ERROR_SECTOR_NOT_FOUND)Das Laufwerk kann den angeforderten Sektor nicht finden
28 (ERROR_OUT_OF_PAPER)Kein Papier im Drucker
29 (ERROR_WRITE_FAULT)System kann auf das angegebene Gerät nicht schreiben
30 (ERROR_READ_FAULT)System kann von dem angegebenen Gerät nicht lesen
31 (ERROR_GEN_FAILURE)Ein mit dem System verbundenes Gerät funktioniert nicht
32 (ERROR_SHARING_VIOLATION)Der Prozess kann nicht auf die Datei zugreifen, da sie von einem anderen Prozess benutzt wird
33 (ERROR_LOCK_VIOLATION)Der Prozess kann nicht auf die Datei zugreifen, da sie von einem anderen Prozess teilweise gesperrt wurde
34 (ERROR_WRONG_DISK)Verkehrte Diskette im Laufwerk. Legen Sie %2 (Volume-Seriennummer: %3) in Laufwerk %1 ein
36 (ERROR_SHARING_BUFFER_EXCEEDED)Zu viele Dateien für gemeinsame Nutzung geöffnet
38 (ERROR_HANDLE_EOF)Dateiende erreicht
39 (ERROR_HANDLE_DISK_FULL)Festplatte ist voll
87 (ERROR_INVALID_PARAMETER)Der Parameter ist verkehrt. (Wenn auf Windows dieser Fehler auftritt und
innodb_file_per_tablein einer Serveroptionsdatei eingeschaltet wurde, fügen Sie der Datei zusätzlich die Zeileinnodb_flush_method=unbufferedhinzu.)112 (ERROR_DISK_FULL)Festplatte ist voll
123 (ERROR_INVALID_NAME)Dateiname oder Verzeichnisname oder Volume-Label-Syntax ist verkehrt
1450 (ERROR_NO_SYSTEM_RESOURCES)Systemressourcen reichen nicht, um den angefragten Service abzuschließen
Warnung: Konvertieren Sie niemals MySQL-Systemtabellen in der
mysql-Datenbank aus demMyISAM- in dasInnoDB-Format! Diese Operation wird nicht unterstützt. Wenn Sie dies tun, kann MySQL erst dann wieder gestartet werden, wenn Sie die alten Systemtabellen aus einem Backup wiederhergestellt oder mit dem Skript mysql_install_db neu generiert haben.Eine Tabelle darf nicht mehr als 1000 Spalten haben.
Die interne maximale Schlüssellänge beträgt 3500 Bytes, aber MySQL selbst schränkt dies auf 1024 Bytes ein.
Die maximale Zeilenlänge beträgt (außer bei
VARCHAR-,BLOB- undTEXT-Spalten) etwas weniger als die Hälfte einer Datenbankseite, also rund 8000 Bytes.LONGBLOB- undLONGTEXT-Spalten müssen kleiner als 4GB und die maximale Länge einer Zeile (auch beiBLOB- undTEXT-Spalten) muss kleiner als 4GB sein.InnoDBspeichert die ersten 768 Bytes einerVARCHAR-,BLOB- oderTEXT-Spalte in der Zeile und den Rest in separaten Seiten.Obwohl
InnoDBintern auch Zeilen von mehr als 65535 unterstützt, können Sie keine Zeile definieren, dieVARCHAR-Spalten mit einer kombinierten Größe von mehr als 65535 enthält:mysql>
CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000),->c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000),->f VARCHAR(10000), g VARCHAR(10000)) ENGINE=InnoDB;ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBsAuf manchen älteren Betriebssystemen müssen Dateien kleiner als 2GB sein. Das ist zwar keine
InnoDB-spezifische Beschränkung, aber wenn Sie einen großen Tablespace benötigen, müssen Sie diesen so konfigurieren, dass er mehrere kleine statt einer großen Datendatei enthält.Die kombinierte Größe aller
InnoDB-Logdateien muss unter 4GB liegen.Die Mindestgröße eines Tablespace beträgt 10MB und seine Höchstgröße vier Milliarden Datenbankseiten (64TB). Dies ist auch die Maximalgröße für eine Tabelle.
InnoDB-Tabellen unterstützen keineFULLTEXT-Indizes.ANALYZE TABLEermittelt die Indexkardinalität (anhand derCardinality-Spalte der Ausgabe vonSHOW INDEX), indem er acht Zufallssprünge in jeden der Indexbäume unternimmt und die Schätzungen der Indexkardinalität entsprechend aktualisiert. Da dies nur Schätzungen sind, können unterschiedliche Ausführungen vonANALYZE TABLEunterschiedliche Zahlen ergeben. Dadurch läuftANALYZE TABLEaufInnoDB-Tabellen zwar schnell, aber nicht zu 100% präzise, da es nicht alle Zeilen berücksichtigt.MySQL verwendet die Indexkardinalitäts-Schätzungen nur in der Optimierung von Joins. Ist ein Join nicht richtig optimiert, können Sie es mit
ANALYZE TABLEversuchen. In den seltenen Fällen, daANALYZE TABLEfür Ihre Tabellen keine ausreichend guten Werte produziert, können Sie Ihre Anfragen mitFORCE INDEXausführen und ihnen damit einen bestimmten Index aufzwingen, oder die Systemvariablemax_seeks_for_keysetzen, damit MySQL eher im Index nachschaut, als Tabellen zu scannen. Siehe Abschnitt 5.2.2, „Server-Systemvariablen“ und Abschnitt A.6, „Probleme im Zusammenhang mit dem Optimierer“.SHOW TABLE STATUSzeigt keine präzisen Statistikdaten überInnoDB-Tabellen an, wenn man von der physikalischen Größe absieht, die für sie reserviert ist. Die Zeilenzahl ist nur eine grobe Schätzung, die für die SQL-Optimierung genutzt wird.InnoDBpflegt keinen internen Zähler für die Anzahl der Zeilen in einer Tabelle. (In der Praxis wäre das wegen der Multiversionierung auch etwas kompliziert.) Um eineSELECT COUNT(*) FROM t-Anweisung zu verarbeiten, mussInnoDBeinen Index der Tabelle scannen. Das braucht Zeit, wenn der Index nicht komplett im Bufferpool liegt. Um schneller eine Zahl zu erhalten, müssen Sie selbst eine Zählertabelle erstellen und dafür sorgen, dass Ihre Anwendung sie bei Einfügungen und Löschungen aktualisiert. Wenn sich Ihre Tabelle nicht oft ändert, ist der MySQL-Anfragecache eine gute Lösung.SHOW TABLE STATUSkann ebenfalls eingesetzt werden, wenn Ihnen ein Näherungswert genügt. Siehe Abschnitt 14.2.11, „Tipps zur Leistungssteigerung“.Auf Windows speichert
InnoDBDatenbank- und Tabellennamen intern immer in Kleinbuchstaben. Um Datenbanken im Binärformat von Unix auf Windows oder umgekehrt zu übertragen, sollten Sie immer explizit klein geschriebene Namen für Datenbanken und Tabellen verwenden.Für eine
AUTO_INCREMENT-Spalte müssen Sie immer einen Index für die Tabelle definieren, der nur dieseAUTO_INCREMENT-Spalte enthält. InMyISAM-Tabellen kann dieAUTO_INCREMENT-Spalte auch Teil eines Mehrspaltenindex sein.Wenn Sie den MySQL-Server neu starten, kann
InnoDBeinen alten Wert wiederverwenden, der für eineAUTO_INCREMENT-Spalte zwar angelegt, aber nie gespeichert wurde (also einen Wert, der während einer älteren Transaktion generiert wurde, die zurückgerollt worden ist).Wenn einer
AUTO_INCREMENT-Spalte die Werte ausgehen, brichtInnoDBeinenBIGINTauf-9223372036854775808undBIGINT UNSIGNEDauf1um. Da jedochBIGINT-Werte 64 Bits haben, würde es, selbst wenn Sie eine Million Zeilen pro Sekunde einfügten, immer noch fast dreihunderttausend Jahre dauern, bisBIGINTan seine Grenze stößt. Bei allen anderen Integerspalten würde ein Fehler wegen Schlüsselduplikat die Folge sein.MyISAMfunktioniert ähnlich, da dies im Wesentlichen dem normalen MySQL-Verhalten und nicht dem einer bestimmten Speicher-Engine entspricht.DELETE FROMgeneriert die Tabelle nicht neu, sondern löscht eine nach der anderen alle Zeilen.tbl_nameUnter bestimmten Gegebenheiten wird
TRUNCATEfür einetbl_nameInnoDB-Tabelle wieDELETE FROMbehandelt und setzt nicht dentbl_nameAUTO_INCREMENT-Zähler zurück. Siehe Abschnitt 13.2.9, „TRUNCATE“.In MySQL 5.1, erwirbt die MySQL-Operation
LOCK TABLESzwei Sperren auf jeder Tabelle, wenninnodb_table_locks=1(die Standardeinstellung). Zusätzlich zu einer Tabellensperre auf der MySQL-Ebene, errichtet es auch eineInnoDB-Tabellensperre. Ältere MySQL-Versionen errichteten keineInnoDB-Tabellensperren. Dieses alte Verhalten kann mitinnodb_table_locks=0eingestellt werden. Wenn keineInnoDB-Tabellensperre erworben wird, läuftLOCK TABLESauch dann, wenn einige Datensätze der Tabellen von anderen Transaktionen gesperrt sind.Alle
InnoDB-Sperren, die eine Transaktion hält, werden freigegeben, wenn die Transaktion committet oder abgebrochen wird. Also hat es wenig SinnLOCK TABLESaufInnoDB-Tabellen imAUTOCOMMIT=1-Modus aufzurufen, da dieInnoDB-Tabellensperren sofort freigegeben würden.Manchmal wäre es nützlich, im Laufe einer Transaktion noch weitere Tabellen zu sperren. Doch leider führt
LOCK TABLESin MySQL ein implizitesCOMMITundUNLOCK TABLESaus. Es ist eineInnoDB-Variante vonLOCK TABLESgeplant, die auch inmitten einer Transaktion ausgeführt werden kann.Die
LOAD TABLE FROM MASTER-Anweisung zum Einrichten eines Slaveservers für die Replikation funktioniert noch nicht mitInnoDB-Tabellen. Als Workaround können Sie die Tabelle auf dem Master inMyISAMkonvertieren, dann laden und hinterher die Mastertabelle wieder aufInnoDBumstellen. Dies geht jedoch nicht mit Tabellen, dieInnoDB-spezifische Features wie etwa Fremdschlüssel verwenden.Die Standardgröße für Datenbankseiten in
InnoDBbeträgt 16KB. Indem Sie den Code rekompilieren, können Sie Werte zwischen 8KB und 64KB einstellen. Sie müssen dazu die Werte vonUNIV_PAGE_SIZEundUNIV_PAGE_SIZE_SHIFTin der Quelldateiuniv.iändern.Trigger werden zurzeit noch nicht durch kaskadierende Fremdschlüsselaktionen aktiviert.
