Inhaltsverzeichnis
- 16.1. MySQL Cluster: Überblick
- 16.2. MySQL Cluster: grundlegende Konzepte
- 16.3. Einfache Schritt-für-Schritt-Anleitung für mehrere Computer
- 16.4. MySQL Cluster: Konfiguration
- 16.5. Prozessverwaltung in MySQL Cluster
- 16.6. Management von MySQL Cluster
- 16.7. Verwendung von Hochgeschwindigkeits-Interconnects mit MySQL Cluster
- 16.8. Bekannte Beschränkungen von MySQL Cluster
- 16.9. MySQL Cluster: Roadmap für die Entwicklung
- 16.10. MySQL Cluster: FAQ
- 16.11. MySQL Cluster: Glossar
MySQL Cluster ist eine hochverfügbare und hochredundante Version
von MySQL, die für verteilte Umgebungen geschaffen wurde. Die
Speicher-Engine NDB Cluster ermöglicht den
Betrieb mehrerer MySQL Server in einem Cluster. Diese
Speicher-Engine ist in den Binär-Releases von MySQL
5.1 und in den RPMs verfügbar, die mit den meisten
modernen Linux-Distributionen kompatibel sind. (Wenn Sie RPM-Dateien
installieren, müssen Sie darauf achten, sowohl die
mysql-server- als auch die
mysql-max-RPMs zu installieren, um MySQL Cluster
zu ermöglichen.)
Gegenwärtig ist MySQL Cluster für Linux, Mac OS X und Solaris verfügbar. (Manche Anwender haben MySQL Cluster auch auf FreeBSD mit Erfolg installieren können, doch dieses System wird von der MySQL AB noch nicht offiziell unterstützt.) Wir arbeiten daran, Cluster auf allen von MySQL unterstützten Betriebssystemen einschließlich Windows lauffähig zu machen, und werden diese Seite aktualisieren, wenn ein neues Betriebssystem hinzukommt.
Dieses Kapitel ändert sich noch laufend; sein Inhalt wird immer wieder an den aktuellen Stand von MySQL Cluster angepasst. Weitere Informationen über MySQL Cluster finden Sie auf der Website von MySQL AB unter http://www.mysql.com/products/cluster/.
Antworten auf häufig gestellte Fragen zum Thema Cluster finden Sie unter Abschnitt 16.10, „MySQL Cluster: FAQ“.
Die Mailingliste zu MySQL Cluster: http://lists.mysql.com/cluster.
Das MySQL Cluster-Forum: http://forums.mysql.com/list.php?25.
Wenn Sie MySQL Cluster noch nicht kennen, ist eventuell der folgende Artikel aus unserer Developer Zone für Sie interessant: How to set up a MySQL Cluster for two servers.
MySQL Cluster ist eine Technologie für das Clustering von speicherresidenten Datenbanken in einem Share-Nothing-System. Mit der Share-Nothing-Architektur kann das System auf sehr preiswerter Hardware laufen und es gibt keine besonderen Anforderungen an Hardware oder Software. Überdies ist kein Single Point of Failure vorhanden, da jede Komponente ihren eigenen Arbeitsspeicher und ihre Festplatte hat.
MySQL Cluster integriert den normalen MySQL Server in eine
speicherresidente geclusterte Speicher-Engine namens
NDB. In unserer Dokumentation bezeichnet der
Begriff NDB den Teil des Setups, der für die
jeweilige Speicher-Engine spezifisch ist, während mit
„MySQL Cluster“ die Kombination aus MySQL und der
Speicher-Engine NDB gemeint ist.
Ein MySQL Cluster besteht aus mehreren Computern, auf denen jeweils eine Anzahl Prozesse laufen, darunter MySQL Server, Datenknoten für NDB Cluster, Management-Server und (möglicherweise) besondere Programme für den Datenzugriff. Im Folgenden wird gezeigt, wie diese Komponenten in einem Cluster zueinander in Beziehung stehen:
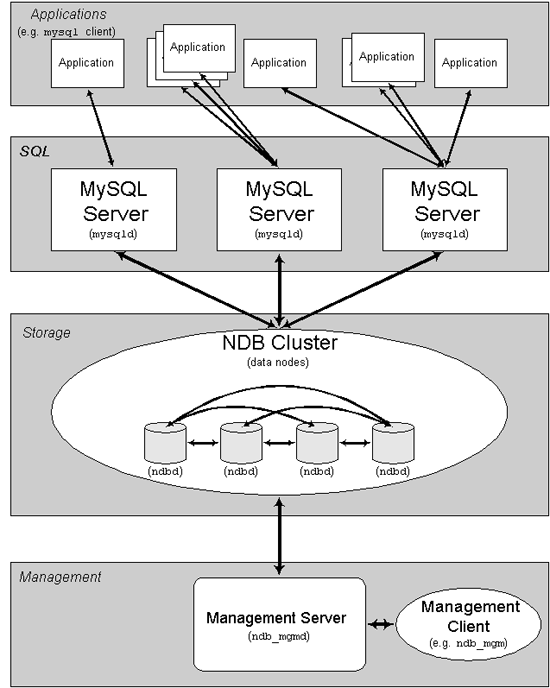
Alle diese Programme arbeiten zusammen, um ein MySQL Cluster zu
bilden. Wenn in der Speicher-Engine NDB Cluster
Daten gespeichert werden, werden die Tabellen in den Datenknoten
untergebracht. Auf solche Tabellen können alle anderen MySQL
Server im Cluster direkt zugreifen. Wenn also beispielsweise ein
Gehaltsabrechnungsprogramm Daten in einem Cluster speichert und
eine Anwendung das Gehalt eines Mitarbeiters ändert, können alle
anderen MySQL Server, die diese Daten abfragen, sofort die
Änderung erkennen.
Die in den Datenknoten für MySQL Cluster abgelegten Daten können gespiegelt werden. Der Cluster kann also mit Fehlern in einzelnen Datenknoten gut umgehen; die einzige Auswirkung wäre die, dass einige wenige Transaktionen abbrechen, weil sie ihren Transaktionsstatus verlieren. Da Anwendungen, die Transaktionen vornehmen, auch mit dem Scheitern einer Transaktion umgehen können, dürfte dies kein Problem sein.
Mit der Einführung von MySQL Cluster in die Open-Source-Szene stellt die MySQL AB jedem, der es benötigt, eine hochverfügbare, leistungsfähige und skalierbare geclusterte Datenverwaltung zur Verfügung.
NDB ist eine hochverfügbare speicherresidente Speicher-Engine mit Fähigkeiten für die Datenpersistenz.
Die Speicher-Engine NDB kann mit mehreren Optionen für Ausfallsicherung und Lastverteilung konfiguriert werden, doch am einfachsten ist es, das System mit der Speicher-Engine auf der Cluster-Ebene zu starten. Die Speicher-Engine NDB von MySQL Cluster enthält vollständige Daten, deren Abhängigkeiten sich lediglich auf andere Daten in demselben Cluster beziehen.
Im Folgenden erfahren Sie, wie man einen MySQL Cluster einrichtet, der aus der Speicher-Engine NDB und einigen MySQL Servern besteht.
Der Cluster-Teil von MySQL Cluster ist gegenwärtig unabhängig von den MySQL Servern konfiguriert. In MySQL Cluster wird jeder Teil des Clusters als ein Knoten betrachtet.
Hinweis: In vielen Zusammenhängen wird der Begriff „Knoten“ für einen Computer verwendet, doch im Zusammenhang mit MySQL Cluster ist damit ein Prozess gemeint. Auf einem einzigen Computer, dem so genannten Cluster-Host, können also beliebig viele Knoten existieren.
Es gibt drei Arten von Cluster-Knoten und eine Minimalkonfiguration von MySQL besteht aus drei Knoten, je einem von jeder Art:
dem Management-Knoten (MGM-Knoten): Dieser verwaltet andere Knoten im MySQL Cluster, indem er zum Beispiel Konfigurationsdaten zur Verfügung stellt, Knoten startet und anhält, eine Sicherung ausführt usw. Da dieser Knotentyp die Konfiguration der anderen Knoten managt, sollten Knoten dieses Typs immer als Erste, vor allen anderen Knoten, gestartet werden. Ein MGM-Knoten wird mit dem Befehl ndb_mgmd gestartet.
dem Datenknoten: Dies ist der Knotentyp, der die Daten des Clusters speichert. Die Anzahl der Datenknoten beträgt Replikas mal Anzahl Fragmente. Wenn Sie beispielsweise zwei Replikas mit je zwei Fragmenten haben, benötigen Sie vier Datenknoten. Noch mehr Replikas sind nicht notwendig. Ein Datenknoten wird mit dem Befehl ndbd gestartet.
dem SQL-Knoten: Mit diesem Knotentyp wird auf die Cluster-Daten zugegriffen. In MySQL Cluster ist ein Client-Knoten ein traditioneller MySQL Server, der die Speicher-Engine
NDB Clusternutzt. Ein SQL-Knoten wird normalerweise mit dem Befehl mysqld --ndbcluster gestartet, oder auch mit mysqld und der Optionndbclusterin dermy.cnf-Datei.
Eine kurze Einführung in die Beziehungen zwischen Knoten, Knotengruppen, Replikas und Partitionen in MySQL Cluster finden Sie in Abschnitt 16.2.1, „MySQL Cluster: Knoten, Knotengruppen, Repliken und Partitionen“.
Um einen Cluster zu konfigurieren, müssen Sie jeden Einzelnen seiner Knoten konfigurieren und individuelle Kommunikationsverbindungen zwischen den Knoten einrichten. Der Entwurf von MySQL Cluster zielt gegenwärtig darauf ab, dass die Speicherknoten alle denselben Bedarf an Prozessorleistung, Speicherplatz und Bandbreite haben. Um überdies nur an einer einzigen Stelle konfigurieren zu müssen, liegen sämtliche Konfigurationen für den gesamten Cluster in nur einer Konfigurationsdatei.
Der Management-Server (MGM-Knoten) verwaltet die Konfigurationsdatei und das Log für den Cluster. Da sich jeder Knoten im Cluster seine Konfigurationsdaten vom Management-Server holt, muss der Knoten feststellen können, wo der Management-Server zu finden ist. Wenn interessante Ereignisse in den Datenknoten eintreten, übermitteln die Knoten Informationen über diese Ereignisse an den Management-Server, der diese Daten dann an das Cluster-Log überträgt.
Darüber hinaus können beliebig viele Cluster-Clientprozesse oder -anwendungen ablaufen. Von diesen gibt es zwei Arten:
Standard-MySQL-Clients: Diese unterscheiden sich von MySQL Cluster nur insofern, als sie eben nicht geclustert sind. Also können Sie auch von vorhandenen MySQL-Anwendungen, die in PHP, Perl, C, C++, Java, Python, Ruby usw. geschrieben wurden, auf MySQL Cluster zugreifen.
Management-Clients: Diese Clients verbinden sich mit dem Management-Server und kennen Befehle, um Knoten elegant zu starten oder abzubrechen, das Message-Tracing ein- und auszuschalten (nur in den Debugversionen), Knotenversionen und -status anzuzeigen, Sicherungen zu starten oder anzuhalten usw.
In diesem Abschnitt wird beschrieben, wie MySQL Cluster mehrfach vorhandene Daten für die Speicherung aufteilt.
Die Konzepte, die im Folgenden mit kurzen Definitionen aufgelistet werden, sind für das Verständnis dieses Themas unerlässlich:
(Daten-)Knoten: Ein ndbd-Prozess, der eine Replik speichert, also eine Kopie der Partition (siehe unten), die der Knotengruppe, zu welcher dieser Knoten gehört, zugewiesen wurde.
Normalerweise liegt jeder Datenknoten auf einem anderen Computer. Es ist jedoch möglich, mehrere Datenknoten auf einem einzigen Computer unterzubringen, wenn dieser über mehrere Prozessoren verfügt. In solchen Fällen kann pro physikalische CPU eine ndbd-Instanz laufen. (Beachten Sie, dass ein Prozessor mit mehreren Zentraleinheiten immer noch ein einzelner Prozessor ist.)
Die Begriffe „Knoten“ und „Datenknoten“ werden im Zusammenhang mit ndbd-Prozessen synonym verwendet. Wenn Management-Knoten (ndb_mgmd -Prozesse) und SQL-Knoten (mysqld-Prozesse) gemeint sind, wird dies im Text ausdrücklich gesagt.
Knotengruppe: Eine Knotengruppe besteht aus einem oder mehreren Knoten und speichert eine Partition oder eine Menge von Replikas (siehe nächster Eintrag).
Hinweis: Gegenwärtig müssen alle Gruppen in einem Cluster gleich viele Knoten haben.
Partition: Ein Teil der in einem Cluster gespeicherten Daten. Es gibt so viele Cluster-Partitionen, wie Knotengruppen im Cluster vorliegen, und jede Knotengruppe ist dafür verantwortlich, mindestens eine Kopie der ihr zugewiesenen Partition (also mindestens eine Replik) aufzubewahren, die dem Cluster zur Verfügung steht.
Replik: Eine Kopie einer Cluster-Partition. Jeder Knoten in einer Knotengruppe speichert eine Replik. Wird gelegentlich auch als Partitionsreplik bezeichnet.
Das folgende Diagramm zeigt einen MySQL Cluster mit vier Datenknoten in zwei Knotengruppen zu je zwei Knoten. Beachten Sie, dass hier nur die Datenknoten gezeigt werden, obwohl ein funktionierender Cluster einen ndb_mgm-Prozess für das Cluster-Management und mindestens einen SQL-Knoten für den Zugriff auf die im Cluster gespeicherten Daten benötigt.
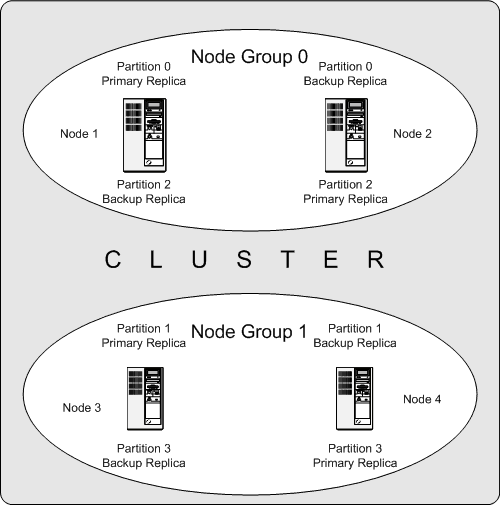
Die in diesem Cluster gespeicherten Daten sind auf vier Partitionen verteilt, die mit 0, 1, 2 und 3 nummeriert sind. Jede Partition wird – in mehrfachen Kopien – in derselben Knotengruppe gespeichert. Partitionen werden auf unterschiedlichen Knotengruppen gespeichert:
Partition 0 wird in Knotengruppe 0 gespeichert; eine primäre Replik (oder primäre Kopie) wird auf Knoten 1 gespeichert, und eine Backup-Replik (Backup-Kopie der Partition) auf Knoten 2.
Partition 1 wird auf der anderen Knotengruppe gespeichert (Knotengruppe 1); die primäre Replik dieser Partition ist auf Knoten 3 und die Backup-Repli befindet sich auf Knoten 4.
Partition 2 wird auf Knotengruppe 0 gespeichert. Die Platzierung ihrer beiden Repliken ist jedoch genau umgekehrt wie bei Partition 0: Bei Partition 2 wird die primäre Replik auf Knoten 2 und die Backup-Replik auf Knoten 1 gespeichert.
Partition 3 wird auf Knotengruppe 1 gespeichert, und die Platzierung ihrer beiden Repliken ist umgekehrt wie bei Partition 1. Mit anderen Worten befindet sich ihre primäre Replik auf Knoten 4 und die Backup-Replik auf Knoten 3.
Für den Dauerbetrieb eines MySQL Clusters bedeutet dies: Solange jede Knotengruppe des Clusters mindestens einen funktionierenden Knoten hat, ist der Cluster im Besitz einer vollständigen Kopie sämtlicher Daten und bleibt funktionstüchtig. Dies wird im nächsten Diagramm veranschaulicht.
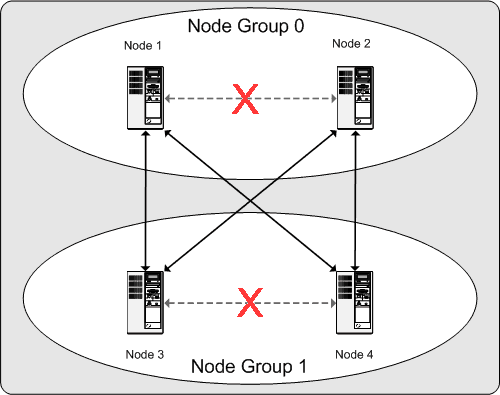
In diesem Beispiel, in dem der Cluster aus zwei Knotengruppen mit je zwei Knoten besteht, genügt eine beliebige Kombination mindestens eines Knotens aus Gruppe A und mindestens eines weiteren Knotens aus Gruppe B, um den Cluster „am Leben“ zu halten (wie es die Pfeile im Diagramm zeigen). Wenn jedoch beide Knoten einer Knotengruppe versagen, genügen die verbleibenden beiden Knoten nicht, um den Betrieb aufrechtzuerhalten (dies zeigen die mit X markierten Pfeile). In beiden Fällen hat der Cluster eine vollständige Partition verloren und kann somit nicht mehr auf alle Cluster-Daten Zugriff geben.