Die folgenden allgemeinen Richtlinien gelten für die Behebung von
InnoDB-Problemen:
Wenn eine Operation scheitert oder Sie einen Bug vermuten, schauen Sie in das Fehlerlog des MySQL-Servers. es ist die Datei im Data Directory, die das Suffix
.errträgt.Für die Problembehebung führen Sie MySQL am besten an der Eingabeaufforderung aus, anstatt durch den mysqld_safe-Wrapper oder als Windows-Dienst. Dann können Sie erkennen, was mysqld auf die Konsole ausgibt, und verstehen besser, was vor sich geht. Auf Windows müssen Sie den Server mit der
--console-Option starten, um die Ausgabe ans Konsolenfenster zu schicken.Nutzen Sie die
InnoDB-Monitore, um Informationen über ein Problem einzuholen (siehe Abschnitt 14.2.11.1, „Der InnoDB-Monitor“). Wenn es sich um ein Leistungsproblem handelt oder Ihr Server sich anscheinend aufgehängt hat, geben Sie mithilfe voninnodb_monitorInformationen über den internen Zustand vonInnoDBaus. Handelt es sich um ein Sperrenproblem, verwenden Sieinnodb_lock_monitor. Hat das Problem mit der Erzeugung von Tabellen oder mit anderen Data Dictionary-Operationen zu tun, geben Sie mithilfe voninnodb_table_monitorden Inhalt desInnoDB-internen Data Dictionary aus.Wenn Sie Tabellenschäden vermuten, führen Sie auf der betreffenden Tabelle
CHECK TABLEaus.
Ein besonderes Problem mit Tabellen besteht darin, dass der
MySQL-Server Data Dictionary-Informationen in
.frm-Dateien in Datenbankverzeichnissen
ablegt, während InnoDB die Informationen
auch in sein eigenes Data Dictionary innerhalb der
Tablespace-Dateien speichert. Wenn Sie
.frm-Dateien verschieben oder der Server
inmitten einer Data Dictionary-Operation abstürzt, kann es
geschehen, dass die Speicherorte der
.frm-Dateien hinterher nicht mehr zu den
Angaben im InnoDB-internen Data Dictionary
passen.
Eine gescheiterte CREATE TABLE-Anweisung ist
ein Symptom für ein nicht mehr synchrones Data Dictionary. Wenn
dies passiert, schauen Sie im Fehlerlog des Servers nach. Wird
dort behauptet, dass die Tabelle im
InnoDB-internen Data Dictionary bereits
existiert, so haben Sie in den
InnoDB-Tablespace-Dateien, eine verwaiste
Tabelle, zu der keine .frm-Datei gehört.
Die Fehlermeldung sieht wie folgt aus:
InnoDB: Error: table test/parent already exists in InnoDB internal InnoDB: data dictionary. Have you deleted the .frm file InnoDB: and not used DROP TABLE? Have you used DROP DATABASE InnoDB: for InnoDB tables in MySQL version <= 3.23.43? InnoDB: See the Restrictions section of the InnoDB manual. InnoDB: You can drop the orphaned table inside InnoDB by InnoDB: creating an InnoDB table with the same name in another InnoDB: database and moving the .frm file to the current database. InnoDB: Then MySQL thinks the table exists, and DROP TABLE will InnoDB: succeed.
Nach den Instruktionen der Fehlermeldung können Sie die
verwaiste Tabelle löschen. Wenn Sie DROP
TABLE immer noch nicht ausführen können, kann das
Problem auch an der AutoVervollständigung von Namen durch den
mysql-Client liegen. Um dieses zu verhindern,
starten Sie den mysql-Client mit der
--disable-auto-rehash-Option und versuchen noch
einmal Ihr DROP TABLE. (Bei eingeschalteter
Namensvervollständigung versucht mysql eine
Liste von Tabellennamen zu erstellen. Das scheitert, wenn ein
Problem wie das oben beschriebene auftritt.)
Ein anderes Symptom für ein nicht mehr synchrones Data
Dictionary liegt vor, wenn MySQL meldet, dass eine
.InnoDB-Datei nicht geöffnet werden kann:
ERROR 1016: Can't open file: 'child2.InnoDB'. (errno: 1)
Im Fehlerlog können Sie dann eine Nachricht wie diese vorfinden:
InnoDB: Cannot find table test/child2 from the internal data dictionary InnoDB: of InnoDB though the .frm file for the table exists. Maybe you InnoDB: have deleted and recreated InnoDB data files but have forgotten InnoDB: to delete the corresponding .frm files of InnoDB tables?
Dies bedeutet, dass Sie eine verwaiste
.frm-Datei haben, zu der es in
InnoDB keine Tabelle gibt. Die verwaiste
.frm-Datei können Sie dann manuell
löschen.
Wenn MySQL mitten in einer ALTER
TABLE-Operation abstürzt, haben Sie hinterher
vielleicht eine verwaiste temporäre Tabelle im
InnoDB-Tablespace. Mit
innodb_table_monitor sehen Sie dann eine
Tabelle namens #sql-... aufgeführt. Sie
können SQL-Anweisungen auf Tabellen ausführen, deren Name das
Zeichen ‘#’ enthält, wenn Sie
den Namen in Backticks setzen. So können Sie die verwaiste
Tabelle wie jede andere auch mit den zuvor beschriebenen
Methoden löschen. Achtung: Um eine Datei in der Unix-Shell zu
kopieren oder umzubenennen, müssen Sie den Dateinamen, wenn er
‘#’ enthält, in doppelte
Anführungszeichen setzen.
Eine MERGE-Tabelle, auch bekannt als
MRG_MyISAM, ist eine Sammlung identischer
MyISAM-Tabellen, die als eine einzige Tabelle
verwendet werden können. „Identisch“ bedeutet, dass
alle Tabellen dieselben Spalten- und Indexdaten haben. Sie können
keine MyISAM-Tabellen zusammenführen
(„mergen“) , in denen die Spalten oder Indizes in
einer unterschiedlichen Reihenfolge stehen, oder die nicht genau
gleich viele Spalten haben. Allerdings können alle
MyISAM-Tabellen mit
myisampack komprimiert werden. Siehe
Abschnitt 8.4, „myisampack — Erzeugung komprimierter, schreibgeschützter MyISAM Tabellen“. Unterschiede in den
Tabellenoptionen, wie beispielsweise
AVG_ROW_LENGTH, MAX_ROWS
oder PACK_KEYS spielen keine Rolle.
Wenn Sie eine MERGE-Tabelle anlegen, erzeugt
MySQL auf der Festplatte zwei Dateien, deren Namen jeweils mit dem
Tabellennamen beginnen und Erweiterungen haben, die den Dateityp
angeben. Eine .frm-Datei speichert das
Tabellenformat und eine .MRG-Datei enthält
die Namen der Tabellen, die wie eine einzige benutzt werden
sollen. Die Tabellen müssen nicht in derselben Datenbank
vorliegen wie die MERGE-Tabelle selbst.
Mit MERGE-Tabellen können Sie die Anweisungen
SELECT, DELETE,
UPDATE und INSERT verwenden.
Sie benötigen SELECT-,
UPDATE- und DELETE-Rechte
für die MyISAM-Tabellen, die Sie einer
MERGE-Tabelle zuordnen möchten.
Wenn Sie die MERGE-Tabelle mit
DROP löschen, löschen Sie damit nur die
MERGE-Spezifikation. Die zugrunde liegenden
Tabellen sind davon nicht betroffen.
Um eine MERGE-Tabelle anzulegen, müssen Sie in
einer
UNION=(
-Klausel angeben, welche list-of-tables)MyISAM-Tabellen Sie
als eine einzige benutzen möchten. Optional können Sie mit der
Option INSERT_METHOD erreichen, dass
Einfügeoperationen in der MERGE-Tabelle auf
der ersten oder der letzten Tabelle der
UNION-Liste stattfinden. Wenn Sie den Wert
FIRST einsetzen, geschieht die Einfügung in
der ersten, wenn Sie LAST einsetzen, in der
letzten Tabelle. Wenn Sie die
INSERT_METHOD-Option nicht oder nur mit dem
Wert NO angeben, zieht jeder Versuch, Zeilen in
die MERGE-Tabelle einzufügen, eine
Fehlermeldung nach sich.