Dieser Abschnitt ist eine „Anleitung“, welche in Grundzügen beschreibt, wie man einen MySQL Cluster plant, installiert, konfiguriert und ausführt. Die Beispiele in Abschnitt 16.4, „MySQL Cluster: Konfiguration“, bieten zwar ausführlichere Informationen über verschiedene Cluster-Optionen und Konfigurationen, aber auch mit dem hier gezeigten Verfahren erhalten Sie einen brauchbaren MySQL Cluster, der ein Minimum an Verfügbarkeit und Datensicherheit bietet.
Dieser Abschnitt behandelt Hardware- und Softwarevoraussetzungen, Netzwerkfragen, die Installation eines MySQL Clusters, die Konfiguration, das Starten, Anhalten und Neustarten eines Clusters, das Laden einer Beispieldatenbank sowie die Ausführung von Anfragen.
Grundvoraussetzungen
Diese Anleitung setzt Folgendes voraus:
Der Cluster hat vier Knoten, von denen jeder auf einem separaten Host residiert und eine feste Netzwerkadresse in einem typischen Ethernet besitzt, wie es hier gezeigt wird:
Knoten IP-Adresse Management(MGM)-Knoten 192.168.0.10 MySQL Server(SQL)-Knoten 192.168.0.20 Datenknoten (NDBD-Knoten) "A" 192.168.0.30 Datenknoten (NDBD-Knoten) "B" 192.168.0.40 Dies wird möglicherweise im nachfolgenden Diagramm klarer:
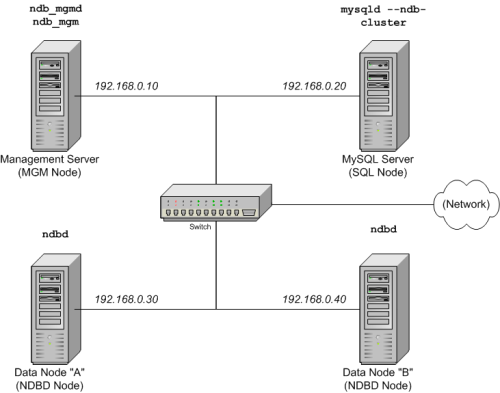
Hinweis: Im Interesse der Einfachheit (und Zuverlässigkeit) verwendet diese Anleitung nur numerische IP-Adressen. Wenn jedoch in Ihrem Netzwerk DNS-Namensauflösung verfügbar ist, können Sie anstelle von IP-Adressen in der Cluster-Konfiguration auch Hostnamen verwenden. Alternativ können Sie in der Datei
/etc/hostsoder der in Ihrem Betriebssystem verwendeten Entsprechung eine andere Möglichkeit für das Host-Lookup einrichten (soweit verfügbar).Jeder Host in unserem Szenario ist ein Intel-PC, auf dem eine normale generische Linux-Distribution in einer Standardkonfiguration auf der Festplatte installiert ist und keine unnötigen Dienste laufen. Das Kernbetriebssystem mit seinen Standard-TCP/IP-Netzwerkfähigkeiten müsste ausreichen. Der Einfachheit halber setzen wir des Weiteren voraus, dass die Dateisysteme auf allen Hosts gleich eingerichtet sind. Anderenfalls müssen Sie diese Anleitungen entsprechend anpassen.
Auf jedem Computer sind Standard-Ethernet-Karten mit 100 Mbps oder 1 Gigabit samt Treibern installiert und alle vier Hosts sind durch eine Standardvorrichtung für Ethernet-Netzwerke, wie beispielsweise einen Switch, miteinander verbunden. (Alle Computer sollten Netzwerkkarten mit demselben Datendurchsatz verwenden, d. h., die vier Computer haben entweder 100-Mbps-Karten oder 1-Gbps-Karten.) MySQL Cluster funktioniert zwar auch in einem 100-Mbps-Netzwerk, aber ein 1-Gigabit-Ethernet bietet deutlich mehr Leistung.
Beachten Sie, dass MySQL Cluster nicht für den Einsatz in einem Netzwerk mit weniger als 100 Mbps Datendurchsatz gedacht ist. Aus diesem und anderen Gründen werden Sie keinen Erfolg haben, wenn Sie versuchen, einen MySQL Cluster in einem öffentlichen Netzwerk wie dem Internet zu betreiben. Das ist auch nicht empfehlenswert.
Für unsere Beispieldaten verwenden wir die Datenbank
world, die Sie von der Website der MySQL AB herunterladen können. Da diese Datenbank relativ wenig Speicherplatz belegt, gehen wir davon aus, dass jeder Computer 256 Mbyte RAM besitzt. Dies dürfte ausreichen, um das Betriebssystem auszuführen, den NDB-Prozess zu hosten und die Datenbank (die Datenknoten) zu speichern.
Auch wenn wir uns in dieser Anleitung auf ein Linux-Betriebssystem beziehen, lassen sich die hier geschilderten Instruktionen und Verfahren auch auf Solaris oder Mac OS X leicht übertragen. Außerdem setzen wir voraus, dass Sie bereits wissen, wie man eine Minimalinstallation durchführt und das Betriebssystem für den Netzwerkbetrieb konfiguriert, oder dass Sie sich in diesen Fragen notfalls an anderer Stelle kundig machen können.
Im nächsten Abschnitt werden Hardware-, Software- und Netzwerkvoraussetzungen für MySQL Cluster etwas eingehender behandelt. (Siehe Abschnitt 16.3.1, „Hardware, Software und Netzwerk“.)
Eine Stärke von MySQL Cluster besteht darin, dass das System auf handelsüblicher Hardware läuft und in dieser Hinsicht keine besonderen Ansprüche stellt – abgesehen von einem großen Arbeitsspeicher, da im Betrieb sämtliche Daten dort gespeichert werden. (Dies wird sich allerdings noch ändern, da in einem künftigen Release von MySQL Cluster eine Datenspeicherung auf Festplatte angestrebt wird.) Natürlich wird die Leistung umso besser, je mehr und je schnellere CPUs eingesetzt werden. Der Speicherbedarf für Cluster-Prozesse ist relativ gering.
Auch an die Software stellt Cluster eher geringe Anforderungen.
Die Host-Betriebssysteme benötigen keine ungewöhnlichen
Module, Dienste, Anwendungen oder Konfigurationen, um MySQL
Cluster zu unterstützen. Für Mac OS X oder Solaris reicht
sogar die Standardinstallation völlig aus. Für Linux dürfte
gleichfalls die Standardinstallation hinreichend sein. Die
Anforderungen an MySQL-Software lassen sich ebenfalls leicht
erfüllen: Sie benötigen lediglich einen Produktions-Release
von MySQL-max 5.1. Um Cluster-Unterstützung zu
bekommen, müssen Sie die
-max-Version von
MySQL einsetzen, brauchen MySQL jedoch nicht selbst zu
kompilieren. In dieser Anleitung setzen wir voraus, dass Sie die
passende -max-Binärversion zu Ihrem
Betriebssystem Linux, Solaris oder Mac OS X verwenden, die unter
den Softwaredownloads von MySQL unter
http://dev.mysql.com/downloads/ erhältlich ist.
Für die Kommunikation zwischen den Knoten unterstützt Cluster TCP/IP-Netzwerke in einer beliebigen Standardtopologie, wofür jeder Host als Minimum eine Standard-Ethernet-Karte mit 100 Mbps plus Switch, Hub oder Router benötigt, um die Netzwerkkonnektivität für den Cluster als Ganzes herzustellen. Wir raten Ihnen dringend, MySQL Cluster in einem eigenen Subnetz zu betreiben, auf das keine Computer zugreifen, die nicht an dem Cluster partizipieren. Dafür gibt es folgende Gründe:
Sicherheit: Die Kommunikation zwischen Cluster-Knoten ist in keiner Weise verschlüsselt oder abgeschirmt. Die einzige Möglichkeit, Datenübertragungen in einem MySQL Cluster zu schützen, besteht darin, den Cluster in einem geschützten Netzwerk auszuführen. Wenn Sie MySQL Cluster für Webanwendungen nutzen möchten, muss der Cluster unbedingt hinter Ihrer Firewall sitzen und nicht etwa in der demilitarisierten Zone Ihres Netzwerks (DMZ) oder an einer anderen Stelle.
Effizienz: Wenn Sie einen MySQL Cluster in einem privaten oder geschützten Netzwerk einrichten, kann er über die Bandbreite zwischen den Cluster-Hosts alleine verfügen. Indem Sie für Ihren MySQL Cluster einen getrennten Switch verwenden, schützen Sie die Cluster-Daten vor unbefugtem Zugriff und gewährleisten überdies, dass die Cluster-Knoten von den Interferenzen durch Datenübertragungen zwischen anderen Computern im Netzwerk verschont bleiben. Die Zuverlässigkeit können Sie durch doppelte Switches und doppelte Karten erhöhen; so scheidet das Netzwerk als Single Point of Failure aus. Viele Gerätetreiber unterstützen eine Ausfallsicherung für solche Kommunikationsverbindungen.
Es ist auch möglich, das sehr schnelle Scalable Coherent Interface (SCI) mit MySQL Cluster zu kombinieren, aber obligatorisch ist es nicht. Unter Abschnitt 16.7, „Verwendung von Hochgeschwindigkeits-Interconnects mit MySQL Cluster“, erfahren Sie mehr über dieses Protokoll und seine Verwendung mit MySQL Cluster.
Auf jedem Hostcomputer für MySQL Cluster, der Speicher- oder SQL-Knoten ausführt, muss MySQL als -max-Binärversion installiert sein. Für Management-Knoten muss zwar nicht die Binärversion von MySQL Server installiert werden, wohl aber die Binärversionen von MGM Server Daemon und vom Client (ndb_mgmd und ndb_mgm). In diesem Abschnitt erfahren Sie alles Notwendige, um für jede Art von Cluster-Knoten die richtige Binärversion zu installieren.
MySQL AB bietet vorkompilierte Binärversionen, die Cluster
unterstützen und die Sie generell nicht selbst kompilieren
müssen. Der erste Schritt zur Installation jedes Cluster-Hosts
besteht also darin, die Datei
mysql-max-5.1.5-alpha-pc-linux-gnu-i686.tar.gz
aus dem
MySQL-Downloadbereich
herunterzuladen. Wir gehen davon aus, dass Sie diese Datei in
das Verzeichnis /var/tmp jedes Computers
legen. (Sollten Sie doch eine maßgeschneiderte Binärversion
benötigen, schauen Sie bitte unter
Abschnitt 2.8.3, „Installation vom Entwicklungs-Source-Tree“, nach.)
RPMs gibt es auch für 32-Bit- und 64-Bit-Linux-Systeme. Die von
den RPMs installierten -max-Binaries
unterstützen die Speicher-Engine NDBCluster.
Wenn Sie diese anstelle der Binärdateien einsetzen möchten,
müssen Sie allerdings beide Packages -
-server und -max - auf
allen Computern installieren, die Cluster-Knoten hosten sollen.
(Unter Abschnitt 2.4, „MySQL unter Linux installieren“, erfahren Sie mehr darüber,
wie man MySQL mithilfe der RPMs installiert.) Nach der
Installation von RPM müssen Sie noch den Cluster konfigurieren,
wie in Abschnitt 16.3.3, „Konfiguration im Mehrcomputerbetrieb“, beschrieben.
Hinweis: Nach Abschluss der Installation dürfen Sie noch nicht die Binaries starten. Wie Sie das tun, zeigen wir Ihnen, nachdem sämtliche Knoten konfiguriert sind.
Speicherung und Installation des SQL-Knotens
Auf allen drei Computern, die Speicher- oder SQL-Knoten hosten
sollen, müssen Sie als root-User folgende
Schritte ausführen:
Sie müssen in den Dateien
/etc/passwdund/etc/groupnachschauen (oder die Tools nutzen, die Ihr Betriebssystem zur Verwaltung von Benutzern und Gruppen zur Verfügung stellt), um festzustellen, ob auf dem System bereits einemysql-Gruppe und einmysql-Benutzer vorhanden ist. Manche Betriebssystem-Distributionen legen diese bei ihrer Installation bereits an. Wenn sie noch nicht vorhanden sind, legen Sie eine neuemysql-Benutzergruppe an und fügen dieser dann einenmysql-Benutzer hinzu:shell>
groupadd mysqlshell>useradd -g mysql mysqlDie Syntax für useradd und groupadd kann auf verschiedenen Unix-Versionen etwas abweichen. Es ist auch möglich, dass die Befehle etwas andere Namen haben, wie etwa adduser und addgroup.
Dann wechseln Sie in das Verzeichnis mit der heruntergeladenen Datei, packen das Archiv aus und erzeugen einen Symlink auf die Executable mysql-max. Beachten Sie, dass die tatsächlichen Datei- und Verzeichnisnamen je nach MySQL-Version unterschiedlich sind.
shell>
cd /var/tmpshell>tar -xzvf -C /usr/local/bin mysql-max-5.1.5-alpha-pc-linux-gnu-i686.tar.gzshell>ln -s /usr/local/bin/mysql-max-5.1.5-alpha-pc-linux-gnu-i686 mysqlNun gehen Sie in das Verzeichnis
mysqlund führen das mitgelieferte Skript aus, das die Systemdatenbanken anlegt:shell>
cd mysqlshell>scripts/mysql_install_db --user=mysqlNun stellen Sie die Berechtigungen für den MySQL Server und die Datenverzeichnisse ein:
shell>
chown -R root .shell>chown -R mysql datashell>chgrp -R mysql .Beachten Sie, dass das Datenverzeichnis auf jedem Computer, auf dem ein Datenknoten residiert, unter
/usr/local/mysql/dataliegt. Dieses Wissen werden wir nutzen, wenn wir den Management-Knoten konfigurieren. (Siehe Abschnitt 16.3.3, „Konfiguration im Mehrcomputerbetrieb“.)Kopieren Sie das MySQL-Startskript in das passende Verzeichnis, sorgen Sie dafür, dass es ausführbar ist, und stellen Sie ein, dass es beim Hochfahren des Betriebssystems läuft:
shell>
cp support-files/mysql.server /etc/rc.d/init.d/shell>chmod +x /etc/rc.d/init.d/mysql.servershell>chkconfig --add mysql.serverHier legen wir die Verknüpfungen zu den Startskripten mit dem Befehl chkconfig von Red Hat an. Bitte wählen Sie das für Ihr Betriebssystem jeweils passende Mittel aus, etwa update-rc.d für Debian.
Die obigen Schritte müssen auf jedem Computer, der einen Speicher- oder SQL-Knoten hostet, separat ausgeführt werden.
Installation des Management-Knotens
Um den Management(MGM)-Knoten installieren zu können, muss die
mysqld-Binary nicht installiert sein. Nur die
Binärversionen für den MGM-Server und -Client sind
erforderlich. Diese finden Sie im heruntergeladenen
-max-Archiv. Wir gehen wieder davon aus, dass
Sie die Datei in das Verzeichnis /var/tmp
gespeichert haben.
Die folgenden Schritte müssen Sie als
root-User Ihres Systems ausführen (das
heißt nach Ausführung von sudo, su
root oder dem für Ihr System passenden Befehl zur
vorübergehenden Einrichtung von Administratorrechten). Dann
installieren Sie auf dem Host des Cluster-Management-Knotens
ndb_mgmd und ndb_mgm wie
folgt:
Gehen Sie in das Verzeichnis
/var/tmpund extrahieren Sie ndb_mgm und ndb_mgmd aus dem Archiv in ein passendes Verzeichnis wie beispielsweise/usr/local/bin:shell>
cd /var/tmpshell>tar -zxvf mysql-max-5.1.5-alpha-pc-linux-gnu-i686.tar.gz \/usr/local/bin '*/bin/ndb_mgm*'Gehen Sie in das Verzeichnis, in das Sie die Dateien entpackt haben, und machen Sie beide ausführbar:
shell>
cd /usr/local/binshell>chmod +x ndb_mgm*
In Abschnitt 16.3.3, „Konfiguration im Mehrcomputerbetrieb“, werden wir Konfigurationsdateien für alle Knoten unseres Beispiel-Clusters erstellen und schreiben.
Für unseren MySQL Cluster mit vier Knoten und vier Hosts müssen wir vier Konfigurationsdateien schreiben, je eine pro Knoten/Host.
Jeder Datenknoten oder SQL-Knoten benötigt eine
my.cnf-Datei, die zwei Informationen liefert: einen connectstring, der dem Knoten sagt, wo er den MGM-Knoten findet, und eine Leitung, die den MySQL Server auf diesem Host (dem Computer mit dem Datenknoten) anweist, im NDB-Modus zu laufen.Mehr zum Thema Verbindungs-Strings erfahren Sie unter Abschnitt 16.4.4.2, „MySQL Cluster:
connectstring“.Der Management-Knoten benötigt eine
config.ini-Datei, die ihm sagt, wie viele Replikas er pflegen soll, wie viel Speicher er für die Daten und Indizes auf jedem Datenknoten reservieren soll, wo er die Datenknoten suchen soll, wo er die Daten für jeden Datenknoten auf Platte speichern soll und wo er SQL-Knoten finden kann.
Konfiguration der Speicher- und SQL-Knoten
Die für die Datenknoten erforderliche
my.cnf-Datei ist ganz einfach. Diese
Konfigurationsdatei sollte im Verzeichnis
/etc liegen und kann mit jedem Editor
bearbeitet werden. (Wenn die Datei noch nicht existiert, legen
Sie sie bitte an.) Zum Beispiel:
shell> vi /etc/my.cnf
Hier legen wir die Datei zwar mit vi an, aber Sie können auch jeden anderen Editor benutzen.