Das folgende Beispiel zeigt, wie eine
MERGE-Tabelle angelegt wird:
mysql>CREATE TABLE t1 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>CREATE TABLE t2 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>INSERT INTO t1 (message) VALUES ('Testing'),('table'),('t1');mysql>INSERT INTO t2 (message) VALUES ('Testing'),('table'),('t2');mysql>CREATE TABLE total (->a INT NOT NULL AUTO_INCREMENT,->message CHAR(20), INDEX(a))->ENGINE=MERGE UNION=(t1,t2) INSERT_METHOD=LAST;
Der ältere Begriff TYPE wird aus Gründen der
Abwärtskompatibilität noch als Synonym für
ENGINE akzeptiert, doch
ENGINE ist der aktuelle Begriff, während
TYPE mittlerweile veraltet ist.
Beachten Sie, dass die Spalte a in den zugrunde
liegenden MyISAM-Tabellen ein PRIMARY
KEY ist, aber nicht in der
MERGE-Tabelle. Dort ist diese Spalte zwar auch
indiziert, aber nicht als PRIMARY KEY, da eine
MERGE-Tabelle für die ihr zugrunde liegenden
Tabellen keine Eindeutigkeit erzwingen kann.
Nachdem Sie die MERGE-Tabelle angelegt haben,
können Sie Anfragen schreiben, die auf der Tabellengruppe als
Ganzes operieren:
mysql> SELECT * FROM total;
+---+---------+
| a | message |
+---+---------+
| 1 | Testing |
| 2 | table |
| 3 | t1 |
| 1 | Testing |
| 2 | table |
| 3 | t2 |
+---+---------+
Beachten Sie, dass sich die .MRG-Datei direkt
von außerhalb des MySQL-Servers bearbeiten lässt:
shell>cd /shell>mysql-data-directory/current-databasels -1 t1 t2 > total.MRGshell>mysqladmin flush-tables
Um eine Neuzuordnung einer MERGE-Tabelle zu
einer anderen Gruppe von MyISAM-Tabellen zu
erzielen, gibt es folgende Methoden:
Sie löschen die
MERGE-Tabelle mitDROPund erstellen sie neu.Sie ändern die Liste der zugrunde liegenden Tabellen mit
ALTER TABLE.tbl_nameUNION=(...)Sie ändern die
.MRG-Datei und geben eineFLUSH TABLE-Anweisung für dieMERGE-Tabelle und alle zugrunde liegenden Tabellen aus, damit die Speicher-Engine die neue Definitionsdatei lesen muss.
MERGE-Tabellen können bei der Lösung
folgender Probleme behilflich sein:
Einfache Verwaltung einer Menge von Logtabellen. So können Sie zum Beispiel Daten verschiedener Monate in getrennte Tabellen laden, einige davon mit myisampack komprimieren und dann eine
MERGE-Tabelle anlegen, um das Ganze als ein einziges Log zu verwenden.Mehr Schnelligkeit. Sie können eine große, schreibgeschützte Tabelle nach bestimmten Kriterien aufspalten und die entstehenden Tabellen auf verschiedene Festplatten speichern. Mit einer
MERGE-Tabelle aus diesen Einzeltabellen haben Sie schnelleren Zugriff als mit der großen Ursprungstabelle.Effizienteres Suchen. Wenn Sie genau wissen, was Sie wollen, können Sie für manche Anfragen eine einzelne der aufgespaltenen Tabellen und für andere die
MERGE- Tabelle benutzen. Sie können sogar eine Vielzahl verschiedenerMERGE-Tabellen bilden, die zum Teil dieselben Einzeltabellen benutzen.Reparaturen werden effizienter. Es ist einfacher, kleinere Tabellen zu reparieren, die einer
MERGE-Tabelle zugeordnet sind, als eine einzige große Tabelle.Viele Tabellen können wie eine einzige sofort zugeordnet werden. Eine
MERGE-Tabelle benötigt keinen eigenen Index, da sie die Indizes der Einzeltabellen verwendet. Infolgedessen lassen sich Sammlungen vonMERGE-Tabellen sehr schnell erstellen oder neu zuordnen. (Beachten Sie, dass Sie trotzdem bei der Erstellung einerMERGE-Tabelle die Indexdefinitionen angeben müssen auch wenn keine Indizes angelegt werden.)Wenn Sie aus mehreren Tabellen nach Bedarf eine einzige, große Tabelle erstellen müssen, ist es günstiger, stattdessen eine
MERGE-Tabelle anzulegen. Diese ist viel schneller und spart eine Menge Speicherplatz.Mit
MERGE-Tabellen können Sie die Dateigrößenbeschränkung Ihres Betriebssystems umgehen. Eine einzelne, großeMyISAM-Tabelle würde durch dieses Limit begrenzt, aber eine Sammlung von kleinerenMyISAM-Tabellen nicht.Sie können einen Alias oder ein Synonym für eine
MyISAM-Tabelle anlegen, indem Sie eineMERGE-Tabelle definieren, der nur diese eine Tabelle zugeordnet ist. Der Einfluss auf die Leistung dürfte kaum spürbar sein (nur ein paar indirekte Aufrufe undmemcpy()-Aufrufe für jede Leseoperation).
Die Nachteile von MERGE-Tabellen sind:
Es dürfen nur identische
MyISAM-Tabellen für eineMERGE-Tabelle benutzt werden.Eine Reihe von
MyISAM-Features steht fürMERGE-Tabellen nicht zur Verfügung. Sie können zum Beispiel keineFULLTEXT-Indizes auf ihnen anlegen. (Es bleibt Ihnen natürlich unbenommen,FULLTEXT-Indizes auf den zugrunde liegendenMyISAM-Tabellen anzulegen, doch aber auf derMERGE-Tabelle können Sie keine Volltextsuche ausführen.)Wenn die
MERGE-Tabelle nicht-temporär ist, müssen auch die zugrunde liegendenMyISAM-Tabellen nicht-temporär sein. Ist dieMERGE-Tabelle hingegen temporär, können dieMyISAM-Tabellen eine beliebige Mixtur aus temporären und nicht-temporären Tabellen sein.MERGE-Tabellen verwenden mehr Dateideskriptoren. Wenn 10 Clients eineMERGE-Tabelle ansprechen, die ihrerseits 10 Tabellen abbildet, benutzt der Server (10 × 10) + 10 Dateideskriptoren. (10 Datendateideskriptoren für jeden der 10 Clients und 10 Indexdateideskriptoren, die von den Clients gemeinsam genutzt werden.)Lesevorgänge von Schlüsseln sind langsamer. Wenn Sie einen Schlüssel lesen, muss die
MERGE-Speicher-Engine eine Leseoperation auf allen zugrunde liegenden Tabellen ausführen, um festzustellen, welche dem gegebenen Schlüssel am besten entspricht. Um den nächsten Schlüssel zu lesen, muss dieMERGE-Speicher-Engine die Lesepuffer nach ihm durchsuchen. Erst wenn ein Schlüsselpuffer aufgebraucht ist, muss die Speicher-Engine den nächsten Schlüsselblock lesen. Das machtMERGE-Schlüssel ineq_ref-Suchen viel langsamer, aber nicht inref-Suchen. Unter Abschnitt 7.2.1, „EXPLAIN-Syntax (Informationen über einSELECTerhalten)“ finden Sie weitere Informationen übereq_refundref.
Ein spezielles Forum zur Speicher-Engine
MERGEfinden Sie unter http://forums.mysql.com/list.php?93.
Folgende Probleme mit MERGE-Tabellen sind
bekannt:
Wenn Sie mit
ALTER TABLEversuchen, eineMERGE-Tabelle in eine andere Speicher-Engine umzuwandeln, geht die Zuordnung der zugrunde liegenden Tabellen verloren. Stattdessen werden die Zeilen der zugrunde liegendenMyISAM-Tabellen in die geänderte Tabelle kopiert, die dann die neue Speicher-Engine verwendet.REPLACEfunktioniert nicht.DROP TABLE,ALTER TABLE,DELETEohneWHERE-Klausel,REPAIR TABLE,TRUNCATE TABLE,OPTIMIZE TABLEoderANALYZE TABLEdürfen auf keine Tabelle angewendet werden, die einer offenenMERGE-Tabelle zugeordnet ist. Wenn Sie dies tun, verweist dieMERGE-Tabelle später weiterhin auf die Originaltabelle, was zu unerwarteten Ergebnissen führen kann. Am einfachsten können Sie dieses Problem umgehen, indem Sie mit einerFLUSH TABLES-Anweisung vor diesen Operationen dafür sorgen, dass keineMERGE-Tabellen offen bleiben.Unter Windows funktioniert kein
DROP TABLEauf einer Tabelle, die gerade von einerMERGE-Tabelle benutzt wird, da die Tabellenzuordnung der Speicher-EngineMERGEvor der oberen Schicht von MySQL verborgen wird. Da Windows das Löschen geöffneter Dateien nicht gestattet, müssen Sie zuerst alleMERGE-Tabellen auf die Festplatte zurückschreiben (mitFLUSH TABLES) oder dieMERGE-Tabelle vor der anderen Tabelle löschen.Eine
MERGE-Tabelle kann keine Uniqueness Constraints über die gesamte Tabelle hinweg aufrecht erhalten. Wenn Sie einINSERTausführen, werden die Daten in die erste oder letzte derMyISAM-Tabellen geladen (je nach dem Wert der OptionINSERT_METHOD). MySQL gewährleistet die Eindeutigkeit von Unique-Keys innerhalb dieser einenMyISAM-Tabelle, aber nicht für die gesamte Tabellengruppe.Beim Anlegen einer
MERGE-Tabelle wird nicht geprüft, ob die zugrunde liegenden Tabellen existieren und gleich strukturiert sind. Wenn dieMERGE-Tabelle verwendet wird, prüft MySQL, ob alle zugeordneten Tabellen gleich lange Zeilen haben, aber narrensicher ist diese Überprüfung nicht. Legen Sie eineMERGE-Tabelle aus ungleichenMyISAM-Tabellen an, so müssen Sie sich auf ein paar seltsame Probleme gefasst machen.Die Reihenfolge der Indizes in der
MERGE-Tabelle und den ihr zugrunde liegenden Tabellen sollte gleich sein. Wenn Sie mitALTER TABLEeiner Tabelle, die in einerMERGE-Tabelle benutzt wird, einenUNIQUE-Index hinzufügen, und dann mit einem weiterenALTER TABLEderMERGE-Tabelle einen nicht-eindeutigen Index geben, ist die Reihenfolge der Indizes unterschiedlich, wenn auch die zugrunde liegende Tabelle zuvor bereits einen nicht-eindeutigen Index hatte. (Dazu kommt es, weilALTER TABLEUNIQUE-Indizes vor nicht-eindeutige Indizes setzt, um das schnelle Auffinden doppelter Schlüsselwerte zu erleichtern.) Infolgedessen können Anfragen von Tabellen mit solchen Indizes unerwartete Ergebnisse liefern.