Für jeden Daten- und SQL-Knoten in unserem Beispiel-Cluster
sollte die my.cnf-Datei folgendermaßen
aussehen:
# Optionen für den mysqld-Prozess: [MYSQLD] ndbcluster # NDB-Engine ausführen ndb-connectstring=192.168.0.10 # Speicherort des MGM-Knotens # Optionen für den ndbd-Prozess: [MYSQL_CLUSTER] ndb-connectstring=192.168.0.10 # Speicherort des MGM-Knotens
Wenn Sie diese Daten eingegeben haben, speichern Sie die Datei und schließen den Editor. Dies tun Sie für die Hosts der Datenknoten „A“ und „B“ sowie für den Host des SQL-Knotens.
Konfiguration des Management-Knotens
Der erste Schritt zur Konfiguration des MGM-Knotens besteht
darin, das Verzeichnis für die Konfigurationsdatei und dann die
Datei selbst anzulegen. Zum Beispiel (immer als
root-User):
shell>mkdir /var/lib/mysql-clustershell>cd /var/lib/mysql-clustershell>vi config.ini
Für unseren Beispiel-Cluster sieht die
config.ini-Datei folgendermaßen aus:
# Optionen, die ndbd-Prozesse auf allen Datenknoten betreffen:
[NDBD DEFAULT]
NoOfReplicas=2 # Anzahl der Replikas
DataMemory=80M # So viel Speicher wird für Datenknoten reserviert
IndexMemory=18M # So viel Speicher wird für Indizes reserviert
# Für DataMemory und IndexMemory haben wir die Standardwerte
# eingesetzt. Da die "world"-Datenbank nur
# circa 500 Kbyte belegt, dürfte dies für unseren Beispiel-Cluster
# mehr als ausreichend sein.
# TCP/IP options:
[TCP DEFAULT]
portnumber=2202 # Dies ist der Standardwert. Sie können jedoch
# jeden Port benutzen, der auf allen Hosts im Cluster frei ist.
# Hinweis: Ab MySQL 5.0 ist es ratsam, keine
# Portnummer anzugeben, sondern einfach
# die Verwendung des Standardwerts zu gestatten
# Optionen für den Management-Prozess:
[NDB_MGMD]
hostname=192.168.0.10 # Hostname oder IP-Adresse des MGM-Knotens
datadir=/var/lib/mysql-cluster # Verzeichnis der Logdateien für MGM-Knoten
# Optionen für Datenknoten "A":
[NDBD]
# (ein [NDBD]-Abschnitt pro Datenknoten)
hostname=192.168.0.30 # Hostname oder IP-Adresse
datadir=/usr/local/mysql/data # Verzeichnis für die Datendateien dieses Knotens
# Optionen für Datenknoten "B":
[NDBD]
hostname=192.168.0.40 # Hostname oder IP-Adresse
datadir=/usr/local/mysql/data # Verzeichnis für die Datendateien dieses Knotens
# Optionen für SQL-knoten:
[MYSQLD]
hostname=192.168.0.20 # Hostname oder IP-Adresse
# (Weitere mysqld-Verbindungen können
# für diverse Zwecke, z. B. Ausführung von
# ndb_restore, für diesen Knoten angegeben werden.)
(Hinweis: Die Datenbank
world kann von http://dev.mysql.com/doc/
heruntergeladen werden, wo sie unter „Examples.“
aufgeführt ist.)
Wenn alle Konfigurationsdateien angelegt und diese minimalen Optionen angegeben sind, können Sie den Cluster starten und sich vergewissern, dass alle Prozesse laufen. Wie das geht, erfahren Sie in Abschnitt 16.3.4, „Erster Start“.
Detailliertere Informationen über die verfügbaren Konfigurationsparameter von MySQL Cluster und ihre Verwendung finden Sie unter Abschnitt 16.4.4, „Konfigurationsdatei“, und Abschnitt 16.4, „MySQL Cluster: Konfiguration“. Wie Sie MySQL Cluster für die Erstellung von Datensicherungen konfigurieren, erfahren Sie unter Abschnitt 16.6.5.4, „Konfiguration für Cluster-Backup“.
Hinweis: Der Standardport für Cluster-Management-Knoten ist 1186 und der Standardport für Datenknoten ist 2202. Seit MySQL 5.0.3 wurde diese Einschränkung aufgehoben und der Cluster weist automatisch Ports für Datenknoten aus dem Vorrat der freien Ports zu.
Den Cluster nach erfolgter Konfiguration zu starten ist nicht schwer. Jeder Cluster-Knoten-Prozess muss separat und auf dem Knoten-Host gestartet werden. Zwar können die Knoten in beliebiger Reihenfolge gestartet werden, aber es empfiehlt sich, als Erstes den Management-Knoten, dann die Speicherknoten und zum Schluss die SQL-Knoten zu starten:
Auf dem Management-Host setzen Sie folgenden Befehl in der System-Shell ab, um den MGM-Knoten-Prozess zu starten:
shell>
ndb_mgmd -f /var/lib/mysql-cluster/config.iniBeachten Sie, dass Sie ndb_mgmd mithilfe der Option
-foder--config-filemitteilen müssen, wo er seine Konfigurationsdatei finden kann. (Einzelheiten siehe Abschnitt 16.5.3, „ndb_mgmd, der Management-Server-Prozess“.)Auf jedem Datenknoten-Host geben Sie folgenden Befehl, um den ndbd-Prozess zum ersten Mal zu starten:
shell>
ndbd --initialEs ist äußerst wichtig, dass der Parameter
--initialnur beim ersten Start von ndbd oder bei einem Neustart nach einer Sicherungs-/Wiederherstellungsoperation oder einer Konfigurationsänderung verwendet wird. Denn die Option--initialveranlasst den Knoten, alle für die Wiederherstellung erforderlichen Dateien zu löschen, die von vorherigen ndbd-Instanzen angelegt wurden, einschließlich der Dateien des Redo-Logs.Wenn Sie MySQL auf dem Cluster-Host, wo der SQL-Knoten residieren soll, von RPM-Dateien installiert haben, können (und sollten) Sie das in
/etc/init.dinstallierte Startskript nutzen, um den MySQL Server-Prozess auf dem SQL-Knoten zu starten. Beachten Sie, dass Sie die-max-Server-RPM zusätzlich zur Standardserver-RPM installieren müssen, um die Binärversion von-max-Server ausführen zu können.
Wenn alles geklappt hat und der Cluster korrekt eingerichtet wurde, sollte er nun funktionsbereit sein. Dies können Sie testen, indem Sie den Management-Knoten-Client ndb_mgm aufrufen. Die Ausgabe sollte ungefähr dem Folgenden entsprechen, wobei jedoch je nach der verwendeten MySQL-Version kleinere Abweichungen möglich sind:
shell>ndb_mgm-- NDB Cluster -- Management Client -- ndb_mgm>SHOWConnected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.30 (Version: 5.1.5-alpha, Nodegroup: 0, Master) id=3 @192.168.0.40 (Version: 5.1.5-alpha, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.10 (Version: 5.1.5-alpha) [mysqld(SQL)] 1 node(s) id=4 (Version: 5.1.5-alpha)
Hinweis: Wenn Sie eine ältere
Version von MySQL verwenden, wird der SQL-Knoten möglicherweise
als [mysqld(API)] bezeichnet. Das ist eine
ältere Lesart, die mittlerweile abgeschafft wurde.
Nun können Sie im MySQL Cluster mit Datenbanken, Tabellen und Daten arbeiten. Unter Abschnitt 16.3.5, „Beispieldaten einladen und Abfragen ausführen“, finden Sie eine kurze Beschreibung.
Der Umgang mit Daten im MySQL Cluster ist ganz ähnlich wie in einer MySQL-Konfiguration ohne Cluster. Nur auf zwei Dinge muss man achten:
Damit eine Tabelle im Cluster repliziert wird, muss die Speicher-Engine
NDB Clustermit der OptionENGINE=NDBoder der TabellenoptionENGINE=NDBCLUSTEReingeschaltet sein. Dies können Sie tun, wenn Sie die Tabelle anlegen:CREATE TABLE
tbl_name( ... ) ENGINE=NDBCLUSTER;Alternativ können Sie eine bereits vorhandene Tabelle, die eine andere Speicher-Engine verwendet, mit
ALTER TABLEaufNDB Clusterumstellen:ALTER TABLE
tbl_nameENGINE=NDBCLUSTER;Jede
NDB-Tabelle muss einen Primärschlüssel haben. Wenn der Benutzer beim Anlegen der Tabelle keinen definiert, wird von der Speicher-EngineNDB Clusterautomatisch ein verborgener Primärschlüssel generiert. (Hinweis: Dieser verborgene Schlüssel belegt Platz wie jeder andere Tabellenindex auch. Nicht selten treten Speicherplatzprobleme auf, wenn diese automatisch angelegten Indizes untergebracht werden müssen.)
Wenn Sie aus der Ausgabe von mysqldump
Tabellen aus einer vorhandenen Datenbank importieren, können
Sie das SQL-Skript mit einem Editor öffnen und die Option
ENGINE für alle Anweisungen einstellen, in
denen Tabellen angelegt werden, oder eine eventuell vorhandene
ENGINE- (oder TYPE-)Option
ersetzen. Nehmen wir an, Sie haben die Beispieldatenbank
world auf einem anderen MySQL Server liegen,
der MySQL Cluster nicht unterstützt, und Sie möchten die
Tabelle City exportieren:
shell> mysqldump --add-drop-table world City > city_table.sql
Die resultierende city_table.sql-Datei
enthält die folgende Anweisung zur Erzeugung einer Tabelle (und
die notwendigen INSERT-Anweisungen, um die
Tabellendaten zu importieren):
DROP TABLE IF EXISTS `City`;
CREATE TABLE `City` (
`ID` int(11) NOT NULL auto_increment,
`Name` char(35) NOT NULL default '',
`CountryCode` char(3) NOT NULL default '',
`District` char(20) NOT NULL default '',
`Population` int(11) NOT NULL default '0',
PRIMARY KEY (`ID`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
INSERT INTO `City` VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO `City` VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO `City` VALUES (3,'Herat','AFG','Herat',186800);
(restliche INSERT-Anweisungen ausgelassen)
Sie müssen gewährleisten, dass MySQL die Speicher-Engine NDB
für diese Tabelle verwendet. Dazu ändern Sie die Tabellendefinition
vor dem Import in die Cluster-Datenbank.
Die Definition der Tabelle City würde zum
Beispiel folgendermaßen modifiziert:
DROP TABLE IF EXISTS `City`;
CREATE TABLE `City` (
`ID` int(11) NOT NULL auto_increment,
`Name` char(35) NOT NULL default '',
`CountryCode` char(3) NOT NULL default '',
`District` char(20) NOT NULL default '',
`Population` int(11) NOT NULL default '0',
PRIMARY KEY (`ID`)
) ENGINE=NDBCLUSTER DEFAULT CHARSET=latin1;
INSERT INTO `City` VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO `City` VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO `City` VALUES (3,'Herat','AFG','Herat',186800);
(remaining INSERT statements omitted)
Dies müssen Sie mit der Definition jeder Tabelle tun, die in
die geclusterte Datenbank importiert werden soll. Am einfachsten
erreichen Sie dies, indem Sie in der Datei mit den
Tabellendefinitionen alle Vorkommen von
TYPE=MyISAM oder
ENGINE=MyISAM durch
ENGINE=NDBCLUSTER ersetzen. Wenn Sie die
Datei nicht ändern möchten, können Sie die Tabellen auch mit
der unveränderten Datei anlegen und dann ihren Typ mit
ALTER TABLE ändern. Die Einzelheiten
erfahren Sie in einem späteren Abschnitt.
Wenn wir davon ausgehen, dass Sie bereits eine Datenbank namens
world auf dem SQL-Knoten des Clusters
angelegt haben, können Sie nun
city_table.sql mit dem
Kommandozeilen-Client mysql lesen und die
entsprechende Tabelle in der üblichen Weise mit Daten füllen:
shell> mysql world < city_table.sql
Dieser Befehl muss unbedingt auf dem Host ausgeführt werden,
auf welchem der SQL-Knoten läuft (in diesem Fall auf der
Maschine mit der IP-Adresse 192.168.0.20).
Um eine Kopie der gesamten world-Datenbank
auf dem SQL-Knoten anzulegen, führen Sie
mysqldump auf dem ungeclusterten Server aus,
um die Datenbank in die Datei world.sql im
Verzeichnis /usr/local/mysql/data zu
exportieren. Danach importieren Sie diese Datei folgendermaßen
in den SQL-Knoten des Clusters:
shell>cd /usr/local/mysql/datashell>mysql world < world.sql
Wenn Sie die Datei an einer anderen Stelle speichern, müssen Sie die obigen Anleitungen entsprechend abändern.
Sie müssen wissen, dass NDB Cluster in MySQL
5.1 nicht die selbstständige Erkennung von
Datenbanken unterstützt (siehe
Abschnitt 16.8, „Bekannte Beschränkungen von MySQL Cluster“). Mit anderen
Worten: Sobald Sie die Datenbank world und
ihre Tabellen auf einem Datenknoten angelegt haben, müssen Sie
die Anweisung CREATE SCHEMA world mit
nachfolgendem FLUSH TABLES auf jedem
SQL-Knoten im Cluster erteilen. Nur dann kann der Knoten die
Datenbank erkennen und ihre Tabellendefinitionen lesen.
SELECT-Anfragen werden auf dem SQL-Knoten
genau wie auf jedem anderen MySQL Server ausgeführt. Um
Anfragen auf der Kommandozeile auszuführen, müssen Sie sich
zuerst wie üblich in den MySQL Monitor einloggen (das Passwort
von root am Enter
password:-Prompt eingeben):
shell> mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 5.1.5-alpha
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>
Wir verwenden einfach das root-Konto des
MySQL Servers und gehen davon aus, dass Sie bei der Installation
des MySQL Servers die Standardsicherheitsvorkehrungen getroffen
und ein starkes root-Passwort eingerichtet
haben. Mehr darüber lesen Sie unter
Abschnitt 2.9.3, „Einrichtung der anfänglichen MySQL-Berechtigungen“.
Bitte achten Sie darauf, dass Cluster-Knoten, wenn sie
aufeinander zugreifen, nicht von dem MySQL-Berechtigungssystem
Gebrauch machen. Die Einrichtung oder Änderung von
MySQL-Benutzerkonten (einschließlich root)
wirkt sich nur auf Anwendungen aus, die auf den SQL-Knoten
zugreifen, aber nicht auf die Interaktion zwischen den Knoten.
Wenn Sie die ENGINE-Klauseln in den
Tabellendefinitionen vor dem Import des SQL-Skripts nicht
geändert hatten, sollten Sie nun folgende Anweisungen
ausführen:
mysql>USE world;mysql>ALTER TABLE City ENGINE=NDBCLUSTER;mysql>ALTER TABLE Country ENGINE=NDBCLUSTER;mysql>ALTER TABLE CountryLanguage ENGINE=NDBCLUSTER;
Auch die Auswahl einer Datenbank und die Ausführung einer SELECT-Anfrage auf einer Tabelle dieser Datenbank sowie das Schließen des MySQL Monitors funktionieren wie üblich:
mysql>USE world;mysql>SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5;+-----------+------------+ | Name | Population | +-----------+------------+ | Bombay | 10500000 | | Seoul | 9981619 | | São Paulo | 9968485 | | Shanghai | 9696300 | | Jakarta | 9604900 | +-----------+------------+ 5 rows in set (0.34 sec) mysql>\qBye shell>
Anwendungen, die MySQL nutzen, können ihre Standard-APIs auch
für den Zugriff auf NDB-Tabellen verwenden. Bitte denken Sie
jedoch daran, dass Ihre Anwendung auf den SQL-Knoten zugreifen
muss, und nicht auf den MGM- oder die Speicherknoten. Das
folgende kleine Beispiel zeigt, wie die obige
SELECT-Anweisung mithilfe der
mysqli-Erweiterung von PHP 5 ausgeführt
wird, die auf einem Webserver irgendwo anders im Netzwerk
läuft:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type"
content="text/html; charset=iso-8859-1">
<title>SIMPLE mysqli SELECT</title>
</head>
<body>
<?php
# Verbindung zum SQL-Knoten:
$link = new mysqli('192.168.0.20', 'root', 'root_password', 'world');
# Die Parameter für den mysqli-Konstruktor sind:
# Host, User, Passwort, Datenbank
if( mysqli_connect_errno() )
die("Connect failed: " . mysqli_connect_error());
$query = "SELECT Name, Population
FROM City
ORDER BY Population DESC
LIMIT 5";
# wenn keine Fehler auftreten...
if( $result = $link->query($query) )
{
?>
<table border="1" width="40%" cellpadding="4" cellspacing ="1">
<tbody>
<tr>
<th width="10%">City</th>
<th>Population</th>
</tr>
<?
# dann zeige Ergebnisse an...
while($row = $result->fetch_object())
printf(<tr>\n <td align=\"center\">%s</td><td>%d</td>\n</tr>\n",
$row->Name, $row->Population);
?>
</tbody
</table>
<?
# ...und prüfe, wie viele Zeilen abgerufen wurden
printf("<p>Affected rows: %d</p>\n", $link->affected_rows);
}
else
# anderenfalls sag uns, was schief gegangen ist
echo mysqli_error();
# gib die Ergebnismenge und das mysqli-Verbindungsobjekt frei
$result->close();
$link->close();
?>
</body>
</html>
Wir setzen voraus, dass der Prozess, der auf dem Webserver läuft, die IP-Adresse des SQL-Knotens erreichen kann.
In gleicher Weise können Sie die MySQL C-API, Perl-DBI, Python-mysql oder die eigenen Connectors der MySQL AB einsetzen, um die Aufgaben der Datendefinition und Datenbearbeitung genau so zu erledigen, wie Sie es auch normalerweise mit MySQL tun.