Die Speicher-Engine MEMORY legt Tabellen mit
Inhalten an, die im Arbeitsspeicher gespeichert sind. Früher
wurden sie als HEAP-Tabellen bezeichnet. Heute
ist MEMORY der bevorzugte Ausdruck, auch wenn
HEAP aus Gründen der Abwärtskompatibilität
weiter unterstützt wird.
Zu jeder MEMORY-Tabelle gehört eine
Festplattendatei. Der Dateiname beginnt mit dem Tabellennamen und
hat die Erweiterung .frm, um anzuzeigen, dass
hier die Tabellendefinition (frm = form) gespeichert ist.
Um explizit eine MEMORY-Tabelle anzulegen,
geben Sie dies in der Tabellenoption ENGINE an:
CREATE TABLE t (i INT) ENGINE = MEMORY;
Der ältere Begriff TYPE wird aus Gründen der
Abwärtskompatibilität noch als Synonym für
ENGINE akzeptiert, doch
ENGINE ist der aktuelle Begriff, während
TYPE mittlerweile veraltet ist.
Wie der Name schon sagt, werden MEMORY-Tabellen
im Arbeitsspeicher gespeichert und sie benutzen nach
Voreinstellung einen gehashten Index. Das macht sie sehr schnell
und nützlich für temporäre Tabellen. Wenn allerdings der Server
abstürzt, gehen alle in MEMORY-Tabellen
gespeicherten Daten verloren. Die Tabellen selbst bestehen weiter,
da ihre Definitionen in .frm-Dateien auf der
Festplatte gespeichert sind, doch ihre Daten sind fort, wenn der
Server wieder hochfährt.
Das folgende Beispiel zeigt, wie eine
MEMORY-Tabelle erzeugt, benutzt und gelöscht
wird:
mysql>CREATE TABLE test ENGINE=MEMORY->SELECT ip,SUM(downloads) AS down->FROM log_table GROUP BY ip;mysql>SELECT COUNT(ip),AVG(down) FROM test;mysql>DROP TABLE test;
Kennzeichen von MEMORY-Tabellen:
Speicherplatz für
MEMORY-Tabellen wird in kleinen Blöcken zugewiesen. Die Tabellen verwenden 100% dynamisches Hashing für Einfügeoperationen. Es werden keine Overflow- Bereiche und kein zusätzlicher Platz für Schlüssel oder für Freelists benötigt. Gelöschte Zeilen werden in eine verkettete Liste geschrieben und wiederverwendet, wenn neue Daten in die Tabelle eingefügt werden.MEMORY-Tabellen haben auch keine Probleme mit Löschen plus Einfügen, was normalerweise bei gehashten Tabellen häufig vorkommt.MEMORY-Tabellen können bis zu 32 Indizes mit jeweils bis zu 16 Spalten und einer maximalen Schlüssellänge von 500 Bytes haben.Die Speicher-Engine
MEMORYimplementiert sowohlHASH- als auchBTREE-Indizes. Mit einerUSING-Klausel können Sie angeben, welchen von beiden Sie wünschen:CREATE TABLE lookup (id INT, INDEX USING HASH (id)) ENGINE = MEMORY; CREATE TABLE lookup (id INT, INDEX USING BTREE (id)) ENGINE = MEMORY;Die allgemeinen Merkmale von B-Baum- und Hash-Indizes werden in Abschnitt 7.4.5, „Wie MySQL Indizes benutzt“ beschrieben.
Es darf keine nicht-eindeutigen Schlüssel auf eine
MEMORY-Tabelle geben. (Dies ist ungebräuchlich für Implementierungen von Hash-Indizes.)Wenn Sie einen Hash-Index auf einer
MEMORY-Tabelle mit sehr vielen doppelten Schlüsseln haben (viele Indexeinträge enthalten denselben Wert), dann laufen Updates, die Schlüsselwerte betreffen, sowie sämtliche Löschoperationen deutlich langsamer. Wie viel langsamer, hängt von dem Ausmaß der Schlüsselduplikation ab (umgekehrt proportional zur Indexkardinalität). Um dieses Problem zu vermeiden, verwenden Sie einenBTREE-Index.Indizierte Spalten können
NULL-Werte enthalten.MEMORY-Tabellen verwenden ein Speicherformat mit fester Zeilenlänge.MEMORY-Tabellen dürfen keineBLOB- oderTEXT-Spalten enthalten.MEMORYunterstütztAUTO_INCREMENT-Spalten.INSERT DELAYEDkann mitMEMORY-Tabellen verwendet werden. Siehe Abschnitt 13.2.4.2, „INSERT DELAYED“.MEMORY-Tabellen werden von allen Clients gemeinsam genutzt (wie jede andere nicht-TEMPORARY-Tabelle).MEMORY-Tabellen speichern ihren Inhalt im Arbeitsspeicher, eine Eigenschaft, die sie mit internen Tabellen gemeinsam haben, die der Server bei der Verarbeitung von Anfragen nebenbei anlegt. Die beiden Tabellentypen unterscheiden sich jedoch darin, dassMEMORY-Tabellen im Gegensatz zu den internen Tabellen nicht von Speicherkonvertierung betroffen sind:Wenn eine interne Tabelle zu groß wird, konvertiert der Server sie automatisch in eine Festplattentabelle. Deren maximale Größe wird durch die Systemvariable
tmp_table_sizefestgelegt.MEMORY-Tabellen werden nie in Festplattentabellen konvertiert. Um sicherzustellen, dass Sie nicht versehentlich den gesamten Arbeitsspeicher benutzen, können Sie die Systemvariablemax_heap_table_sizeso einstellen, dass auchMEMORY-Tabellen einem Größenlimit unterliegen. Für einzelne Tabellen können Sie auch in derCREATE TABLE-Anweisung die TabellenoptionMAX_ROWS-Tabelle setzen.
Der Server benötigt genug Arbeitsspeicher, um alle
MEMORY-Tabellen zu pflegen, die zur selben Zeit gebraucht werden.Um den von einer
MEMORY-Tabelle belegten Speicher wieder freizugeben, wenn sie nicht länger benötigt wird, führen SieDELETEoderTRUNCATE TABLEaus oder löschen die Tabelle mitDROP TABLE.Möchten Sie beim Starten des MySQL-Servers Daten in eine
MEMORY-Tabelle laden, so können Sie die Option--init-filenutzen. In diese Datei können Sie Anweisungen wieINSERT INTO ... SELECToderLOAD DATA INFILEsetzen, um die Tabelle aus einer persistenten Datenquelle zu laden. Siehe Abschnitt 5.2.1, „Befehlsoptionen für mysqld“, and Abschnitt 13.2.5, „LOAD DATA INFILE“.Wenn Sie Replikation benutzen, werden die
MEMORY-Tabellen auf dem Masterserver auf Platte geschrieben, wenn dieser heruntergefahren und neu gestartet wird. Ein Slave merkt allerdings nicht, dass die Tabellen inzwischen leer sind, und gibt ihren alten Inhalt zurück, wenn Sie Daten von ihm abfragen. Wird eineMEMORY-Tabelle auf einem Master nach einem Neustart erstmals wieder genutzt, so wird automatisch eineDELETE-Anweisung in sein Binärlog geschrieben, um den Slave wieder mit ihm zu synchronisieren. Doch Vorsicht: Auch bei dieser Strategie hat der Slave in dem Zeitraum zwischen dem Neustart des Masters und seinem ersten Zugriff auf die Tabelle veraltete Daten im Speicher. Wenn Sie jedoch dieMEMORY-Tabelle gleich beim Hochfahren des Masters mithilfe der Option--init-filewieder mit Inhalt füllen, ist gewährleistet, dass dieser Zeitraum auf Null schrumpft.Der für eine Zeile in einer
MEMORY-Tabelle benötigte Speicher lässt sich mit folgendem Ausdruck berechnen:SUM_OVER_ALL_BTREE_KEYS(
max_length_of_key+ sizeof(char*) × 4) + SUM_OVER_ALL_HASH_KEYS(sizeof(char*) × 2) + ALIGN(length_of_row+1, sizeof(char*))ALIGN()ist ein Rundungsfaktor, der gewährleisten soll, dass die Zeilenlänge ein Vielfaches derchar-Pointergröße ist.sizeof(char*)ist auf 32-Bit-Rechnern gleich 4 und auf 64-Bit-Rechnern gleich 8.
Ein spezielles Forum zur Speicher-Engine
MEMORYfinden Sie unter http://forums.mysql.com/list.php?92.
Sleepycat Software hat für MySQL die transaktionssichere
Speicher-Engine Berkeley DB, kurz BDB,
bereitgestellt. BDB-Tabellen haben bessere
Chancen, einen Absturz zu überstehen, und können darüber hinaus
COMMIT- und
ROLLBACK-Operationen auf Transaktionen
durchführen.
BDB-Support ist in MySQL Quelldistributionen
enthalten und in MySQL-Max-Binärdistributionen aktiviert. Die
MySQL-Quelldistribution wird mit einer
BDB-Distribution ausgeliefert, die durch einen
Patch auf MySQL zugeschnitten ist. Für MySQL kann keine
nicht-gepatchte Version von BDB verwendet
werden.
MySQL AB arbeitet eng mit Sleepycat zusammen, um eine hochwertige MySQL/BDB-Schnittstelle zu gewährleisten. (Obgleich Berkeley DB selbst gründlich getestet und sehr zuverlässig ist, hat die MySQL-Schnittstelle immer noch Gamma-Qualität. Wir arbeiten weiter an ihrer Verbesserung und Optimierung.)
Wenn Probleme mit BDB-Tabellen auftreten, sind
wir bestrebt, unseren Benutzern beim Isolieren des Problems zu
helfen und reproduzierbare Testfälle zu erstellen. Alle
derartigen Testfälle werden an Sleepycat weitergeleitet, wo man
uns wiederum hilft, die Probleme zu finden und zu beheben. Da
dieser Vorgang in zwei Phasen abläuft, kann die Behebung von
Problemen mit BDB-Tabellen etwas länger dauern
als bei anderen Speicher-Engines. Wir denken jedoch nicht, dass es
mit diesem Vorgehen besondere Schwierigkeiten gibt, da der
Berkeley DB-Code selbst noch in vielen anderen Anwendungen als
MySQL läuft.
Allgemeine Informationen über Berkeley DB finden Sie auf der Sleepycat-Website http://www.sleepycat.com/.
Nach unserem derzeitigen Kenntnisstand funktioniert
BDB mit folgenden Betriebssystemen:
Linux 2.x Intel
Sun Solaris (SPARC und x86)
FreeBSD 4.x/5.x (x86, sparc64)
IBM AIX 4.3.x
SCO OpenServer
SCO UnixWare 7.1.x
Windows NT/2000/XP
Die Speicher-Engine BDB funktioniert
nicht auf folgenden Betriebssystemen:
Linux 2.x Alpha
Linux 2.x AMD64
Linux 2.x IA-64
Linux 2.x s390
Mac OS X
Hinweis: Diese Listen sind nicht vollständig. Sie werden bei Eintreffen neuer Informationen aktualisiert.
Wenn Sie MySQL aus der Quelle mit Unterstützung für
BDB-Tabellen erstellen, aber beim Starten mit
mysqld folgender Fehler auftritt, so bedeutet
dies, dass Ihre Rechnerarchitektur die
BDB-Speicher-Engine nicht unterstützt:
bdb: architecture lacks fast mutexes: applications cannot be threaded Can't init databases
In diesem Fall müssen Sie MySQL ohne
BDB-Unterstützung bauen oder den Server mit
der Option --skip-bdb starten.
Wenn Sie eine Binärversion von MySQL heruntergeladen haben, die
Unterstützung für Berkeley DB bietet, befolgen Sie einfach die
üblichen Installationsanweisungen für Binärdistributionen.
(MySQL-Max-Distributionen umfassen
BDB-Support.)
Erstellen Sie MySQL aus einer Quelldistribution, so können Sie
BDB-Unterstützung aktivieren, indem Sie beim
Aufruf von configure zusätzlich zu den
anderen Optionen, die Sie normalerweise verwenden, die Option
--with-berkeley-db einschalten. Laden Sie eine
MySQL-Distribution der Version 5.1 herunter, gehen
Sie in das oberste Verzeichnis und führen Sie folgenden Befehl
aus:
shell> ./configure --with-berkeley-db [other-options]
Weitere Informationen, Abschnitt 5.3, „mysqld-max, ein erweiterter mysqld-Server“, siehe Abschnitt 2.7, „Installation von MySQL auf anderen Unix-ähnlichen Systemen“ und Abschnitt 2.8, „Installation der Quelldistribution“.
Mit den folgenden mysqld-Optionen lässt sich
das Verhalten der Speicher-Engine BDB
ändern. Weitere Informationen siehe
Abschnitt 5.2.1, „Befehlsoptionen für mysqld“.
--bdb-data-directSchaltet für
BDB-Datenbankdateien den Systempuffer aus, um doppeltes Cachen zu verhindern. Diese Option wurde in MySQL 5.1.4 hinzugefügt.--bdb-home=pathDas Basisverzeichnis für
BDB-Tabellen. Es sollte dasselbe Verzeichnis sein, das auch für die--datadir-Option verwendet wird.--bdb-lock-detect=methodDie
BDB-Methode zur Erkennung von Sperren. Der Wert der Option istDEFAULT,OLDEST,RANDOM,YOUNGEST,MAXLOCKS,MINLOCKS,MAXWRITEoderMINWRITE.--bdb-log-directSchaltet für
BDB-Datenbankdateien den Systempuffer aus, um doppeltes Cachen zu verhindern. Diese Option wurde in MySQL 5.1.4 hinzugefügt.--bdb-logdir=file_nameDas Verzeichnis für
BDB-Logdateien.--bdb-no-recoverBerkeley DB nicht im Wiederherstellungsmodus starten.
--bdb-no-syncBDB-Logs nicht synchronisieren. Diese Option ist veraltet; bitte verwenden Sie stattdessen--skip-sync-bdb-logs(siehe Beschreibung von--sync-bdb-logs).--bdb-shared-dataBerkeley DB im Multi-Prozess-Modus starten. (Nicht beim Initialisieren von Berkeley DB
DB_PRIVATEbenutzen.)--bdb-tmpdir=pathName des temporären Dateiverzeichnisses von
BDB.--skip-bdbBDB-Speicher-Engine nicht benutzen.--sync-bdb-logsBDB-Logs synchronisieren. Diese Option ist standardmäßig aktiviert und kann mit--skip-sync-bdb-logsdeaktiviert werden.
Mit --skip-bdb initialisiert MySQL nicht die
BerkeleyDB-Bibliothek und spart deshalb viel Speicher.
Natürlich können Sie BDB-Tabellen nicht
benutzen, wenn Sie diese Option verwenden. Versuchen Sie
dennoch, eine BDB-Tabelle anzulegen, so
verwendet MySQL stattdessen die Standard-Speicher-Engine.
Normalerweise sollten Sie mysqld ohne die
Option --bdb-no-recover starten, wenn Sie
BDB-Tabellen benutzen möchten. Das kann
jedoch Probleme verursachen, wenn Sie mysqld
starten und die BDB-Logdateien beschädigt
sind. Siehe Abschnitt 2.9.2.3, „Probleme mit dem Start des MySQL Servers“.
Mit der Variablen bdb_max_lock können Sie
angeben, wie viele Sperren auf einer
BDB-Tabelle höchstens aktiv sein dürfen.
Der Standardwert beträgt 10.000. Sie können ihn heraufsetzen,
wenn Fehler wie der folgende bei langen Transaktionen auftreten,
oder wenn mysqld viele Zeilen betrachten
muss, um eine Anfrage auszuführen:
bdb: Lock table is out of available locks Got error 12 from ...
Außerdem sollten Sie die Variablen
binlog_cache_size und
max_binlog_cache_size ändern, wenn Sie
große, aus mehreren Anweisungen bestehende Transaktionen
ausführen. Siehe Abschnitt 5.12.3, „Die binäre Update-Logdatei“.
Jede BDB-Tabelle wird in zwei Dateien auf der
Festplatte gespeichert. Die Namen dieser Dateien setzen sich aus
dem Namen der Tabelle und einer Dateityperweiterung zusammen.
Eine .frm-Datei speichert das Format und
eine .db-Datei den Inhalt und die Indizes
der Tabelle.
Um explizit deutlich zu machen, dass Sie eine
BDB-Tabelle benötigen, verwenden Sie die
Tabellenoption ENGINE:
CREATE TABLE t (i INT) ENGINE = BDB;
Der ältere Begriff TYPE wird aus Gründen
der Abwärtskompatibilität noch als Synonym für
ENGINE akzeptiert, doch
ENGINE ist der aktuelle Begriff, während
TYPE mittlerweile veraltet ist.
BerkeleyDB ist ein Synonym für
BDB in der Tabellenoption
ENGINE.
Die Speicher-Engine BDB ermöglicht
transaktionssichere Tabellen. Wie diese benutzt werden, hängt
vom Autocommit-Modus ab:
Arbeiten Sie mit eingeschaltetem Autocommit (der Standard), werden Änderungen an
BDB-Tabellen sofort festgeschrieben (commit) und können nicht zurückgerollt werden.Arbeiten Sie mit ausgeschaltetem Autocommit, werden die Änderungen erst permanent, nachdem Sie eine
COMMIT-Anweisung ausgeführt haben. Stattdessen können Sie jedoch auch einROLLBACKausführen, um die Änderungen zu widerrufen.Eine Transaktion wird mit
START TRANSACTIONoderBEGINgestartet, um den Autocommit-Modus implizit auszusetzen, oder mitSET AUTOCOMMIT=0, um den Autocommit-Modus explizit auszuschalten.
Weitere Informationen über Transaktionen finden Sie unter
Abschnitt 13.4.1, „BEGIN/COMMIT/ROLLBACK“.