Um den Cluster herunterzufahren, geben Sie folgenden Befehl in eine Shell auf dem Host des MGM-Knotens ein:
shell> ndb_mgm -e shutdown
Hier wird die Option -e verwendet, um einen
Befehl von der Shell an den ndb_mgm-Client zu
übergeben. Siehe auch Abschnitt 4.3.1, „Befehlszeilenoptionen für mysqld“.
Mit diesem Befehl werden ndb_mgm,
ndb_mgmd und alle eventuell laufenden
ndbd-Prozesse geräuschlos beendet.
SQL-Knoten können mit mysqladmin shutdown
und anderen Methoden heruntergefahren werden.
Folgende Befehle starten den Cluster neu:
Auf dem Management-Host (in unserem Beispiel
192.168.0.10):shell>
ndb_mgmd -f /var/lib/mysql-cluster/config.iniAuf jedem der Daten-Hosts (
192.168.0.30und192.168.0.40):shell>
ndbdDenken Sie daran, dass Sie diesen Befehl nicht mit der Option
--initialaufrufen dürfen, wenn Sie einen NDBD-Knoten ganz normal neu starten.Auf dem SQL-Host (
192.168.0.20):shell>
mysqld &
Mehr über Datensicherungen im Cluster erfahren Sie unter Abschnitt 16.6.5.2, „Verwendung des Management-Servers zur Erzeugung von Backups“.
Um den Cluster aus einer Datensicherung wiederherzustellen, benötigen Sie den Befehl ndb_restore, der in Abschnitt 16.6.5.3, „Wiederherstellung aus einem Cluster-Backup“, erklärt wird.
Weitere Informationen über die Konfiguration von MySQL Cluster finden Sie unter Abschnitt 16.4, „MySQL Cluster: Konfiguration“.
Ein MySQL Server in einem MySQL Cluster unterscheidet sich nur in
einer Hinsicht von einem normalen (ungeclusterten) MySQL Server:
Er verwendet die Speicher-Engine NDB Cluster.
Diese Engine wird auch einfach als NDB
bezeichnet, beide Namen sind synonym.
Um nicht überflüssig Ressourcen zu reservieren, ist die
NDB-Engine in der Standardkonfiguration des
Servers ausgeschaltet. Um sie einzuschalten, müssen Sie die
Serverkonfigurationsdatei my.cnf ändern oder
den Server mit der Option --ndbcluster
hochfahren.
Da der MySQL Server Teil des Clusters ist, muss auch er wissen,
wie er einen MGM-Knoten erreicht, von dem er sich die
Cluster-Konfigurationsdaten besorgen kann. Nach Voreinstellung
sucht er den MGM-Knoten auf dem localhost. Wenn
Sie jedoch einen anderen Ort angeben müssen, so können Sie dies
in der Datei my.cnf oder auf der
Kommandozeile des MySQL Servers tun. Bevor die Speicher-Engine
NDB genutzt werden kann, müssen mindestens ein
MGM-Knoten sowie die erforderlichen Datenknoten funktionieren.
Die Speicher-Engine NDB für den
Cluster-Betrieb ist als Binärdistribution für Linux, Mac OS X
und Solaris erhältlich. Wir arbeiten daran, Cluster auf allen
von MySQL unterstützten Betriebssystemen einschließlich
Windows funktionsfähig zu machen.
Wenn Sie einen Build von einem Source Tarball oder dem MySQL
5.1 BitKeeper Tree bevorzugen, achten Sie darauf,
configure mit der Option
--with-ndbcluster auszuführen. Sie können
jedoch auch das Build-Skript
BUILD/compile-pentium-max laufen lassen.
Beachten Sie, dass dieses Skript OpenSSL enthält: Damit der
Build fehlerfrei läuft, müssen Sie also entweder OpenSSL
besitzen oder sich besorgen oder
compile-pentium-max umkonfigurieren, um
dieses Erfordernis herauszunehmen. Sie können natürlich auch
einfach die Standardinstruktionen für das Kompilieren Ihrer
eigenen Binaries befolgen und dann die üblichen Tests und
Installationsprozeduren durchführen. Siehe
Abschnitt 2.8.3, „Installation vom Entwicklungs-Source-Tree“.
In den folgenden Abschnitten wird vorausgesetzt, dass Sie mit der Installation von MySQL bereits vertraut sind. Daher behandeln wir hier nur die Unterschiede zwischen der Konfiguration eines geclusterten und eines ungeclusterten MySQL Servers. (Wenn Sie genauere Informationen benötigen, schauen Sie unter Kapitel 2, Installation von MySQL, nach.)
Am einfachsten ist die Cluster-Konfiguration, wenn alle
Management- und Datenknoten bereits laufen. Dies ist wohl der
langwierigste Teil der Konfiguration. Dagegen ist die
Bearbeitung der Datei my.cnf ziemlich
einfach und dieser Abschnitt wird lediglich beschreiben, wo die
Konfiguration von der des ungeclusterten MySQL Servers abweicht.
Um sich mit den Grundlagen vertraut zu machen, beschreiben wir zuerst die denkbar einfachste Konfiguration eines funktionsfähigen MySQL Clusters. Danach müssten Sie in der Lage sein, die von Ihnen gewünschte Startkonfiguration aus den Informationen der anderen zum Thema gehörenden Teile dieses Kapitels zu erschließen.
Zuerst müssen Sie ein Konfigurationsverzeichnis wie
beispielsweise /var/lib/mysql-cluster
anlegen, indem Sie folgenden Befehl als
System-root-User ausführen:
shell> mkdir /var/lib/mysql-cluster
In diesem Verzeichnis legen Sie eine Datei namens
config.ini an, die folgende Daten enthält.
Bitte setzen Sie für HostName und
DataDir die für Ihr System passenden Werte
ein.
# Die Datei "config.ini" zeigt eine Minimalkonfiguration, bestehend aus 1 Datenknoten, # 1 Management-Server und 3 MySQL Servern. # Die leeren Default-Abschnitte sind nicht erforderlich und werden nur der # Vollständigkeit halber gezeigt. # Die Datenknoten müssen einen Hostnamen angeben, nicht aber die MySQL Server. # Wenn Sie den Hostnamen Ihres Computers nicht wissen, verwenden Sie localhost. # Der Parameter DataDir hat ebenfalls einen Standardwert, sollte aber besser # explizit gesetzt werden. # Hinweis: DB, API und MGM sind Aliase für NDBD, MYSQLD und NDB_MGMD # DB und API sind veraltet und sollten in neuen # Installationen nicht mehr benutzt werden. [NDBD DEFAULT] NoOfReplicas= 1 [MYSQLD DEFAULT] [NDB_MGMD DEFAULT] [TCP DEFAULT] [NDB_MGMD] HostName= myhost.example.com [NDBD] HostName= myhost.example.com DataDir= /var/lib/mysql-cluster [MYSQLD] [MYSQLD] [MYSQLD]
Sie können jetzt den Management-Server
ndb_mgmd starten. Da dieser standardmäßig
versucht, die Datei config.ini in seinem
aktuellen Arbeitsverzeichnis zu lesen, müssen Sie in das
Verzeichnis wechseln, in dem die Datei sich befindet, und dann
ndb_mgmd aufrufen:
shell>cd /var/lib/mysql-clustershell>ndb_mgmd
Danach starten Sie einen einzelnen DB-Knoten mit dem Befehl
ndbd. Wenn Sie ndbd zum
allerersten Mal für einen DB-Knoten starten, müssen Sie die
Option --initial einsetzen:
shell> ndbd --initial
Bei allen weiteren Starts von ndbd müssen
Sie die --initial-Option unbedingt
weglassen:
shell> ndbd
Der Grund, weshalb die Option --initial bei
weiteren Neustarts nicht wieder benutzt werden darf, ist der,
dass sie ndbd veranlasst, alle vorhandenen
Daten- und Logdateien (und alle Metadaten für Tabellen) dieses
Datenknotens zu löschen und neu zu erzeugen. Die einzige
Ausnahme von dieser Regel, --initial nur für
den allerersten Aufruf von ndbd zu verwenden,
tritt dann ein, wenn der Cluster neu gestartet und nach dem
Hinzufügen neuer Datenknoten aus den Sicherungsdateien
wiederhergestellt wird.
Nach Voreinstellung sucht ndbd den
Management-Server auf localhost am Port 1186.
Hinweis: Wenn Sie MySQL von
einem Binary Tarball installiert haben, müssen Sie den Pfad der
ndb_mgmd- und ndbd-Server
explizit angeben. (Normalerweise befinden sich die beiden in
/usr/local/mysql/bin.)
Zum Schluss gehen Sie in das MySQL-Datenverzeichnis
(normalerweise /var/lib/mysql oder
/usr/local/mysql/data) und sorgen dafür,
dass die Datei my.cnf die Option enthält,
die zur Aktivierung der Speicher-Engine NDB erforderlich ist:
[mysqld] ndbcluster
Jetzt können Sie den MySQL Server wie gewöhnlich starten:
shell> mysqld_safe --user=mysql &
Warten Sie einen Augenblick, um sich zu vergewissern, dass der
MySQL Server richtig läuft. Wenn Sie die Meldung mysql
ended sehen, schauen Sie in die
.err-Datei des Servers, um den Fehler zu
finden.
Wenn so weit alles geklappt hat, können Sie den Server nun
geclustert starten. Verbinden Sie sich mit dem Server und
schauen Sie nach, ob die Speicher-Engine
NDBCLUSTER aktiviert ist:
shell>mysqlWelcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 to server version: 5.1.5-alpha-Max Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>SHOW ENGINES\G... *************************** 12. row *************************** Engine: NDBCLUSTER Support: YES Comment: Clustered, fault-tolerant, memory-based tables *************************** 13. row *************************** Engine: NDB Support: YES Comment: Alias for NDBCLUSTER ...
Die Zeilennummern der obigen Ausgabe können auf Ihrem System je nach Ihrer Serverkonfiguration abweichen.
Versuchen Sie nun, eine NDBCLUSTER-Tabelle
anzulegen:
shell>mysqlmysql>USE test;Database changed mysql>CREATE TABLE ctest (i INT) ENGINE=NDBCLUSTER;Query OK, 0 rows affected (0.09 sec) mysql>SHOW CREATE TABLE ctest \G*************************** 1. row *************************** Table: ctest Create Table: CREATE TABLE `ctest` ( `i` int(11) default NULL ) ENGINE=ndbcluster DEFAULT CHARSET=latin1 1 row in set (0.00 sec)
Um zu prüfen, ob Ihre Knoten richtig eingerichtet sind, starten Sie den Management-Client:
shell> ndb_mgm
Innerhalb des Management-Clients geben Sie den Befehl SHOW ein, um einen Statusbericht über den Cluster zu erhalten:
NDB> SHOW
Cluster Configuration
---------------------
[ndbd(NDB)] 1 node(s)
id=2 @127.0.0.1 (Version: 3.5.3, Nodegroup: 0, Master)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @127.0.0.1 (Version: 3.5.3)
[mysqld(API)] 3 node(s)
id=3 @127.0.0.1 (Version: 3.5.3)
id=4 (not connected, accepting connect from any host)
id=5 (not connected, accepting connect from any host)
Nun haben Sie mit Erfolg einen funktionierenden MySQL Cluster
eingerichtet. In diesen Cluster können Sie jetzt aus jeder
Tabelle, die mit ENGINE=NDBCLUSTER oder
seinem Alias ENGINE=NDB angelegt wurde, Daten
laden.
- 16.4.4.1. Beispielkonfiguration eines MySQL Clusters
- 16.4.4.2. MySQL Cluster:
connectstring - 16.4.4.3. Festlegung der Computer, aus denen ein MySQL Cluster besteht
- 16.4.4.4. Festlegung des MySQL Cluster-Management-Servers
- 16.4.4.5. Festlegen von MySQL Cluster-Datenknoten
- 16.4.4.6. Festlegung von SQL-Nodes in einem MySQL Cluster
- 16.4.4.7. MySQL Cluster: TCP/IP-Verbindungen
- 16.4.4.8. MySQL Cluster: TCP/IP-Verbindungen mittels direkter Verbindungen
- 16.4.4.9. MySQL Cluster: Shared Memory-Verbindungen
- 16.4.4.10. MySQL Cluster: SCI-Transportverbindungen
Um MySQL Cluster zu konfigurieren, müssen Sie mit zwei Dateien arbeiten:
my.cnf: Hier sind Optionen für alle Executables im MySQL Cluster angegeben. Diese Datei, die Ihnen aus der früheren Arbeit mit MySQL bereits vertraut sein dürfte, muss jeder ausführbaren Datei im Cluster zugänglich sein.config.ini: Diese Datei wird nur vom Management-Server im MySQL Cluster gelesen, der dann die in ihr enthaltenen Informationen an alle Prozesse im Cluster weiterleitet.config.inienthält eine Beschreibung für jeden am Cluster beteiligten Knoten. Dazu gehören Konfigurationsparameter für Datenknoten sowie Konfigurationsparameter für Verbindungen zwischen sämtlichen Knoten im Cluster.
Wir arbeiten permanent daran, die Cluster-Konfiguration zu verbessern und diesen Prozess zu vereinfachen. Auch wenn wir uns dabei um Abwärtskompatibilität bemühen, können auch gelegentlich inkompatible Änderungen vorkommen. In solchen Fällen teilen wir den Benutzern von Cluster im Voraus mit, wenn eine Änderung nicht abwärtskompatibel ist. Wenn Sie auf eine noch undokumentierte Änderung dieser Art stoßen sollten, melden Sie sie bitte der MySQL-Bugs-Datenbank nach dem in Abschnitt 1.8, „Wie man Bugs oder Probleme meldet“, beschriebenen Verfahren.
Um MySQL Cluster zu unterstützen, müssen Sie die Datei
my.cnf so ändern, wie es im folgenden
Beispiel gezeigt wird. Bitte verwechseln Sie die hier
angegebenen Optionen nicht mit denen aus den
config.ini-Dateien. Sie können diese
Parameter auch auf der Kommandozeile angeben, wenn Sie die
Executables aufrufen.
# my.cnf # Beispiel für Ergänzungen der my.cnf für MySQL Cluster # (gilt für MySQL 5.1) # ndbcluster-Speicher-Engine aktivieren und Verbindungs-String für # Management-Server-Host anlegen (Standardport ist 1186) [mysqld] ndbcluster ndb-connectstring=ndb_mgmd.mysql.com # Verbindungs-String für Management-Server-Host anlegen (Standardport ist 1186) [ndbd] connect-string=ndb_mgmd.mysql.com # Verbindungs-String für Management-Server-Host anlegen (Standardport ist 1186) [ndb_mgm] connect-string=ndb_mgmd.mysql.com # Speicherort für Cluster-Konfigurationsdatei [ndb_mgmd] config-file=/etc/config.ini
(Weitere Informationen über Connectstrings finden Sie unter
Abschnitt 16.4.4.2, „MySQL Cluster: connectstring“.)
# my.cnf # Beispiel für Ergänzungen der my.cnf für MySQL Cluster # (funktioniert auf allen Versionen) # ndbcluster-Speicher-Engine aktivieren und Verbindungs-String für # Management-Server-Host anlegen (Standardport ist 1186 [mysqld] ndbcluster ndb-connectstring=ndb_mgmd.mysql.com:1186
Sie können in der Cluster-my.cnf-Datei
auch einen separaten
[mysql_cluster]-Abschnitt für
Einstellungen einrichten, die von allen Executables gelesen
und benutzt werden:
# Cluster-spezifische Einstellungen [mysql_cluster] ndb-connectstring=ndb_mgmd.mysql.com:1186
Die Konfigurationsdatei heißt nach Voreinstellung
config.ini. Sie wird von
ndb_mgmd beim Starten gelesen und kann an
jedem beliebigen Ort gespeichert sein. Ihr Speicherort und ihr
Name werden mit
--config-file=
auf der Kommandozeile für ndb_mgmd
angegeben. Wenn die Konfigurationsdatei nicht angegeben wurde,
versucht ndb_mgmd nach Voreinstellung, eine
Datei namens path_nameconfig.ini im aktuellen
Arbeitsverzeichnis zu lesen.
Gegenwärtig hat die Konfiguration ein INI-Format: Sie besteht
also aus Abschnitten mit Abschnittsüberschriften (in eckigen
Klammern), gefolgt von den jeweiligen Parameternamen und
-werten. Sie weicht insofern vom Standard-INI-Format ab, als
der Name und Wert eines Parameters auch durch einen
Doppelpunkt (‘:’) und nicht nur
durch das Gleichheitszeichen
(‘=’) getrennt sein können und
die Abschnitte nicht eindeutig durch einen Abschnittsnamen
identifiziert sind. Stattdessen werden eindeutige Abschnitte
(wie zum Beispiel zwei verschiedene Knoten desselben Typs)
durch eine eindeutige ID gekennzeichnet, die innerhalb des
Abschnitts als Parameter angegeben ist.
Für die meisten Parameter sind Standardwerte definiert. Diese
können auch in config.ini angegeben
sein. Um einen Abschnitt für Standardwerte anzulegen, fügen
Sie dem Abschnittsnamen einfach DEFAULT
hinzu. Zum Beispiel enthält ein
[NDBD]-Abschnitt Parameter für einen
bestimmten Datenknoten, während ein[NDBD
DEFAULT]-Abschnitt Parameter enthält, die für
sämtliche Datenknoten gelten. Wir nehmen an, dass alle
Datenknoten denselben Speicherplatz belegen. Um sie alle zu
konfigurieren, legen Sie also einen [NDBD
DEFAULT]-Abschnitt mit einer
DataMemory-Zeile an, in welcher der
Speicherplatz für die Datenknoten angegeben ist.