Die BDB-Speicher-Engine hat folgende
Merkmale:
BDB-Tabellen können bis zu 31 Indizes pro Tabelle, 16 Spalten pro Index und 1024 Bytes pro Schlüssel haben.MySQL erfordert einen Primärschlüssel in jeder
BDB-Tabelle, um auf jede Zeile eindeutig verweisen zu können. Wenn Sie nicht explizit einenPRIMARY KEYdeklarieren, erzeugt und wartet MySQL einen verborgenen Primärschlüssel. Dieser hat eine Länge von 5 Bytes und wird bei jedem Einfügeversuch um eins inkrementiert. Der Schlüssel erscheint nicht in der Ausgabe vonSHOW CREATE TABLEoderDESCRIBE.Der Primärschlüssel ist schneller als jeder andere Index, da er zusammen mit den Zeilendaten gespeichert wird. Da die anderen Indizes als Schlüsseldaten plus Primärschlüssel gespeichert werden, ist es wichtig, den Primärschlüssel möglichst kurz zu halten, um Plattenplatz zu sparen und eine höhere Geschwindigkeit zu erzielen.
Dieses Verhalten ist ähnlich wie das von
InnoDB, wo kürzere Primärschlüssel nicht nur im Primärindex, sondern auch in den Sekundärindizes Platz sparen.Wenn alle Spalten, auf die Sie in einer
BDB-Tabelle zugreifen, zu demselben Index oder zum Primärschlüssel gehören, kann MySQL die Anfrage ausführen, ohne auf die eigentliche Zeile zugreifen zu müssen. In einerMyISAM-Tabelle ist dies nur möglich, wenn die Spalten zu demselben Index gehören.Sequenzielles Scannen ist bei
BDB-Tabellen langsamer als beiMyISAM-Tabellen, da die Daten inBDB-Tabellen in B-Bäumen und nicht in einer separaten Datendatei gespeichert werden.Schlüsselwerte werden nicht Präfix- oder Suffix-komprimiert wie Schlüsselwerte in
MyISAM-Tabellen. Mit anderen Worten: Die Schlüsselinformationen benötigen inBDB-Tabellen etwas mehr Platz als inMyISAM-Tabellen.Oft gibt es Löcher in der
BDB-Tabelle, damit Sie neue Zeilen in der Mitte des Schlüsselbaums einfügen können. Das machtBDB-Tabellen etwas größer alsMyISAM-Tabellen.SELECT COUNT(*) FROMist beitbl_nameBDB-Tabellen langsam, da in der Tabelle kein Zeilenzähler gepflegt wird.Der Optimierer muss näherungsweise die Anzahl von Zeilen in der Tabelle kennen. MySQL löst dieses Problem, indem Einfügeoperationen gezählt werden, und unterhält diese in einem separaten Segment in jeder
BDB-Tabelle. Wenn Sie nicht vieleDELETE- oderROLLBACK-Anweisungen ausführen, sollte diese Zahl ausreichend genau für den MySQL-Optimierer sein. Da MySQL die Zahl nur beim Schließen speichert, kann sie falsch sein, wenn MySQL unerwartet beendet wird. Das sollte kein schwerer Fehler sein, selbst wenn die Zahl nicht zu 100% korrekt ist. Man kann die Anzahl von Zeilen aktualisieren, indem manANALYZE TABLEoderOPTIMIZE TABLEausführt. Siehe Abschnitt 13.5.2.1, „ANALYZE TABLE“ und Abschnitt 13.5.2.5, „OPTIMIZE TABLE“Internes Sperren in
BDB-Tabellen wird auf Seitenebene durchgeführt (page locking).LOCK TABLESfunktioniert beiBDB-Tabellen wie bei anderen Tabellen. Wenn SieLOCK TABLESnicht benutzen, errichtet MySQL eine interne Sperre für Mehrfach-Schreibvorgänge auf der Tabelle (eine Sperre, die andere Schreibvorgänge nicht blockiert), um sicherzustellen, dass die Tabelle korrekt gesperrt ist, wenn ein anderer Thread eine Tabellensperre ausführt.Um Transaktionen zurückrollen zu können, unterhält die
BDB-Speicher-Engine Logdateien. Um maximale Performance zu erzielen, sollten Sie diese auf andere Festplatten platzieren als Ihre Datenbanken, indem Sie die Option--bdb-logdirverwenden.MySQL macht jedes Mal, wenn eine neue
BDB-Logdatei gestartet wird, einen Checkpoint und entfernt alleBDB-Logdateien, die nicht für aktuelle Transaktionen benötigt werden. Sie können auch jederzeitFLUSH LOGSlaufen lassen, um einen Checkpoint für die Berkeley DB-Tabellen anzulegen.Für die Wiederherstellung nach Abstürzen sollten Sie Datensicherungen der Tabellen plus das Binärlog von MySQL benutzen. Siehe Abschnitt 5.10.1, „Datenbank-Datensicherungen“.
Achtung: Wenn Sie alte Logdateien löschen, die noch in Gebrauch sind, ist
BDBnicht in der Lage, Wiederherstellungen durchzuführen, und Sie könnten Daten verlieren, wenn etwas schief geht.Die Anwendung muss stets darauf vorbereitet sein, Fälle zu handhaben, bei denen jegliche Änderung einer
BDB-Tabelle zu einem automatischen Rollback führen kann und jegliches Lesen fehlschlagen kann, weil ein Deadlock auftritt.Wenn die Platte bei einer
BDB-Tabelle voll wird, wird ein Fehler gemeldet (wahrscheinlich Fehler 28) und die Transaktion sollte zurückgerollt werden. Im Gegensatz dazu wartet beiMyISAM-Tabellen der Server darauf, dass genügend Plattenplatz frei ist, ehe er fortfährt.
Im Folgenden werden Einschränkungen aufgeführt, die Sie bei
der Verwendung von BDB-Tabellen beachten
müssen:
Jede
BDB-Tabelle speichert in ihrer.db-Datei den Pfad, mit dem sie angelegt wurde. Dies wird getan, um die Erkennung von Sperren in Mehrbenutzerumgebungen zu ermöglichen, in denen Symlinks unterstützt werden. Infolgedessen ist es nicht möglich,BDB-Tabellendateien von einem Datenbankverzeichnis in ein anderes zu verlagern.Wenn Sie
BDB-Tabellen sichern, müssen Sie entweder mysqldump verwenden oder eine Sicherung anlegen, die Dateien für jedeBDB-Tabelle (also die.frm- und die.db-Dateien) sowie dieBDB-Logdateien speichert. Die Speicher-EngineBDBspeichert unvollendete Transaktionen in ihren Logdateien und erfordert, dass diese beim Starten von mysqld präsent sind. DieBDB-Logs sind die Dateien im Data Directory, deren Namen die Formlog.haben (zehn Ziffern).NNNNNNNNNNWenn eine Spalte, die
NULL-Werte zulässt, einen eindeutigen Index hat, darf nur ein einzigerNULL-Wert vorhanden sein. Im Gegensatz dazu erlauben andere Speicher-Engines auch mehrereNULL-Werte in Unique-Indizes.
Wenn Sie mysqld nach einem Upgrade starten und folgenden Fehler erhalten, so bedeutet dies, dass die neue Version von
BDBdas alte Logdateiformat nicht mehr unterstützt:bdb: Ignoring log file: .../log.
NNNNNNNNNN: unsupported log version #In diesem Fall müssen Sie alle
BDB-Logs aus Ihrem Datenverzeichnis löschen (also die Dateien, deren Namen die Formlog.haben) und mysqld neu starten. Außerdem sollten Sie mit mysqldump --opt IhreNNNNNNNNNNBDB-Tabellen dumpen, löschen und dann aus der Dump-Datei rekonstruieren.Wenn Sie bei ausgeschaltetem Autocommit eine
BDB-Tabelle löschen, die in einer anderen Transaktion verwendet wird, wird vielleicht eine Fehlermeldung wie die folgende in Ihr MySQL-Fehlerlog geschrieben:001119 23:43:56 bdb: Missing log fileid entry 001119 23:43:56 bdb: txn_abort: Log undo failed for LSN: 1 3644744: InvalidDas ist zwar nicht fatal, lässt sich aber auch nicht ganz einfach beheben. So lange dieses Problem noch nicht behoben ist, raten wir Ihnen,
BDB-Tabellen nur bei eingeschaltetem Autocommit zu löschen.
Die Speicher-Engine EXAMPLE ist eine
Sockel-Engine, die eigentlich gar nichts tut, sondern einzig als
Beispiel im MySQL-Quellcode dienen soll, um zu veranschaulichen,
wie man neue Speicher-Engines erstellt. Sie ist vor allem für
Entwickler von Interesse.
Die Speicher-Engine EXAMPLE ist in den
MySQL-Max-Binärdistributionen enthalten. Wenn Sie MySQL von der
Quelldistribution bauen, können Sie diese Speicher-Engine
aktivieren, indem Sie configure mit der Option
--with-example-storage-engine aufrufen.
Die Quelle für die EXAMPLE-Engine finden Sie
im Verzeichnis storage/example der
MySQL-Quelldistribution.
Wenn Sie eine EXAMPLE-Tabelle anlegen, erstellt
der Server eine Tabellen-Formatdatei im Datenbankverzeichnis. Die
Datei beginnt mit dem Tabellennamen und hat die Erweiterung
.frm. Andere Dateien werden nicht erzeugt und
Daten können in der Tabelle auch nicht gespeichert werden.
Anfragen geben eine leere Ergebnismenge zurück.
mysql>CREATE TABLE test (i INT) ENGINE = EXAMPLE;Query OK, 0 rows affected (0.78 sec) mysql>INSERT INTO test VALUES(1),(2),(3);ERROR 1031 (HY000): Table Speicher-Engine for 'test' doesn't have this option mysql>SELECT * FROM test;Empty set (0.31 sec)
Die Speicher-Engine EXAMPLE unterstützt keine
Indizierung.
Die Speicher-Engine FEDERATED greift auf Daten
in entfernten Datenbanktabellen (auf anderen Hosts) zu, nicht in
lokalen Tabellen.
Die Speicher-Engine FEDERATED ist in
MySQL-Max-Binärdistributionen enthalten. Wenn Sie MySQL von der
Quelldistribution bauen, können Sie diese Speicher-Engine
aktivieren, indem Sie configure mit der Option
--with-federated-storage-engine aufrufen.
Die Quelle für die FEDERATED-Engine finden Sie
im Verzeichnis sql einer
MySQL-Quelldistribution.
Ein spezielles Forum zur Speicher-Engine
FEDERATEDfinden Sie unter http://forums.mysql.com/list.php?105.
Wenn Sie eine FEDERATED-Tabelle anlegen,
erzeugt der Server eine Tabellen-Formatdatei im
Datenbankverzeichnis. Die Datei beginnt mit dem Tabellennamen
und hat die Erweiterung .frm. Andere
Dateien werden nicht angelegt, da die eigentlichen Daten in
einer Remote-Tabelle vorliegen. Das steht im Gegensatz zu den
Speicher-Engines für lokale Tabellen.
Für lokale Datenbanktabellen liegen auch die Datendateien lokal
vor. Wenn Sie beispielsweise eine
MyISAM-Tabelle namens
users anlegen, erzeugt der
MyISAM-Handler eine Datendatei namens
users.MYD. Ein Handler für lokale Tabellen
liest, ergänzt, löscht und aktualisiert Daten in lokalen
Datendateien und die Zeilen werden in einem für den Handler
spezifischen Format gespeichert. Um Datenzeilen zu lesen, muss
der Handler die Daten in Spalten parsen, und um Zeilen zu
schreiben, müssen die Spaltenwerte in das vom Handler benutzte
Zeilenformat umgewandelt und in die lokale Datendatei
geschrieben werden.
Doch bei der MySQL-Speicher-Engine FEDERATED
existieren lokal keine Datendateien für eine Tabelle (es gibt
beispielsweise keine .MYD-Datei).
Stattdessen speichert eine entfernte Datenbank die Daten, die
normalerweise in der Tabelle vorliegen würden. Der lokale
Server verbindet sich mit einem entfernten Server und liest,
löscht, aktualisiert und ergänzt die Daten in der entfernten
Tabelle über eine MySQL-API. Abgefragt werden die Daten mit
einer SELECT * FROM
-SQL-Anweisung. Um
das Ergebnis zu lesen, werden die Zeilen eine nach der anderen
mit der C-API-Funktion tbl_namemysql_fetch_row()
abgeholt. Danach werden die Spalten der
SELECT-Ergebnismenge in das vom
FEDERATED-Handler erwartete Format
umgewandelt.
Der Informationsfluss ist wie folgt:
Lokaler SQL-Aufruf
MySQL-Handler-API (Daten im Format des Handlers)
MySQL-Client-API (Daten werden in SQL-Aufrufe konvertiert)
Remote-Datenbank -> MySQL-Client-API
Ergebnismengen (sofern vorhanden) werden in Handler-Format konvertiert
Handler-API -> Ergebniszeilen oder Zahl der betroffenen Zeilen werden lokal angegeben
Das Verfahren zur Benutzung der
FEDERATED-Tabellen ist sehr einfach.
Normalerweise betreiben Sie zwei Server, entweder auf demselben
oder auf verschiedenen Hosts. (Es ist möglich, allerdings nicht
sehr sinnvoll, dass eine FEDERATED-Tabelle
eine andere Tabelle verwendet, die von demselben Server
verwaltet wird.)
Zuerst muss auf dem Remote-Server eine Tabelle liegen, auf die
Sie mit einer FEDERATED-Tabelle zugreifen
möchten. Angenommen, die entfernte Tabelle liegt in der
Datenbank federated und ist folgendermaßen
definiert:
CREATE TABLE test_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=MyISAM
DEFAULT CHARSET=latin1;
Im Beispiel wird eine MyISAM-Tabelle
verwendet, aber es könnte auch eine andere Speicher-Engine
benutzt werden.
Nun erstellen Sie eine FEDERATED-Tabelle auf
dem lokalen Server, um auf die entfernte Tabelle zuzugreifen:
CREATE TABLE federated_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='mysql://root@remote_host:9306/federated/test_table';
(Hinweis:
CONNECTION ersetzt
COMMENT, was in früheren MySQL-Versionen
verwendet wurde.)
Die Struktur dieser Tabelle muss der Struktur der entfernten
Tabelle genau entsprechen, nur die Tabellenoption
ENGINE ist FEDERATED und
die Tabellenoption CONNECTION ist ein
Verbindungsstring, welcher der
FEDERATED-Engine sagt, wie sie sich mit dem
entfernten Server verbinden kann.
Die FEDERATED-Engine erzeugt in der
federated-Datenbank nur die
test_table.frm-Datei.
Die Remote-Host-Daten geben an, mit welchem entfernten Server
sich Ihr lokaler Server verbindet, und die Datenbank- und
Tabelleninformationen geben an, welche entfernte Tabelle als
Datenquelle verwendet werden soll. Da im vorliegenden Beispiel
der entfernte Server als remote_host auf Port
9306 definiert ist, muss ein MySQL-Server auf dem Remote-Host
laufen und auf Port 9306 lauschen.
Die allgemeine Form eines Verbindungsstrings in der Option
CONNECTION ist:
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
Vorläufig wird nur mysql als Wert für
scheme akzeptiert. Das Passwort und
die Port-Nummer sind optional.
Im Folgenden sehen Sie einige Beispiele für Verbindungsstrings:
CONNECTION='mysql://username:password@hostname:port/database/tablename' CONNECTION='mysql://username@hostname/database/tablename' CONNECTION='mysql://username:password@hostname/database/tablename'
CONNECTION ist für die Angabe des
Verbindungsstrings nicht optimal geeignet und wird
wahrscheinlich irgendwann ersetzt. Für Anwendungen mit
FEDERATED-Tabellen müssen Sie sich daher
merken, dass diese Anwendungen modifiziert werden müssen, wenn
sich das Format für die Verbindungsinformationen eines Tages
ändert.
Da jedes Passwort, das Sie im Verbindungsstring angeben, als
einfacher Text gespeichert wird, ist es für jeden Benutzer
ersichtlich, der SHOW CREATE TABLE oder
SHOW TABLE STATUS für die
FEDERATED-Tabelle ausführen oder die
TABLES-Tabelle in der
INFORMATION_SCHEMA-Datenbank abfragen darf.
Die folgenden Features werden von der Speicher-Engine
FEDERATED unterstützt bzw. nicht
unterstützt:
In der vorliegenden Version muss der entfernte Server ein MySQL-Server sein. In Zukunft wird
FEDERATEDmöglicherweise auch andere Datenbank-Engines unterstützen.Die entfernte Tabelle, die von einer
FEDERATED-Tabelle benutzt wird, muss vorhanden sein, bevor Sie mitFEDERATEDversuchen, auf sie zuzugreifen.Es ist möglich, mit einer
FEDERATED-Tabelle auf eine andere zu verweisen, aber bitte achten Sie darauf, keine Endlosschleife zu erzeugen.FEDERATEDunterstützt keine Transaktionen.Die
FEDERATED-Engine kann nicht wissen, ob die entfernte Tabelle sich geändert hat. Der Grund dafür: Diese Tabelle muss wie eine Datendatei funktionieren, in die niemand anders als die Datenbank schreiben kann. Die Datenintegrität in der lokalen Tabelle könnte beschädigt werden, wenn sich in der entfernten Datenbank etwas ändert.Die
FEDERATED-Speicher-Engine unterstütztSELECT,INSERT,UPDATE,DELETEund Indizes. Nicht unterstützt werdenALTER TABLE,DROP TABLEoder andere Data Definition Language-Anweisungen. Die aktuelle Implementierung verwendet keine vorbereiteten Anweisungen (Prepared-Statements).Die Implementierung verwendet
SELECT,INSERT,UPDATEundDELETE, aber nichtHANDLER.FEDERATED-Tabellen arbeiten nicht mit dem Anfragen-Cache.
Manche dieser Beschränkungen werden vielleicht in künftigen
Versionen des FEDERATED-Handlers entfallen.
Die Speicher-Engine ARCHIVE dient der
Speicherung großer Datenmengen ohne Indizes mit einem sehr
kleinen Speicherbedarf.
Die Speicher-Engine ARCHIVE ist in den
Binärdistributionen von MySQL enthalten. Wenn Sie MySQL aus der
Quelldistribution bauen, aktivieren Sie diese Speicher-Engine,
indem Sie configure mit der Option
--with-archive-storage-engine aufrufen.
Die Quelle für die ARCHIVE-Engine finden Sie
im Verzeichnis storage/archive der
MySQL-Quelldistribution.
Ob die ARCHIVE-Engine zur Verfügung steht,
prüfen Sie mit folgender Anweisung:
mysql> SHOW VARIABLES LIKE 'have_archive';
Wenn Sie eine ARCHIVE-Tabelle anlegen, erzeugt
der Server eine Tabellen-Formatdatei im Datenbankverzeichnis. Die
Datei beginnt mit dem Tabellennamen und hat die
Erweiterung.frm. Die Speicher-Engine legt
noch weitere Dateien an, deren Namen alle mit dem Tabellennamen
anfangen. Die Datendateien haben die Erweiterung
.ARZ und die Metadatendateien die Erweiterung
.ARM. Eine .ARN-Datei
kann bei Optimierungsoperationen erscheinen.
Die ARCHIVE-Engine unterstützt
INSERT und SELECT, aber
nicht DELETE, REPLACE oder
UPDATE. Sie unterstützt ORDER
BY-Operationen, BLOB-Spalten und im
Grunde alle Datentypen außer den raumbezogenen (Spatial-Daten)
(siehe Abschnitt 18.4.1, „Raumbezogene Datentypen in MySQL“). Außerdem nutzt
ARCHIVE Zeilensperren.