Die Konfigurationsdatei muss mindestens die Computer und Knoten eines Clusters aufführen und sagen, auf welchem Computer welcher Knoten residiert. Im Folgenden sehen Sie ein Beispiel einer einfachen Konfigurationsdatei für einen Cluster, der aus einem Management-Server, zwei Datenknoten und zwei MySQL Servern besteht:
# Datei "config.ini" - 2 Datenknoten und 2 SQL-Knoten # Diese Datei wird in das Startverzeichnis von ndb_mgmd (dem # Management-Server gelegt.) # Der erste MySQL Server kann von jedem Host gestartet werden, der zweite # nur vom Host mysqld_5.mysql.com [NDBD DEFAULT] NoOfReplicas= 2 DataDir= /var/lib/mysql-cluster [NDB_MGMD] Hostname= ndb_mgmd.mysql.com DataDir= /var/lib/mysql-cluster [NDBD] HostName= ndbd_2.mysql.com [NDBD] HostName= ndbd_3.mysql.com [MYSQLD] [MYSQLD] HostName= mysqld_5.mysql.com
Beachten Sie, dass jeder Knoten seinen eigenen Abschnitt in
config.ini hat. Da der vorliegende
Cluster zwei Datenknoten hat, enthält die Konfigurationsdatei
zwei [NDBD]-Abschnitte, in denen diese
Knoten definiert sind.
In der config.ini-Konfigurationsdatei
können sechs verschiedene Abschnitte benutzt werden:
[COMPUTER]: Definiert die Cluster-Hosts.[NDBD]: Definiert die Daten des Clusters nodes.[MYSQLD]: Definiert die MySQL Server-Knoten des Clusters server nodes.[MGM]or[NDB_MGMD]: Definiert den Management-Server-Knoten des Clusters.[TCP]: Definiert die TCP/IP-Verbindungen zwischen den Knoten im Cluster, wobei TCP/IP das Standardverbindungsprotokoll ist.[SHM]: Definiert Shared-Memory-Verbindungen zwischen Knoten. Früher stand dieser Verbindungtyp nur in Binaries zur Verfügung, die mit der Option--with-ndb-shmgebaut wurden. In MySQL 5.1-Max ist er nach Voreinstellung eingeschaltet, allerdings befindet sich diese Lösung noch in der Erprobungsphase.
Für jeden Abschnitt können Sie auch
DEFAULT-Werte definieren.
Cluster-Parameternamen unterscheiden im Gegensatz zu den
Parametern in my.cnf oder
my.ini nicht zwischen Groß- und
Kleinschreibung.
Mit Ausnahme des MySQL Cluster-Management-Servers (ndb_mgmd) benötigt jeder zu einem MySQL Cluster gehörige Knoten einen Verbindungs-String (Connectstring), der auf den Standort des Management-Servers verweist. Dieser Verbindungs-String wird zum Einrichten einer Verbindung mit dem Management-Server und, je nach der Rolle des Knotens im Cluster, auch für die Erfüllung anderer Aufgaben benötigt. Ein Verbindungs-String hat folgende Syntax:
<connectstring> :=
[<nodeid-specification>,]<host-specification>[,<host-specification>]
<nodeid-specification> := node_id
<host-specification> := host_name[:port_num]
node_id ist ein Integer größer 1, der
einen Knoten in config.ini bezeichnet.
host_name ist ein String, der einen
gültigen Internethostnamen oder eine IP-Adresse angibt.
port_num ist ein Integer, der auf
eine TCP/IP-Portnummer verweist.
example 1 (long): "nodeid=2,myhost1:1100,myhost2:1100,192.168.0.3:1200" example 2 (short): "myhost1"
Alle Knoten verwenden localhost:1186 als
Standardwert für den Verbindungs-String, wenn kein anderer
angegeben wird. Wenn port_num aus
dem Verbindungs-String weggelassen wird, ist 1186 der
Standardport. Dieser sollte im Netzwerk immer frei sein, da er
von der IANA genau diesen Zweck zugewiesen bekam (siehe
http://www.iana.org/assignments/port-numbers
for details).
Durch Auflistung mehrerer
<host-specification>-Werte können
Sie redundante Management-Server angeben. Ein Cluster-Knoten
wird dann versuchen, der Reihe nach mehrere Management-Server
auf jedem Host zu kontaktieren, bis er eine Verbindung
einrichten kann.
Der Verbindungs-String kann auf verschiedene Weisen angegeben werden:
Jede Executable hat ihre eigene Kommandozeilenoption, um den Management-Server beim Starten anzugeben. (In der Dokumentation finden Sie die jeweilige Executable.)
Sie können auch die Verbindungs-Strings für alle Knoten des Clusters zugleich einrichten, indem Sie sie in den
[mysql_cluster]-Abschnitt dermy.cnf-Datei des Management-Servers schreiben.Aus Gründen der Abwärtskompatibilität stehen auch zwei weitere Optionen mit gleicher Syntax zur Verfügung:
Sie können die Umgebungsvariable
NDB_CONNECTSTRINGauf den Verbindungs-String einstellen.Sie können den Verbindungs-String für jede Executable in eine Textdatei namens
Ndb.cfgschreiben und diese Datei in das Startverzeichnis der Executable legen.
Diese beiden Möglichkeiten sind jedoch inzwischen veraltet und sollten für neuere Installationen nicht mehr verwendet werden.
Wir empfehlen, den Verbindungs-String entweder auf der
Kommandozeile oder in der Datei my.cnf
für jede Executable anzugeben.
Die einzige Bedeutung des Abschnitts
[COMPUTER] besteht darin, nicht für jeden
Knoten im System Hostnamen definieren zu müssen. Alle hier
angegebenen Parameter sind obligatorisch.
IdEin Integer-Wert, der auf einen anderswo in der Konfigurationsdatei angegebenen Hostcomputer verweist.
HostNameDer Hostname oder die IP-Adresse des Computers.
Im Abschnitt [NDB_MGMD] wird das Verhalten
des Management-Servers konfiguriert. [MGM]
kann auch als Alias verwendet werden; beide Abschnittsnamen
sind äquivalent. Alle Parameter in der folgenden Liste sind
optional; wenn man sie weglässt, werden Standardwerte
verwendet. Hinweis: Wenn
weder der Parameter ExecuteOnComputer noch
ein HostName angegeben ist, wird
localhost für beide als Default
eingesetzt.
IdJeder Knoten im Cluster hat eine eindeutige Identität, die durch einen Integer-Wert zwischen 1 und 63 (einschließlich) dargestellt wird. Alle Nachrichten im Cluster sprechen den Knoten mit dieser ID an.
ExecuteOnComputerBezieht sich auf einen der im Abschnitt
[COMPUTER]aufgeführten Computer.PortNumberDie Nummer des Ports, auf welchem der Management-Server auf Konfigurationsanforderungen und Management-Befehle lauscht.
LogDestinationDieser Parameter gibt an, wohin die Logdaten für den Cluster gesandt werden: an
CONSOLE,SYSLOGoderFILE:CONSOLEgibt das Log anstdoutaus:CONSOLE
SYSLOGsendet das Log ansyslog, wobei einer der folgenden Werte verwendet wird:auth,authpriv,cron,daemon,ftp,kern,lpr,mail,news,syslog,user,uucp,local0,local1,local2,local3,local4,local5,local6oderlocal7.Hinweis: Nicht jedes Betriebssystem unterstützt alle diese Werte.
SYSLOG:facility=syslog
FILEsendet die Ausgabe des Cluster-Logs an eine normale Datei auf demselben Computer. Folgende Werte können angegeben werden:filename: Der Name der Logdatei.maxsize: Die Maximalgröße (in Bytes), auf welche die Datei anwachsen kann, ehe das Log in einer neuen Datei fortgesetzt wird. Wenn dies geschieht, wird die alte Logdatei umbenannt, indem ein.Nan ihren Dateinamen angefügt wird, wobeiNdie nächste laufende Nummer ist, die noch nicht für diesen Dateinamen eingesetzt wurde.maxfiles: Die maximale Anzahl der Logdateien.
FILE:filename=cluster.log,maxsize=1000000,maxfiles=6
In der folgenden Form können auch mehrere Logdestinationen, jeweils durch Semikola getrennt, angegeben werden:
CONSOLE;SYSLOG:facility=local0;FILE:filename=/var/log/mgmd
Der Parameter
FILEhat folgenden Standardwert:FILE:filename=ndb_.node_id_cluster.log,maxsize=1000000,maxfiles=6node_idist dabei die ID des Knotens.
ArbitrationRankMit diesem Parameter wird angegeben, welche Knoten als Arbitrator fungieren können. Nur MGM- und SQL-Knoten können Arbitrator sein. Der
ArbitrationRankcan take ist einer der folgenden Werte:0: Dieser Knoten wird nie als Arbitrator eingesetzt.1: Da dieser Knoten eine hohe Priorität hat, wird er eher als Knoten mit niedriger Priorität als Arbitrator eingesetzt.2: Ein Knoten mit niedriger Priorität, der als Arbitrator nur eingesetzt wird, wenn kein Knoten mit höherer Priorität für diesen Zweck verfügbar ist.
Normalerweise sollte der Management-Server als Arbitrator konfiguriert werden, indem sein
ArbitrationRankauf 1 (den Default) und der Rang aller SQL-Knoten auf 0 gesetzt wird.ArbitrationDelayEin Integer-Wert, der angibt, um wie viele Millisekunden die Antworten des Management-Servers auf Arbitration-Requests verzögert werden. Der Standardwert 0 muss normalerweise nicht geändert werden.
DataDirDas Verzeichnis, in dem die Ausgabedateien des Management-Servers gespeichert werden. Dazu gehören die Cluster-Logdateien, die Prozess-Ausgabedateien und die Prozess-ID (PID)-Datei des Daemons. (Für die Logdateien können Sie auch einen anderen Speicherort einstellen, indem Sie, wie weiter oben in diesem Abschnitt beschrieben, den Parameter
FILEfür dieLogDestinationeinstellen.)
Im Abschnitt [NDBD] wird das Verhalten der
Datenknoten des Clusters konfiguriert. Es gibt eine Vielzahl
Parameter für die Größen von Puffern und Pools, für
Timeout-Werte und so weiter. Die einzigen obligatorischen
Parameter sind:
entweder
ExecuteOnComputeroderHostNameder Parameter
NoOfReplicas
Diese obligatorischen Parameter müssen im Abschnitt
[NDBD DEFAULT] definiert werden.
Die meisten Parameter für Datenknoten werden im Abschnitt
[NDBD DEFAULT] gesetzt. Nur die Parameter,
von denen explizit gesagt wird, dass sie lokale Werte
einstellen können, dürfen im
[NDBD]-Abschnitt geändert werden.
HostName, Id und
ExecuteOnComputer müssen
unbedingt im lokalen
[NDBD]-Abschnitt definiert sein.
Datenknoten identifizieren
Der Wert Id (der Datenknoten-Bezeichner)
kann entweder auf der Kommandozeile beim Starten des Knotens
oder in der Konfigurationsdatei zugewiesen werden.
An jeden Parameter kann als Suffix K,
M oder G angehängt
werden, um Einheiten von 1.024, 1.024 × 1.024 oder 1.024
× 1.024 × 1.024 anzugeben. (So bedeutet
beispielsweise 100K 100 × 1.024 =
102.400.) In Parameternamen und -werten wird zwischen Groß-
und Kleinschreibung unterschieden.
IdDiese Knoten-ID ist die Adresse des Knotens für alle internen Nachrichten im Cluster. Sie ist ein Integer zwischen 1 und 63 einschließlich. Jeder Knoten im Cluster muss eine eindeutige Identität haben.
ExecuteOnComputerBezieht sich auf einen der Computer (Hosts), die im Abschnitt
COMPUTERdefiniert sind.HostNameDie Angabe dieses Parameters wirkt sich ähnlich wie die Angabe von
ExecuteOnComputeraus: Er definiert den Hostnamen des Computers, auf dem der Speicherknoten liegen soll. Wenn Sie einen anderen Hostnamen alslocalhostangeben möchten, müssen Sie entweder diesen Parameter oderExecuteOnComputerverwenden.ServerPort(OBSOLETE)Jeder Knoten im Cluster verbindet sich mit anderen Computern über einen Port. Dieser Port wird beim Einrichten der Verbindung auch für Nicht-TCP-Transporter verwendet. Der Standardport wird dynamisch in einer Weise zugewiesen, die gewährleistet, dass keine zwei Knoten auf demselben Computer die gleiche Portnummer bekommen. Daher dürfte es sich normalerweise erübrigen, einen Wert für diesen Parameter zu setzen.
NoOfReplicasDieser globale Parameter kann nur im Abschnitt
[NDBD DEFAULT]eingestellt werden und definiert, wie viele Replikas jeder Tabelle im Cluster gespeichert werden. Außerdem gibt dieser Parameter die Größe der Knotengruppen an. Eine Knotengruppe ist eine Menge von Knoten, die alle dieselben Informationen speichern.Knotengruppen werden implizit gebildet. Die erste Knotengruppe besteht aus der Menge der Datenknoten mit den niedrigsten Knoten-IDs, die nächste aus der Menge der Datenknoten mit den zweitniedrigsten IDs und so weiter. Nehmen wir als Beispiel an, wir hätten 4 Datenknoten und die
NoOfReplicaswurde auf 2 gesetzt. Die vier Datenknoten haben die IDs 2, 3, 4 und 5. Dann besteht die erste Gruppe aus den Knoten 2 und 3 und die zweite Gruppe aus den Knoten 4 und 5. Es ist wichtig, den Cluster so zu konfigurieren, dass Knoten derselben Gruppe nicht auf demselben Computer liegen, da ein einziger Hardwareabsturz dann den gesamten Cluster zerstören würde.Wenn keine Knoten-IDs angegeben werden, entscheidet die Reihenfolge der Datenknoten über ihre Zugehörigkeit zu einer Knotengruppe. Egal ob explizit zugewiesen oder nicht, die
SHOW-Ausgabe auf dem Management-Client zeigt die Knotengruppen an.NoOfReplicashat keinen Standardwert, der größtmögliche Wert beträgt 4.DataDirDieser Parameter gibt das Verzeichnis für die Trace-Dateien, Logdateien, PID-Dateien und Fehlerlogs an.
FileSystemPathDieser Parameter gibt an, in welchem Verzeichnis alle Dateien gespeichert werden, die für Metadaten, REDO-Logs, UNDO-Logs und Datendateien angelegt werden. Nach Voreinstellung ist dies das in
DataDirangegebene Verzeichnis. Hinweis: Dieses Verzeichnis muss existieren, bevor der ndbd-Prozess gestartet wird.Die empfohlene Verzeichnishierarchie für MySQL Cluster beginnt mit dem Verzeichnis
/var/lib/mysql-cluster, unter dem dann ein Verzeichnis für das Dateisystem des Knotens angelegt wird. Der Name dieses Unterverzeichnisses enthält die Knoten-ID. Wenn beispielsweise die Knoten-ID die 2 ist, heißt das Unterverzeichnisndb_2_fs.BackupDataDirDieser Parameter sagt, in welches Verzeichnis die Sicherungsdateien gespeichert werden. Wird nichts angegeben, ist ein Verzeichnis namens
BACKUPunter dem im ParameterFileSystemPathangegebenen Speicherort das Standardverzeichnis (siehe oben.)
Data Memory und Index Memory
DataMemory und
IndexMemory sind
[NDBD]-Parameter, in denen die Größe der
Speichersegmente festgelegt wird, welche die tatsächlichen
Datensätze und ihre Indizes speichern. Für die Einstellung
dieser Parameter müssen Sie unbedingt wissen, wie
DataMemory und
IndexMemory verwendet werden, da diese
Werte normalerweise an die tatsächliche Speichernutzung des
Clusters angepasst werden müssen:
DataMemoryDieser Parameter besagt, wie viel Speicherplatz (in Bytes) für die Speicherung der Datenbankeinträge zur Verfügung stehen muss. Da im Arbeitsspeicher der gesamte hier angegebene Speicherplatz zugewiesen wird, ist es extrem wichtig, dass der physikalische Arbeitsspeicher des Computers groß genug ist, um diesen auch unterbringen zu können.
Der durch
DataMemoryzugewiesene Speicher wird sowohl für die Datensätze als auch für ihre Indizes verwendet. Jeder Datensatz hat zurzeit noch eine feste Größe (sogarVARCHAR-Spalten werden als Spalten fester Breite gespeichert). Für jeden Datensatz gibt es einen Overhead von 16 Byte. Zusätzlich wird noch weiterer Platz für jeden Datensatz zugewiesen, da er in einer 32-Kbyte-Seite mit 128 Byte Seiten-Overhead gespeichert wird (siehe unten). Zudem wird für jede Seite ein wenig Platz verschwendet, da jeder Datensatz in ein- und derselben Seite gespeichert werden muss. Die Maximalgröße eines Datensatzes beträgt gegenwärtig 8.052 Byte.Der in
DataMemorydefinierte Speicherplatz wird auch zur Unterbringung von Indizes genutzt, die rund 10 Byte pro Datensatz belegen. Jede Tabellenzeile wird im geordneten Index dargestellt. Oft nehmen Anwender fälschlich an, dass alle Indizes in dem Speicher desIndexMemoryabgelegt werden, doch dies ist nicht der Fall: Nur Primärschlüssel und eindeutige Hash-Indizes nutzen diesen Speicher, während geordnete Indizes den vonDataMemoryzugewiesenen Speicher belegen. Wenn Sie jedoch einen Primärschlüssel oder einen eindeutigen Hash-Index anlegen, wird zugleich auf denselben Schlüsseln auch ein geordneter Index erzeugt, sofern Sie nicht in der IndexanweisungUSING HASHgesagt haben. Dies können Sie prüfen, indem Sie ndb_desc -ddb_nametable_nameim Management-Client ausführen.Der für das
DataMemoryzugewiesene Speicherplatz besteht aus 32-Kbyte-Seiten, die den Tabellenfragmenten zugeordnet werden. Jede Tabelle wird normalerweise in ebenso viele Fragmente partitioniert, wie der Cluster Datenknoten hat. Also sind für jeden Knoten so viele Fragmente vorhanden, wie inNoOfReplicaseingestellt sind. Gegenwärtig ist es nicht möglich, eine einmal zugewiesene Seite dem Pool der freien Seiten zurückzugeben, außer man löscht die Tabelle. Auch durch eine Knotenwiederherstellung wird die Partition kleiner, da alle Datensätze in leere Partitionen anderer Live-Knoten geschrieben werden.Der Speicherplatz im
DataMemoryenthält auch UNDO-Informationen: Bei jedem Update wird eine Kopie des unveränderten Datensatzes in dasDataMemorygeschrieben. Außerdem wird jede Kopie in den geordneten Tabellenindizes referenziert. Eindeutige Hash-Indizes werden nur aktualisiert, wenn die eindeutigen Indexspalten sich ändern. In diesem Fall wird ein neuer Eintrag in die Indextabelle eingefügt und der alte beim Committen gelöscht. Aus diesem Grunde ist es auch notwendig, genug Speicherplatz zu reservieren, um selbst die größten Transaktionen von Anwendungen, die diesen Cluster nutzen, noch behandeln zu können. Wenige große Transaktionen auszuführen ist jedenfalls nicht besser, als viele kleine zu verwenden. Dafür gibt es folgende Gründe:Große Transaktionen sind nicht schneller als kleinere.
Wenn eine Transaktion scheitert, müssen bei großen Transaktionen mehr Operationen wiederholt werden, weil sie verloren gegangen sind.
Große Transaktionen belegen mehr Speicherplatz.
Der Standardwert für das
DataMemorybeträgt 80 Mbyte und der Mindestwert 1 Mbyte. Es gibt keinen Höchstwert, aber in der Praxis muss die Maximalgröße natürlich so angepasst werden, dass der Prozess nicht anfängt, auf die Platte zu schreiben, wenn das Limit erreicht wird. Dieses Limit hängt von der Größe des auf dem Computer verfügbaren physikalischen Arbeitsspeichers ab sowie von der Frage, wie viel Speicher das Betriebssystem einem einzelnen Prozess zuweisen kann. 32-Bit-Betriebssysteme sind generell auf 2 bis 4 Gbyte pro Prozess beschränkt, während 64-Bit-Betriebssysteme mehr Speicher verwenden können. Aus diesem Grunde eignen sich 64-Bit-Systeme für große Datenbanken besser. Überdies ist es möglich, mehrere ndbd-Prozesse pro Computer auszuführen. Dies kann bei Maschinen mit mehreren CPUs Vorteile bringen.IndexMemoryDieser Parameter gibt an, wie viel Speicher für Hash-Indizes in MySQL Cluster benutzt wird. Hash-Indizes werden immer für Primärschlüsselindizes, eindeutige Indizes und Unique-Constraints verwendet. Achtung: Wenn Sie einen Primärschlüssel und einen eindeutigen Index definieren, werden zwei Indizes angelegt, von denen einer ein Hash-Index ist, der für alle Tupel-Zugriffe, für die Sperren und für die Durchsetzung von Unique-Constraints verwendet wird.
Die Größe des Hash-Indexes beträgt 25 Byte pro Datensatz plus die Größe des Primärschlüssels. Für Primärschlüssel, die mehr als 32 Byte belegen, werden weitere 8 Byte addiert.
Der Standardwert für
IndexMemorybeträgt 18 Mbyte, der Mindestwert 1 Mbyte.
Das folgende Beispiel zeigt, wie Speicher für eine Tabelle zugewiesen wird. Betrachten Sie folgende Tabellendefinition:
CREATE TABLE example ( a INT NOT NULL, b INT NOT NULL, c INT NOT NULL, PRIMARY KEY(a), UNIQUE(b) ) ENGINE=NDBCLUSTER;
Für jeden Datensatz sind 12 Byte Daten plus 12 Byte Overhead
zugewiesen. Wenn keine Spalten dabei sind, die Nullwerte
annehmen können, so spart dies 4 Byte Overhead. Außerdem
gibt es auf den Spalten a und
b zwei geordnete Indizes, die jeweils
ungefähr 10 Byte pro Datensatz belegen. Auf der Basistabelle
ist ein Primärschlüssel-Hash-Index definiert, der rund 29
Byte pro Datensatz beansprucht. Der Unique-Constraint ist
durch eine separate Tabelle implementiert, die
b als Primärschlüssel und
a als eine Spalte verwendet. Diese andere
Tabelle belegt weitere 29 Byte Indexspeicher pro Datensatz in
der example-Tabelle zuzüglich 8 Byte für
die Datensatzdaten und 12 Byte für den Overhead.
Also benötigen wir für eine Million Datensätze 58 Mbyte für den Indexspeicher, um die Hash-Indizes für den Primärschlüssel und den Unique-Constraint unterbringen zu können. Außerdem benötigen wir 64 Mbyte für die Datensätze der Basistabelle und die Tabelle mit dem eindeutigen Index plus die beiden Tabellen mit dem geordneten Index.
Wie Sie sehen, belegen Hash-Indizes nicht eben wenig Speicherplatz, bieten aber als Ausgleich einen sehr schnellen Datenzugriff. In MySQL Cluster werden sie außerdem für Unique-Constraints verwendet.
Gegenwärtig ist Hashing der einzige Partitionierungsalgorithmus und geordnete Indizes sind lokal für jeden Knoten. Also können geordnete Indizes im Allgemeinen nicht für die Handhabung von Unique-Constraints eingesetzt werden.
Ein wichtiger Punkt sowohl für das
IndexMemory als auch für das
DataMemory ist der, dass die Gesamtgröße
der Datenbank die Summe sämtlicher Daten- und Indexspeicher
für jede Knotengruppe ist. Da alle Knotengruppen verwendet
werden, um replizierte Informationen zu speichern, kommen bei
vier Knoten mit zwei Replikas zwei Knotengruppen zustande.
Also stehen jedem Datenknoten insgesamt 2 ×
DataMemory an Datenspeicher zur Verfügung.
Das DataMemory und das
IndexMemory sollten unbedingt für alle
Knoten auf denselben Wert eingestellt werden. Da die Daten
über alle Knoten im Cluster gleichmäßig verteilt sind, kann
für jeden Knoten im Cluster maximal nur so viel Speicher zur
Verfügung stehen wie für den kleinsten Knoten im Cluster.
Die Werte für DataMemory und
IndexMemory können zwar geändert werden,
doch ist es riskant, einen von beiden herunterzusetzen: Wenn
Sie dies tun, kann es leicht passieren, dass ein Knoten oder
sogar der gesamte MySQL Cluster aus Mangel an Arbeitsspeicher
nicht mehr starten kann. Das Heraufsetzen dieser Werte ist
zwar schon eher akzeptabel, aber solche Upgrades sollten
ebenso wie jeder Softwareupgrade durchgeführt werden: Zuerst
wird die Konfigurationdatei geändert, dann der
Management-Server neu hochgefahren und zum Schluss werden
nacheinander alle Datenknoten gestartet.
Durch Updates wird nicht mehr Indexspeicherplatz belegt. Einfügungen treten sofort in Kraft, aber Löschungen von Zeilen werden erst dann tatsächlich wirksam, wenn die Transaktion committed wird.
Transaktionsparameter
Die nächsten drei [NDBD]-Parameter sind
wichtig, weil sie die Anzahl der Paralleltransaktionen und die
Größe der Transaktionen festlegen, die das System
bewältigen kann.
MaxNoOfConcurrentTransactions stellt ein,
wie viele parallele Transaktionen in einem Knoten möglich
sind. MaxNoOfConcurrentOperations sagt, wie
viele Datensätze gleichzeitig geändert oder gesperrt werden
können.
Beide Parameter (besonders
MaxNoOfConcurrentOperations) werden von den
meisten Anwendern an ihre spezifischen Anforderungen angepasst
und nicht auf den Standardwerten belassen. Der Standardwert
ist auf Systeme ausgelegt, die nur kleine Transaktionen
fahren, um zu gewährleisten, dass diese nicht übermäßig
Speicher belegen.
MaxNoOfConcurrentTransactionsFür jede aktive Transaktion im Cluster muss ein Datensatz in einem der Cluster-Knoten stehen. Die Aufgabe, Transaktionen zu koordinieren, teilen sich die Knoten untereinander auf. Die Gesamtzahl der Transaktionsdatensätze im Cluster ist gleich der Anzahl der Transaktionen in einem gegebenen Knoten mal der Anzahl der Knoten im Cluster.
Transaktionsdatensätze werden einzelnen MySQL Servern zugewiesen. Normalerweise ist pro Verbindung mindestens ein Transaktionsdatensatz zugewiesen, der eine beliebige Tabelle in dem Cluster benutzen kann. Daher sollten Sie dafür sorgen, dass in einem Cluster mehr Transaktionsdatensätze als nebenläufige Verbindungen zu allen MySQL Servern im Cluster vorhanden sind.
Dieser Parameter muss für alle Cluster-Knoten auf denselben Wert gesetzt werden.
Dieser Parameter sollte nie geändert werden, da dadurch ein Cluster abstürzen kann. Wenn ein Knoten abstürzt, erstellt ein anderer Knoten (nämlich der älteste überlebende) den Status aller Transaktionen, die im Augenblick des Crashs in dem abgestürzten Knoten abliefen. Daher ist es wichtig, dass dieser Knoten so viele Transaktionsdatensätze wie der abgestürzte Knoten hat.
Der Standardwert ist 4096.
MaxNoOfConcurrentOperationsDiesen Parameter sollte man immer an die Größe und Anzahl der Transaktionen anpassen. Wenn Ihre Transaktionen immer nur wenige Operationen ausführen und nicht viele Datensätze betreffen, besteht kein Anlass, diesen Parameter auf einen hohen Wert zu setzen. Doch für große Transaktionen mit vielen Datensätzen sollten Sie ihn heraufsetzen.
Für jede Transaktion, die Cluster-Daten ändert, werden sowohl im Transaktionskoordinator als auch in den Knoten, wo die eigentlichen Änderungen eintreten, Aufzeichnungen gemacht. Diese Einträge enthalten Statusinformationen, die erforderlich sind, um die UNDO-Datensätze für Rollback, Lock Queues und andere Sätze zu erhalten.
Dieser Parameter sollte auf die Anzahl der in Transaktionen gleichzeitig zu ändernden Datensätze, dividiert durch die Anzahl der Datenknoten im Cluster, gesetzt werden. In einem Cluster, der 4 Datenknoten hat und 1.000.000 nebenläufige Updates bewältigen soll, beträgt dieser Wert 1.000.000 / 4 = 250.000.
Auch durch Leseanfragen, die Sperren setzen, werden Operationseinträge erzeugt. Für diese wird in den einzelnen Knoten etwas mehr Speicherplatz reserviert, um mit Fällen umgehen zu können, in denen die Verteilung über die Knoten nicht perfekt ist.
Wenn Abfragen den eindeutigen Hash-Index verwenden, gibt es sogar zwei Operationseinträge pro Transaktionsdatensatz. Der erste stellt den Lesevorgang in der Indextabelle dar und der zweite betrifft die Operation auf der Basistabelle.
Der Standardwert ist 32768.
Dieser Parameter steuert in Wirklichkeit zwei separat konfigurierbare Werte. Der erste gibt an, wie viele Operationseinträge mit dem Transaktionskoordinator gesetzt werden, und der zweite, wie viele Operationseinträge lokal in der Datenbank gemacht werden.
Eine sehr große Transaktion auf einem Cluster mit 8 Knoten erfordert im Transaktionskoordinator so viele Operationseinträge, wie es Lese-, Änderungs- und Einfügungsoperationen in der Transaktion gibt. Dabei werden die Operationseinträge allerdings über alle 8 Knoten verteilt. Also sollten die beiden Teile getrennt konfiguriert werden, wenn das System auf eine einzelne sehr große Transaktion vorbereitet werden soll. Anhand von
MaxNoOfConcurrentOperationswird immer berechnet, wie viele Operationseinträge es in dem Teil des Knotens gibt, wo der Transaktionskoordinator sitzt.Zudem ist es wichtig, eine ungefähre Vorstellung des Speicherbedarfs für die Operationseinträge zu haben: Diese belegen pro Eintrag ungefähr 1 Kbyte.
MaxNoOfLocalOperationsNach Voreinstellung wird dieser Parameter zu 1,1 ×
MaxNoOfConcurrentOperationsberechnet. Dies eignet sich für Systeme mit vielen simultanen Transaktionen, die jedoch alle nicht sehr umfangreich sind. Wenn Sie immer nur eine einzige, dafür aber sehr große Transaktion und zudem viele Knoten haben, sollten Sie den Standardwert dieses Parameters mit einem geeigneteren überschreiben.
Temporärer Speicher für Transaktionen
Die nächste Gruppe von [NDBD]-Parametern
entscheidet über die temporäre Speicherung, die zur
Ausführung einer Anweisung in einer Cluster-Transaktion
verwendet wird. Alle Datensätze werden freigegeben, wenn die
Anweisung abgeschlossen ist und der Cluster auf den Commit-
oder Rollback-Befehl wartet.
Die Standardwerte für diese Parameter sind für die meisten Situationen passend. Wenn Sie jedoch Transaktionen auf sehr vielen Zeilen oder mit sehr vielen Operationen ausführen müssen, müssen Sie diese Werte eventuell heraufsetzen, um eine bessere Parallelverarbeitung im System zu ermöglichen. Sollten Ihre Transaktionen dagegen relativ klein sein, so können Sie durch Reduzieren dieser Werte Speicherplatz sparen.
MaxNoOfConcurrentIndexOperationsFür Anfragen, die einen eindeutigen Hash-Index verwenden, wird während der Ausführungsphase eine weitere Gruppe von Operationseinträgen erstellt. Dieser Parameter stellt die Größe dieses Pools an Einträgen ein. Also wird dieser Eintrag nur während der Ausführung eines Teils einer Anfrage zugewiesen. Sobald dieser Teil abgeschlossen ist, wird der Eintrag wieder freigegeben. Der Zustand, in dem Transaktionen abgebrochen oder committet werden, wird von den normalen Operationseinträgen behandelt, deren Pool-Größe durch den Parameter
MaxNoOfConcurrentOperationseingestellt wird.Dieser Parameter hat den Standardwert 8192. Nur in seltenen Fällen, in denen extrem hoher Parallelismus auftritt und eindeutige Hash-Indizes verwendet werden, kann es erforderlich sein, diesen Wert zu erhöhen. Auch ein kleinerer Wert ist möglich und kann Speicherplatz sparen, wenn der DBA sich sicher ist, dass für den Cluster kein besonders hoher Parallelismus erforderlich ist.
MaxNoOfFiredTriggersDer Standardwert von
MaxNoOfFiredTriggersist 4000 und dürfte für die meisten Situationen ausreichen. In manchen Fällen kann er sogar heruntergesetzt werden, wenn der DBA sich sicher ist, dass in dem Cluster kein besonderer Parallelismus auftritt.Wenn eine Operation ausgeführt wird, wird ein Datensatz angelegt, der einen eindeutigen Hash-Index beeinflusst. Eine Einfügung oder Löschung eines Eintrags in einer Tabelle mit eindeutigen Hash-Indizes oder eine Aktualisierung einer Spalte, die Teil eines eindeutigen Hash-Indexes ist, löst eine entsprechende Einfügung oder Löschung in der Indextabelle aus. Der resultierende Eintrag wird verwendet, um diese Indextabellenoperation zu repräsentieren, so lange die Originaloperation, die ihn veranlasste, noch nicht abgeschlossen ist. Diese Operation ist zwar kurzlebig, kann aber dennoch viele Einträge in ihrem Pool benötigen, wenn viele parallele Schreiboperationen auf einer Basistabelle stattfinden, die eine Reihe von eindeutigen Hash-Indizes enthält.
TransactionBufferMemoryDieser Parameter betrifft den Speicher zum Nachvollziehen von Operationen, die bei der Aktualisierung von Indextabellen und beim Lesen von eindeutigen Indizes auftreten. In diesem Arbeitsspeicherbereich werden die Schlüssel- und Spalteninformationen für diese Operationen gespeichert. Nur in seltenen Fällen muss dieser Parameter auf einen anderen als seinen Standardwert gesetzt werden.
Normale Lese- und Schreiboperationen nutzen einen ähnlichen Puffer, der sogar noch kurzfristiger arbeitet. Der zur Übersetzungszeit benutzte Parameter
ZATTRBUF_FILESIZE(ausndb/src/kernel/blocks/Dbtc/Dbtc.hpp) ist auf 4.000 × 128 Byte (500 Kbyte) eingestellt. Ein ähnlicher Puffer für die Schlüsselinformationen, nämlichZDATABUF_FILESIZE(ebenfalls inDbtc.hpp), bietet 4.000 × 16 = 62,5 Kbyte Speicherplatz.Dbtcist das Modul, welches sich um die Transaktionskoordination kümmert.
Scans und Datenpuffer
Das Modul Dblqh hat noch weitere
[NDBD]-Parameter (in
ndb/src/kernel/blocks/Dblqh/Dblqh.hpp),
die sich auf Lese- und Änderungsoperationen auswirken.