Seit MySQL 5.1.6 unterstützt ARCHIVE das
AUTO_INCREMENT-Spaltenattribut. Die
AUTO_INCREMENT-Spalten können einen
eindeutigen oder einen nicht-eindeutigen Index haben. Der Versuch,
einen Index auf einer anderen Spalte anzulegen, führt zu einem
Fehler. Außerdem unterstützt ARCHIVE die
Tabellenoption AUTO_INCREMENT in
CREATE TABLE- und ALTER
TABLE-Anweisungen. So kann der erste Wert der Folge für
eine neue Tabelle angegeben oder für eine vorhandene Tabelle
zurückgesetzt werden.
Seit MySQL 5.1.6 ignoriert die ARCHIVE-Engine
BLOB-Spalten, wenn diese nicht angefordert
werden, und übergeht sie beim Lesen. Früher bedeuteten die
folgenden beiden Anweisungen denselben Aufwand, doch seit der
Version 5.1.6 ist die zweite viel effizienter als die erste:
SELECT a, b, blob_col FROM archive_table; SELECT a, b FROM archive_table;
Speicherung: Zeilen werden beim
Einfügen komprimiert. ARCHIVE verwendet
verlustfreie zlib-Datenkompression (siehe
http://www.zlib.net/). Mit OPTIMIZE
TABLE können Sie die Tabelle analysieren und in ein
kleineres Format packen (einen Grund zur Verwendung von
OPTIMIZE TABLE finden Sie weiter unten in
diesem Abschnitt). Außerdem unterstützt diese Engine
CHECK TABLE. Mehrere verschiedene Arten von
Einfügungen sind möglich:
Eine
INSERT-Anweisung schiebt die Zeilen einfach in einen Kompressionspuffer, der nach Bedarf auf die Platte zurückgeschrieben wird. Die Einfügung von Daten in den Puffer ist durch eine Sperre geschützt. MitSELECTwird das Schreiben auf die Festplatte erzwungen, sofern nicht nurINSERT DELAYED-Einfügungen vorgekommen waren (diese werden nur nach Bedarf auf die Platte geschrieben). Siehe Abschnitt 13.2.4.2, „INSERT DELAYED“.Eine Massen-Einfügeoperation (bulk insert) wird erst nach ihrem Abschluss sichtbar, wenn nicht gleichzeitig andere Einfügungen auftreten: In diesem Fall wird sie teilweise sichtbar. Ein
SELECThat normalerweise nicht zur Folge, dass eine Massen-Einfügeoperation auf die Festplatte geschrieben wird, es sei denn, eine normale Einfügeoperation tritt auf, während die andere gerade geladen wird..
Anfragen: Bei Anfragen werden die
Zeilen nach Bedarf dekomprimiert; es gibt keinen Zeilen-Cache.
Eine SELECT-Operation führt einen kompletten
Tabellen-Scan durch: Wenn ein SELECT auftritt,
stellt es fest, wie viele Zeilen gerade zur Verfügung stehen und
liest diese Anzahl Zeilen. SELECT wird als
konsistente Leseoperation durchgeführt. Beachten Sie, dass viele
SELECT-Anweisungen während einer
Einfügeoperation die Datenkompression schwächt, es sei denn, Sie
verwenden nur Massen- oder verzögerte Einfügungen. Eine bessere
Kompression können Sie mit OPTIMIZE TABLE oder
REPAIR TABLE erzielen. Die Anzahl der Zeilen,
die SHOW TABLE STATUS für
ARCHIVE-Tabellen meldet, ist immer korrekt.
Siehe Abschnitt 13.5.2.5, „OPTIMIZE TABLE“,
Abschnitt 13.5.2.6, „REPAIR TABLE“ und
Abschnitt 13.5.4.21, „SHOW TABLE STATUS“.
Ein spezielles Forum zur Speicher-Engine
ARCHIVEfinden Sie unter http://forums.mysql.com/list.php?112.
Die CSV-Speicher-Engine speichert Daten in
Textdateien im Format von kommagetrennten Werten (Comma Separated
Values, CSV).
Um diese Speicher-Engine zu aktivieren, verwenden Sie
configure mit der Option
--with-csv-storage-engine, wenn Sie MySQL bauen.
Die Speicher-Engine CSV ist in MySQL-Max-
Binärdistributionen enthalten. Wenn Sie MySQL von einer
Quelldistribution bauen, können Sie sie aktivieren, indem Sie
configure mit der Option
--with-csv-storage-engine aufrufen.
Die Quelle für die CSV-Engine finden Sie im
Verzeichnis storage/csv einer MySQL-
Quelldistribution.
Wenn Sie eine CSV-Tabelle anlegen, erstellt der
Server eine Tabellen-Formatdatei im Datenbankverzeichnis. Die
Datei beginnt mit dem Tabellennamen und hat die Erweiterung
.frm. Außerdem legt die Speicher-Engine eine
Datendatei an, deren Name mit dem Tabellennamen anfängt und die
Erweiterung .CSV hat. Die Datendatei ist eine
einfache Textdatei. Wenn Sie Daten in der Tabelle speichern,
schreibt die Engine sie im CVS-Format in die Datei.
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = CSV;Query OK, 0 rows affected (0.12 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;+------+------------+ | i | c | +------+------------+ | 1 | record one | | 2 | record two | +------+------------+ 2 rows in set (0.00 sec)
Wenn Sie die mit der obigen Anweisung im Datenbankverzeichnis
erzeugte Datei test.CSV anschauen, müsste
sie folgenden Inhalt haben:
"1","record one" "2","record two"
Die Speicher-Engine CSV unterstützt keine
Indizierung.
Die Speicher-Engine BLACKHOLE ist wie ein
„Schwarzes Loch“, das Daten zwar entgegennimmt, aber
nicht speichert. Anfragen geben immer eine leere Ergebnismenge
zurück:
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;Query OK, 0 rows affected (0.03 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;Empty set (0.00 sec)
Die Speicher-Engine BLACKHOLE ist in MySQL-Max-
Binärdistributionen enthalten. Wenn Sie MySQL von einer
Quelldistribution bauen, können Sie sie aktivieren, indem Sie
configure mit der Option
--with-blackhole-storage-engine aufrufen.
Die Quelle für die BLACKHOLE-Engine finden Sie
im Verzeichnis sql einer MySQL-
Quelldistribution.
Wenn Sie eine BLACKHOLE-Tabelle anlegen,
erstellt der Server eine Tabellen-Formatdatei im
Datenbankverzeichnis. Die Datei beginnt mit dem Tabellennamen und
hat die Erweiterung .frm. Andere Dateien
werden mit der Tabelle nicht verknüpft.
Die BLACKHOLE-Speicher-Engine unterstützt alle
Arten von Indizes. Das bedeutet, dass Sie Indexdeklarationen in
die Tabellendefinition aufnehmen können.
Ob BLACKHOLE zur Verfügung steht, prüfen Sie
mit folgender Anweisung:
mysql> SHOW VARIABLES LIKE 'have_blackhole_engine';
Bei Einfügungen in eine BLACKHOLE-Tabelle
werden keine Daten gespeichert, doch wenn das Binärlog aktiviert
ist, werden die SQL-Anweisungen protokolliert (und auf die
Slaveserver repliziert). Das kann als Wiederholungs- oder
Filtermechanismus ganz nützlich sein. Nehmen wir zum Beispiel an,
Ihre Anwendung benötigt Filterregeln auf der Slave-Seite, aber
eine Übertragung sämtlicher Logdaten auf den Slave würde zu
viel Traffic verursachen. In solchen Fällen kann auf dem
Master-Host ein „Dummy“-Slave-Prozess mit
BLACKHOLE als Speicher-Engine eingerichtet
werden:
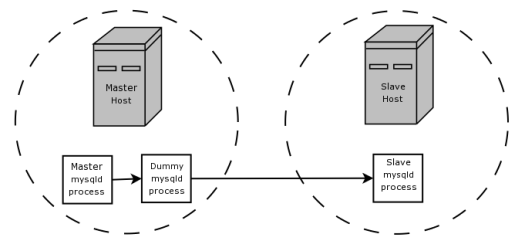
Der Master schreibt in sein Binärlog und der als Slave
fungierende „Dummy“-mysqld-Prozess
wendet die gewünschte Kombination von
replicate-do-*- und
replicate-ignore-*-Regeln an und schreibt ein
eigenes gefiltertes Binärlog. (Siehe
Abschnitt 6.9, „Replikationsoptionen in my.cnf“.) Dieses gefilterte Log wird
dann dem Slave zur Verfügung gestellt.
Da der Dummy-Prozess selbst gar keine Daten speichert, entsteht durch den zusätzlichen mysqld-Prozess auf dem Replikations-Master-Host kaum Verarbeitungs-Overhead. Dieser Mechanismus kann mit weiteren Replikations-Slaves wiederholt werden.
Andere mögliche Einsatzgebiete für BLACKHOLE
sind:
Syntaxprüfung für Dump-Dateien.
Sie können den Overhead für Binärlogs messen, indem Sie die Performance eines
BLACKHOLEs mit und ohne Binärlog vergleichen.Da
BLACKHOLEim Grunde eine „leere“ Speicher-Engine ist, könnte sie eingesetzt werden, um Leistungsengpässe ausfindig zu machen, die nicht mit der Speicher-Engine selbst zusammenhängen.
Seit MySQL 5.1.4 kann die BLACKHOLE-Engine mit
Transaktionen umgehen, und zwar in dem Sinne, dass sie bestätigte
Transaktionen in das Binärlog schreibt und zurückgerollte nicht.