Hierzu gehören die ZATTRINBUF_FILESIZE,
die auf 10.000 × 128 Byte (1250 Kbyte) voreingestellt
ist, und ZDATABUF_FILE_SIZE mit dem
Standardwert 10.000 * 16 Byte (rund 156 Kbyte) Speicherplatz
im Puffer. Bisher haben weder Anwender noch die Ergebnisse
unserer umfangreichen Tests je eine Erhöhung dieser
Compile-Time-Limits nahe gelegt.
Der Standardwert für
TransactionBufferMemory ist 1 Mbyte.
MaxNoOfConcurrentScansDieser Parameter stellt ein, wie viele parallele Scans im Cluster ausgeführt werden können. Jeder Transaktionskoordinator kann so viele parallele Scans bewältigen, wie dieser Parameter festlegt. Jede Scananfrage wird durch paralleles Scannen aller Partitionen ausgeführt. Jeder Partitionsscan verwendet einen Scandatensatz in dem Knoten, auf dem sich die Partition befindet, wobei die Anzahl der Einträge der Wert dieses Parameters mal die Anzahl der Knoten ist. Der Cluster sollte in der Lage sein,
MaxNoOfConcurrentScansnebenläufige Scans auf allen Knoten im Cluster zu bewältigen.Scans werden tatsächlich in zwei Fällen ausgeführt: erstens wenn kein Hash-Index oder geordneter Index für die Ausführung der Anfrage vorliegt; in diesem Fall wird die Anfrage mithilfe eines vollständigen Tabellenscans ausgeführt. Zweitens, wenn für die Anfrage zwar kein Hash-Index, aber ein geordneter Index vorhanden ist, denn die Verwendung eines geordneten Indexes erfordert zusätzlich einen parallelen Bereichsscan. Da die Reihenfolge nur auf den lokalen Partitionen beibehalten wird, muss der Indexscan auf allen Partitionen ausgeführt werden.
Der Standardwert von
MaxNoOfConcurrentScansist 256 und der Höchstwert beträgt 500.Dieser Parameter gibt an, wie viele Scans im Transaktionskoordinator möglich sind. Wenn keine Anzahl für lokale Scandatensätze vorgegeben ist, wird sie als
MaxNoOfConcurrentScansmal der Anzahl der Datenknoten im System berechnet.MaxNoOfLocalScansGibt die Anzahl der lokalen Scandatensätze an, wenn viele Scans nicht vollständig parallelisiert sind.
BatchSizePerLocalScanDieser Parameter wird genutzt, um zu berechnen, wie viele Sperrdatensätze erforderlich sind, um viele nebenläufige Scanoperationen zu handhaben.
Der Standardwert beträgt 64; dieser Wert steht in enger Verbindung zur in den SQL-Knoten definierten
ScanBatchSize.LongMessageBufferDies ist ein interner Puffer für die Weitergabe von Nachrichten in oder zwischen Knoten. Der Wert muss zwar wahrscheinlich nie geändert werden, ist aber dennoch konfigurierbar. Sein Standardwert beträgt 1 Mbyte.
Logging und Checkpointing
Die folgenden [NDBD]-Paramater steuern das
Verhalten in Bezug auf Logs und Checkpoints.
NoOfFragmentLogFilesDieser Parameter stellt die Größe der REDO-Logdateien des Knotens ein. REDO-Logdateien sind ringförmig organisiert, wobei es außerordentlich wichtig ist, dass die erste und die letzte Logdatei (auch „Head“ und „Tail“ genannt) nicht aufeinander treffen. Wenn sich diese beiden zu stark annähern, fängt der Knoten an, alle Transaktionen abzubrechen, in denen Updates vorkommen, da kein Platz für neue Logeinträge mehr vorhanden ist.
Ein REDO-Logeintrag wird erst gelöscht, wenn seit seiner Einfügung drei lokale Checkpoints erreicht wurden. Die Häufigkeit der Checkpoints wird durch eigene Konfigurationsparameter festgelegt, die an anderer Stelle in diesem Kapitel beschrieben werden.
Der Standardparameterwert beträgt 8, also 8 mal 4 16-Mbyte-Dateien oder insgesamt 512 Mbyte. Mit anderen Worten: Der Speicher für die REDO-Logs muss in Blöcken zu 64 Mbyte zugewiesen werden. In Szenarien, in denen viele Updates erforderlich sind, kann es erforderlich werden, den Wert von
NoOfFragmentLogFilessogar auf 300 oder noch mehr zu setzen, um genügend Platz für die REDO-Logs zu schaffen.Wenn das Checkpointing zu langsam läuft und so viele Schreibvorgänge in der Datenbank stattfinden, dass die Logdateien voll laufen und der Logtail nicht abgetrennt werden kann, ohne die Wiederherstellung zu gefährden, können Änderungstransaktionen mit dem internen Fehlercode 410 (
Out of log file space temporarily) abgebrochen werden. Dies dauert so lange, bis ein Checkpoint abgeschlossen ist und der Logtail vorrücken kann.MaxNoOfSavedMessagesDieser Parameter stellt ein, wie viele Trace-Dateien maximal gespeichert werden, ehe die alten überschrieben werden. Trace-Dateien werden angelegt, wenn der Knoten aus irgendeinem Grund abstürzt.
Der Standardwert sind 25 Trace-Dateien.
Metadatenobjekte
Die folgenden [NDBD]-Parameter legen die
Größen der Pools für Metadatenobjekte fest, also wie viele
Attribute, Tabellen, Indizes und Trigger-Objekte maximal für
die Indizes, Ereignisse und Replikation zwischen Clustern zur
Verfügung stehen. Beachten Sie, dass diese Werte lediglich
„Richtwerte“ für den Cluster sind. Werden sie
nicht gesetzt, so treten die unten angegebenen Standardwerte
in Kraft.
MaxNoOfAttributesGibt an, wie viele Attribute im Cluster definiert werden können.
Der Standardwert beträgt 1.000 und der kleinstmögliche Wert 32. Einen Höchstwert gibt es nicht. Jedes Attribut belegt rund 200 Byte Speicherplatz pro Knoten, da alle Metadaten vollständig auf den Servern repliziert werden.
Bei der Einstellung von
MaxNoOfAttributesmüssen Sie sich schon im Voraus klar machen, wie vieleALTER TABLE-Anweisungen Sie wohl in Zukunft ausführen möchten. Denn wenn SieALTER TABLEauf einer Cluster-Tabelle ausführen, werden dreimal so viele Attribute wie in der Originaltabelle verwendet. Wenn eine Tabelle beispielsweise 100 Attribute benötigt und Sie in der Lage sein möchten, diese Tabelle später noch zu ändern, müssen Sie den Wert vonMaxNoOfAttributesauf 300 setzen. Wenn wir voraussetzen, dass Sie alle gewünschten Tabellen ohne irgendwelche Probleme anlegen können, sollten SieMaxNoOfAttributessicherheitshalber doppelt so viele Attribute hinzufügen, wie die größte Tabelle besitzt. Außerdem sollten Sie nach der Konfiguration des Parameters mit einem echtenALTER TABLEprüfen, ob diese Zahl ausreicht. Wenn die Anweisung scheitert, müssen SieMaxNoOfAttributesum ein anderes Vielfaches des ursprünglichen Werts erhöhen und erneut testen.MaxNoOfTablesFür jede Tabelle, jeden eindeutigen Hash-Index und jeden geordneten Index wird ein Tabellenobjekt zugewiesen. Dieser Parameter stellt ein, wie viele Tabellenobjekte der Cluster insgesamt maximal haben kann.
Für jedes Attribut vom Typ
BLOBwird eine zusätzliche Tabelle verwendet, um einen Großteil derBLOB-Daten zu speichern. Auch diese Tabellen müssen beim Festlegen der Gesamtzahl der Tabellen berücksichtigt werden.Dieser Parameter ist standardmäßig auf 128 eingestellt. Sein Mindestwert beträgt 8 und sein Höchstwert 1600. Jedes Tabellenobjekt belegt rund 20 Kbyte pro Knoten.
MaxNoOfOrderedIndexesFür jeden geordneten Index im Cluster wird ein Objekt zugewiesen, das beschreibt, was hier indiziert wird und in welchen Speichersegmenten. Nach Voreinstellung ist jeder so definierte Index ein geordneter Index. Jeder eindeutige Index und jeder Primärschlüssel besitzt sowohl einen geordneten als auch einen Hash-Index.
Dieser Parameter hat den Standardwert 128. Jedes Objekt belegt ungefähr 10 Kbyte pro Knoten.
MaxNoOfUniqueHashIndexesFür jeden eindeutigen Index, der kein Primärschlüssel ist, wird eine spezielle Tabelle zugewiesen, die den eindeutigen Schlüssel auf den Primärschlüssel der indizierten Tabelle abbildet. Nach Voreinstellung wird außerdem für jeden eindeutigen Index ein geordneter Index definiert. Wenn Sie dies verhindern möchten, müssen Sie beim Definieren des eindeutigen Indexes die Option
USING HASHangeben.Der Standardwert ist 64. Jeder Index belegt ungefähr 15 Kbyte pro Knoten.
MaxNoOfTriggersFür jeden eindeutigen Hash-Index werden interne Update-, Insert- und Delete-Trigger zugewiesen. (Das bedeutet, dass für jeden solchen Index drei Trigger erzeugt werden.) Ein geordneter Index erfordert dagegen nur ein einziges Trigger-Objekt. Auch Datensicherungen benötigen drei Trigger-Objekte für jede normale Tabelle im Cluster.
Hinweis: Wenn Replikation zwischen Clustern unterstützt wird, sind auch dafür interne Trigger erforderlich.
Dieser Parameter stellt die Höchstzahl der Trigger-Objekte im Cluster ein.
Der Standardwert ist 768.
MaxNoOfIndexesDieser Parameter ist in MySQL 5.1 veraltet. Bitte verwenden Sie stattdessen
MaxNoOfOrderedIndexesundMaxNoOfUniqueHashIndexes.Dieser Parameter wird nur von eindeutigen Hash-Indizes verwendet. Für jeden derartigen Index, der im Cluster definiert ist, muss ein Datensatz in diesem Pool vorhanden sein.
Der Standardwert dieses Parameters ist 128.
Boolesche Parameter
Das Verhalten der Datenknoten hängt auch von einigen
booleschen [NDBD]-Parametern ab. Um diese
Parameter auf TRUE einzustellen, setzen Sie
sie auf 1 oder Y, und um
sie auf FALSE einzustellen, setzen Sie sie
auf 0 oder N.
LockPagesInMainMemoryViele Betriebssysteme, darunter auch Solaris und Linux, können einen Prozess im Arbeitsspeicher sperren und dadurch verhindern, dass er auf die Festplatte schreibt. Das kann dabei helfen, die Echtzeitfähigkeiten eines Clusters zu bewahren.
Dieses Feature ist nach Voreinstellung deaktiviert.
StopOnErrorDieser Parameter zeigt an, ob ein ndbd-Prozess anhalten oder automatisch neu starten soll, wenn eine Fehlerbedingung auftritt.
Dieses Feature ist nach Voreinstellung aktiviert.
DisklessWenn Tabellen im MySQL Cluster als diskless definiert werden, werden für sie weder Checkpoints auf der Festplatte noch Logeinträge erstellt. Solche Tabellen existieren nur im Hauptspeicher. Infolgedessen überleben weder die Tabellen selbst noch die in ihnen enthaltenen Datensätze einen Absturz. Allerdings können Sie im Diskless-Modus ndbd auch auf einem Computer ohne Festplatte ausführen.
Wichtig: Dieses Feature lässt den gesamten Cluster im Diskless-Modus laufen.
Wenn dieses Feature aktiviert ist, werden zwar Datensicherungen ausgeführt, aber keine wirklichen Sicherungsdaten gespeichert.
Disklessist nach Voreinstellung deaktiviert.RestartOnErrorInsertDieses Feature ist nur beim Bauen der Debugversion zugänglich, wo es möglich ist, zu Testzwecken Fehler in die Ausführung einzelner Codeblöcke einzubauen.
Dieses Feature ist nach Voreinstellung deaktiviert.
Timeouts, Intervalle und Auslagerung von Daten auf die Festplatte
Mehrere [NDBD]-Parameter stehen zur
Verfügung, um Timeouts und Intervalle zwischen verschiedenen
Aktionen in Cluster-Datenknoten festzulegen. Die Timeout-Werte
werden, sofern nicht explizit etwas anderes gesagt wird, in
Millisekunden angegeben.
TimeBetweenWatchDogCheckDamit der Haupt-Thread nicht in einer Endlosschleife gefangen bleiben kann, wird er durch einen so genannten „Wachhund“ (engl. Watchdog) überprüft. Dieser Parameter gibt an, wie viele Millisekunden zwischen den Prüfungen verstreichen. Wenn der Prozess nach drei Prüfungen immer noch in demselben Zustand verharrt, wird er vom Watchdog-Thread beendet.
Dieser Parameter lässt sich leicht ändern, sei es zu experimentellen Zwecken oder um ihn an die lokalen Bedingungen anzupassen. Er kann auch für jeden Knoten separat gesetzt werden, wofür es allerdings keinen vernünftigen Grund gibt.
Der Standard-Timeout-Wert beträgt 4.000 Millisekunden (4 Sekunden).
StartPartialTimeoutDieser Parameter legt fest, wie lange der Cluster auf das Hochfahren aller Speicherknoten wartet, bevor die Initialisierungsroutine für den Cluster aufgerufen wird. Dieser Timeout-Wert soll nach Möglichkeit verhindern, dass ein Cluster nur teilweise hochgefahren wird.
Der Standardwert beträgt 30.000 Millisekunden (30 Sekunden). Mit 0 wird der Timeout ausgeschaltet, sodass der Cluster nur starten kann, wenn alle Knoten zur Verfügung stehen.
StartPartitionedTimeoutWenn der Cluster nach dem Abwarten von
StartPartialTimeoutMillisekunden startbereit ist, sich aber möglicherweise immer noch in einem partitionierten Zustand befindet, wartet er ab, bis auch dieser Timeout verstrichen ist.Der Standardwert für diesen Timeout beträgt 60.000 Millisekunden (60 Sekunden).
StartFailureTimeoutWenn ein Datenknoten seine Startsequenz in der durch diesen Parameter gesetzten Zeit nicht abgeschlossen hat, scheitert sein Start. Wenn Sie den Parameter auf 0 setzen, gibt es keinen Timeout für den Datenknoten.
Der Standardwert beträgt 60.000 Millisekunden (60 Sekunden). Für Datenknoten mit extrem großen Datenmengen sollten Sie diesen Parameter heraufsetzen. Wenn ein Speicherknoten beispielsweise mehrere Gigabytes an Daten enthält, könnten sogar 10 bis 15 Minuten (600.000 bis 1.000.000 Millisekunden) für einen Neustart des Knotens erforderlich sein.
HeartbeatIntervalDbDbHeartbeats (Herzschläge) sind eines der wichtigsten Mittel, um herauszufinden, ob Knoten abgestürzt sind. Dieser Parameter zeigt an, wie oft Heartbeat-Signale gesandt und empfangen werden sollten. Wenn drei aufeinander folgende Heartbeats ausgefallen sind, wird der Knoten für tot erklärt. Also beträgt die maximale Zeitspanne für die Entdeckung eines Scheiterns mit dem Heartbeat-Mechanismus das Vierfache des Heartbeat-Intervalls.
Das Standardintervall für Heartbeats dauert 1.500 Millisekunden (1,5 Sekunden). Dieser Parameter darf nicht drastisch verändert werden und sollte für alle Knoten ähnlich eingestellt werden. Wenn ein Knoten 5.000-Millisekunden-Intervalle und der beobachtende Knoten 1.000 Millisekunden verwendet, wird der mit den längeren Intervallen natürlich sehr schnell für tot erklärt. Dieser Parameter kann während eines Online-Softwareupgrades geändert werden, allerdings nur in kleinen Inkrementen.
HeartbeatIntervalDbApiJeder Datenknoten sendet Heartbeat-Signale an jeden MySQL Server (SQL-Knoten), um sich zu vergewissern, dass der Kontakt noch besteht. Wenn ein MySQL Server seinen Heartbeat nicht rechtzeitig absendet, wird er als „tot“ erklärt und alle seine laufenden Transaktionen werden beendet und seine Ressourcen freigegeben. Ein SQL-Knoten kann sich erst wieder verbinden, wenn alle von der vorherigen MySQL-Instanz angestoßenen Aktivitäten abgeschlossen wurden. Es gilt dasselbe Kriterium der drei Heartbeats wie unter
HeartbeatIntervalDbDbbeschrieben.Das Standardintervall beträgt 1.500 Millisekunden (1,5 Sekunden). Dieses Intervall kann zwischen einzelnen Datenknoten variieren, da jeder Speicherknoten die mit ihm verbundenen MySQL Server unabhängig von allen anderen Datenknoten beobachtet.
TimeBetweenLocalCheckpointsDieser Parameter ist insofern eine Ausnahmeerscheinung, als er nicht eine Wartezeit vor dem Starten eines neuen lokalen Checkpoints angibt, sondern gewährleisten soll, dass keine lokalen Checkpoints in einem Cluster ausgeführt werden, in dem nur relativ wenige Updates auftreten. In den meisten Clustern mit hohen Update-Raten wird ein neuer lokaler Checkpoint normalerweise unmittelbar nach Abschluss des vorherigen gestartet.
Der Umfang aller seit dem Start des vorherigen lokalen Checkpoints ausgeführten Schreiboperationen wird addiert. Dieser Parameter ist ebenfalls außergewöhnlich, da er als Basis-2-Logarithmus der Anzahl der 4-Byte-Wörter spezifiziert ist. Der Standardwert von 20 bedeutet also Schreiboperationen im Umfang von 4 Mbyte (4 × 220), 21 würde 8 Mbyte bedeuten, und so weiter bis zum Maximalwert 31, der 8 Gbyte Schreiboperationen entsprechen würde.
Alle Schreiboperationen im Cluster werden addiert. Wenn
TimeBetweenLocalCheckpointsauf 6 oder weniger gesetzt wird, bedeutet dies, dass pausenlos lokale Checkpoints ausgeführt werden, unabhängig von der Arbeitslast des Clusters.TimeBetweenGlobalCheckpointsWenn eine Transaktion committet wird, dann im Hauptspeicher in allen Knoten, auf denen die Daten gespiegelt werden. Doch die Transaktionslog-Einträge werden durch den Commit-Befehl nicht auf die Platte zurückgeschrieben. Denn wenn die Transaktion auf mindestens zwei autonomen Hostcomputern sicher committet wurde, müsste dies ausreichen, um die Haltbarkeit der Daten zu gewährleisten.
Wichtig ist außerdem, dass das System auch im schlimmsten Fall, nämlich dem Absturz eines kompletten Clusters, die Oberhand behält. Um das zu gewährleisten, werden alle Transaktionen, die in einem gegebenen Zeitraum stattfinden, in einen globalen Checkpoint geladen. Diesen kann man sich als eine Menge von committeten und auf die Festplatte geschriebenen Transaktionen vorstellen. Mit anderen Worten: Transaktionen werden im Rahmen des Commit-Prozesses in eine globale Checkpoint-Gruppe gelegt. Später werden die Logeinträge dieser Gruppe auf die Festplatte zurückgeschrieben und die gesamte Transaktionsgruppe auf allen Computern im Cluster sicher auf die Festplatte geschrieben.
Dieser Parameter legt das Zeitintervall zwischen den globalen Checkpoints fest. Der Standardwert beträgt 2.000 Millisekunden.
TimeBetweenInactiveTransactionAbortCheckUm Timeouts zu behandeln, wird für jede Transaktion einmal pro in diesem Parameter angegebenem Intervall ein Timer nachgeschaut. Wenn also dieser Parameter auf 1.000 Millisekunden gesetzt ist, wird einmal pro Sekunde jede Transaktion auf einen Timeout überprüft.
Der Standardwert beträgt 1.000 Millisekunden (1 Sekunde).
TransactionInactiveTimeoutDieser Parameter gibt an, wie viel Zeit maximal zwischen zwei Operationen einer Transaktion verstreichen darf, ehe die Transaktion abgebrochen wird.
Der Standardwert dieses Parameters ist null (kein Timeout). Für eine Echtzeitdatenbank, die gewährleisten muss, dass keine Transaktion irgendwelche Sperren zu lange aufrechterhält, sollte dieser Parameter auf einen sehr kleinen Wert gesetzt werden. Die Maßeinheit sind Millisekunden.
TransactionDeadlockDetectionTimeoutWenn ein Knoten eine Abfrage ausführt, zu der eine Transaktion gehört, wartet er auf Antwort von den anderen Knoten des Clusters, ehe er fortfährt. Bleibt eine Antwort aus, kann das folgende Gründe haben:
Der Knoten ist „tot“.
Die Operation steckt in einer Warteschlange von Sperranforderungen.
Der Knoten, der die Aktion ausführen sollte, könnte heftig überlastet sein.
Dieser Timeout-Parameter legt fest, wie lange der Transaktionskoordinator darauf wartet, dass ein anderer Knoten die Anfrage ausführt, ehe er die Transaktion abbricht. Er ist wichtig, um den Absturz eines Knotens behandeln oder Deadlocks feststellen zu können. Wenn Sie ihn zu hoch setzen, können Situationen mit gescheiterten Knoten oder Deadlocks unangenehme Konsequenzen haben.
Der Standardwert für den Timeout beträgt 1.200 Millisekunden (1,2 Sekunden).
NoOfDiskPagesToDiskAfterRestartTUPWenn ein lokaler Checkpoint ausgeführt wird, schreibt der Algorithmus alle Datenseiten auf die Festplatte zurück. Wenn Sie dies aber einfach ohne irgendwelche Moderation so rasch wie möglich tun, riskieren Sie eine Überlastung von Prozessoren, Netzwerken und Platten. Um die Schreibgeschwindigkeit zu steuern, gibt dieser Parameter an, wie viele Seiten pro 100 Millisekunden geschrieben werden dürfen. In diesem Zusammenhang ist eine „Seite“ als 8 Kbyte definiert. Dieser Parameter wird in Einheiten von 80 Kbyte pro Sekunde angegeben; wenn Sie also
NoOfDiskPagesToDiskAfterRestartTUPauf den Wert20setzen, werden bei einem lokalen Checkpoint 1,6 Mbyte an Datenseiten pro Sekunde auf die Platte geschrieben. Dieser Wert umfasst auch die Erstellung der UNDO-Logs für die Datenseiten. Folglich setzt dieser Parameter die Obergrenze für Schreibvorgänge aus dem Data Memory. Für die UNDO-Logeinträge für Indexseiten ist der ParameterNoOfDiskPagesToDiskAfterRestartACCda. (Mehr über Indexseiten können Sie im EintragIndexMemorynachlesen.)Kurz: Dieser Parameter gibt an, wie schnell lokale Checkpoints ausgeführt werden. Er arbeitet zusammen mit
NoOfFragmentLogFiles,DataMemoryundIndexMemory.Der Standardwert ist 40 (3,2 Mbyte Datenseiten pro Sekunde).
NoOfDiskPagesToDiskAfterRestartACCDieser Parameter verwendet dieselbe Maßeinheit wie
NoOfDiskPagesToDiskAfterRestartTUPund verhält sich auch ganz ähnlich, setzt jedoch die Obergrenze für das Schreiben von Indexseiten aus dem Index Memory.Der Standardwert dieses Parameters beträgt 20 (1,6 Mbyte Index Memory pro Sekunde).
NoOfDiskPagesToDiskDuringRestartTUPDieser Parameter funktioniert ähnlich wie
NoOfDiskPagesToDiskAfterRestartTUPundNoOfDiskPagesToDiskAfterRestartACC, allerdings im Hinblick auf lokale Checkpoints, die in einem Knoten bei dessen Neustart ausgeführt werden. Ein lokaler Checkpoint wird immer bei jeglichem Neustart eines Knotens ausgeführt. Während eines Knoten-Neustarts können Daten schneller als in anderen Situationen auf die Platte geschrieben werden, da zu diesem Zeitpunkt im Knoten noch weniger andere Aktivitäten stattfinden.Dieser Parameter bezieht sich auf die Seiten, die aus dem Data Memory geschrieben werden.
Der Standardwert beträgt 40 (3,2 Mbyte pro Sekunde).
NoOfDiskPagesToDiskDuringRestartACCGibt an, wie viele Seiten des Index Memorys während des lokalen Checkpointings beim Neustart eines Knotens auf die Festplatte geschrieben werden können.
Wie bei
NoOfDiskPagesToDiskAfterRestartTUPundNoOfDiskPagesToDiskAfterRestartACCwerden auch für diesen Parameter die Werte als 8-Kbyte-Seiten angegeben, die pro 100 Millisekunden geschrieben werden (80 Kbyte/Sekunde).Der Standardwert beträgt 20 (1,6 Mbyte pro Sekunde).
ArbitrationTimeoutDieser Parameter legt fest, wie lange Datenknoten darauf warten sollen, dass der Arbitrator auf eine Arbitration-Nachricht antwortet. Wird dieser Wert überschritten, kann man davon ausgehen, dass sich das Netzwerk aufgespalten hat.
Der Standardwert beträgt 1000 Millisekunden (1 Sekunde).
Buffering und Logging
Es stehen auch mehrere
[NDBD]-Konfigurationsparameter zur
Verfügung, die den früheren Compile-Time-Parametern
entsprechen. Mit ihnen kann der fortgeschrittene Anwender die
von Knotenprozessen genutzten Ressourcen besser steuern und
diverse Puffergrößen seinen Bedürfnissen anpassen.
Diese Puffer werden als Frontends für das Dateisystem
verwendet, wenn Logeinträge auf die Platte geschrieben
werden. Wenn der Knoten im Diskless-Modus läuft, können
diese Parameter ungestraft auf ihre Mindestwerte gesetzt
werden, da die Dateisystem-Abstraktionsschicht der
Speicher-Engine NDB das Schreiben auf der
Festplatte „vorgaukelt“.
UndoIndexBufferDer UNDO-Indexpuffer, dessen Größe mit diesem Parameter eingestellt wird, wird während eines lokalen Checkpoints benutzt. Das Recovery-Schema der Speicher-Engine
NDBberuht auf der Konsistenz der Checkpoints und einem funktionierenden REDO-Log. Um einen konsistenten Checkpoint zu erhalten, ohne gleich sämtliche Schreibvorgänge im System zu blockieren, ist während der Erstellung des lokalen Checkpoints das UNDO-Logging eingeschaltet. UNDO-Logging wird immer nur auf einem einzigen Tabellenfragment eingeschaltet. Diese Optimierung ist möglich, da die Tabellen vollständig im Hauptspeicher liegen.Der UNDO-Indexpuffer wird für die Änderungen am Primärschlüssel-Hash-Index benutzt. Einfügungen und Löschungen führen zu Umstellungen im Hash-Index. Die Speicher-Engine NDB schreibt UNDO-Logeinträge, die alle physikalischen Änderungen einer Indexseite zuordnen, sodass sie beim Systemstart rückgängig gemacht werden können. Außerdem protokolliert sie zu Beginn eines lokalen Checkpoints alle aktiven Einfügeoperationen für jedes Fragment.
Lese- und Änderungsoperationen setzen Sperrbits und aktualisieren einen Header im Hash-Indexeintrag. Diese Änderungen behandelt der Page-Writing-Algorithmus so, dass sichergestellt ist, dass diese Operationen kein UNDO-Logging benötigen.
Dieser Puffer ist nach Voreinstellung auf 2 Mbyte gesetzt. Sein Mindestwert 1 Mbyte dürfte für die meisten Anwendungen ausreichen. Für Anwendungen, die besonders große oder zahlreiche Einfüge- und Löschoperationen in Verbindung mit großen Transaktionen und umfangreichen Primärschlüsseln vornehmen, kann es erforderlich sein, diesen Puffer zu vergrößern. Wenn er zu klein ist, meldet die Speicher-Engine NDB den internen Fehlercode 677 (
Index UNDO buffers overloaded).UndoDataBufferDieser Parameter stellt die Größe des UNDO-Datenpuffers ein, der ähnlich wie der UNDO-Indexpuffer funktioniert, aber für das Data Memory statt des Index Memorys verwendet wird. Dieser Puffer wird in der lokalen Checkpoint-Phase eines Fragments für Einfüge-, Lösch- und Änderungsoperationen benötigt.
Da UNDO-Logeinträge immer größer werden, je mehr Operationen protokolliert werden, ist auch dieser Puffer größer als sein Gegenstück für das Index Memory, nämlich nach Voreinstellung 16 Mbyte.
Dieser Speicher kann für manche Anwendungen unnötig groß sein. In solchen Fällen können Sie den Wert bis auf das Minimum von 1 Mbyte heruntersetzen.
Es ist nur selten erforderlich, diesen Puffer zu vergrößern. Wenn es dennoch einmal getan werden muss, so sollten Sie vorher prüfen, ob Ihre Festplatten die Last der Updates in der Datenbank überhaupt bewältigen können. Wenn nicht genügend Platz auf der Festplatte vorhanden ist, können Sie dies auch durch das Vergrößern dieses Puffers nicht ändern.
Wenn dieser Puffer zu klein ist und verstopft, meldet die Speicher-Engine NDB den internen Fehlercode 891 (Data UNDO buffers overloaded).
RedoBufferAuch alle Update-Aktivitäten müssen protokolliert werden. Das REDO-Log ermöglicht es, die Updates bei einem späteren Neustart des Systems erneut laufen zu lassen. Der Recovery-Algorithmus von NDB verwendet einen „Fuzzy“-Checkpoint der Daten in Verbindung mit dem UNDO-Log und wendet dann das REDO-Log an, um alle Änderungen bis zum Wiederherstellungspunkt erneut aufzuspielen.
RedoBufferstellt die Größe des Puffers ein, in den das REDO-Log geschrieben wird, und hat den Standardwert 8 Mbyte. Sein Mindestwert beträgt 1 Mbyte.Ist dieser Puffer zu klein, meldet die Speicher-Engine NDB den Fehlercode 1221 (
REDO log buffers overloaded).
Für das Cluster-Management ist es sehr wichtig, die Anzahl
der Logmeldungen steuern zu können, die für verschiedene
Ereignistypen an stdout gesandt werden.
Für jede Art von Ereignis gibt es 16 mögliche Berichtsebenen
(mit den Nummern 0 bis 15). Wird die Berichtsebene für eine
gegebene Ereigniskategorie auf 15 gesetzt, so bedeutet dies,
dass alle Ereignisberichte dieser Kategorie an
stdout geschickt werden; wird es auf 0
gesetzt, so werden in dieser Kategorie keine Ereignisse
gemeldet.
Nach Voreinstellung wird nur die Startnachricht an
stdout geschickt, während die übrigen
Ereignisberichtsebenen auf 0 gesetzt sind. Der Grund: Diese
Meldungen werden auch an das Cluster-Log des
Management-Servers geschickt.
Dieselben Ebenen können Sie auch für den Management-Client einstellen, um festzulegen, welche Ereignisebenen im Cluster-Log protokolliert werden.
LogLevelStartupDie Berichtsebene für Ereignisse, die beim Starten des Prozesses eintreten.
Die Standardebene ist 1.
LogLevelShutdownDie Berichtsebene für Ereignisse, die beim sanften Herunterfahren eines Knotens gemeldet werden.
Die Standardebene ist 0.
LogLevelStatisticDie Berichtsebene für statistische Ereignisse wie beispielsweise die Anzahl der Lesevorgänge auf Primärschlüsseln, die Anzahl der Änderungen oder Einfügungen, Informationen über die Pufferausnutzung und so weiter.
Die Standardebene ist 0.
LogLevelCheckpointDie Berichtsebene für Ereignisse, die bei lokalen und globalen Checkpoints generiert werden.
Die Standardebene ist 0.
LogLevelNodeRestartDie Berichtsebene für Ereignisse, die beim Neustart eines Knotens generiert werden.
Die Standardebene ist 0.
LogLevelConnectionDie Berichtsebene für Ereignisse, die von Verbindungen zwischen Cluster-Knoten generiert werden.
Die Standardebene ist 0.
LogLevelErrorDie Berichtsebene für Ereignisse, die von Fehlern und Warnungen vom Cluster insgesamt generiert werden. Diese Fehler bringen zwar nicht gleich einen Knoten zum Absturz, sind es aber dennoch wert, gemeldet zu werden.
Die Standardebene ist 0.
LogLevelInfoDie Berichtsebene für Ereignisse, die zur Information über den Allgemeinzustand des Clusters generiert werden.
Die Standardebene ist 0.
Sicherungsparameter
In diesem Abschnitt geht es um
[NDBD]-Parameter zur Definition von
Speicherpuffern für die Ausführung von Online-Sicherungen.
BackupDataBufferSizeBei der Erstellung einer Datensicherung werden zwei Puffer verwendet, um die Daten auf die Festplatte zu schreiben: Der Puffer für Sicherungsdaten (Backup Data-Puffer) nimmt Daten auf, die beim Scannen der Tabellen eines Knotens aufgezeichnet wurden. Wenn dieser Puffer bis zu dem in
BackupWriteSize(siehe unten) angegebenen Stand gefüllt ist, werden die Seiten auf die Festplatte geschrieben. Während Daten auf die Platte zurückgeschrieben werden, kann der Datensicherungsprozess weiter diesen Puffer mit Daten füllen, bis ihm der Platz ausgeht. Wenn dies geschieht, macht der Sicherungsprozess eine Pause mit seinen Scans, bis einige Schreibvorgänge auf der Platte so weit abgeschlossen sind, dass Speicher freigegeben wurde und das Scannen fortgesetzt werden kann.Der Standardwert ist 2 Mbyte.
BackupLogBufferSizeDer Backup Log-Puffer spielt eine ähnliche Rolle wie der Backup Data-Puffer, wird jedoch verwendet, um ein Log aller während einer Datensicherung ausgeführten Schreibvorgänge auf Tabellen zu generieren. Diese Seiten werden nach demselben Prinzip wie bei der Datensicherung „Datenpuffer“ geschrieben, nur dass hier die Sicherung scheitert, wenn der Platz im Backup Log-Puffer ausgeht. Aus diesem Grund muss der Backup Log-Puffer unbedingt groß genug sein, um die von Schreibaktivitäten während der Datensicherung verursachte Belastung aushalten zu können. Siehe auch Abschnitt 16.6.5.4, „Konfiguration für Cluster-Backup“.
Der Standardwert dieses Parameters müsste für die meisten Anwendungen ausreichen. Eine Sicherung scheitert eher schon einmal durch zu langsame Schreibvorgänge auf der Platte als durch einen vollen Backup Log-Puffer. Wenn das Festplatten-Teilsystem für die Last der von Anwendungen verursachten Schreibvorgänge unzureichend konfiguriert ist, kann auch der Cluster die gewünschten Operationen nicht ausführen.
Cluster-Knoten sollten so konfiguriert werden, dass der Engpass eher im Prozessor liegt als in den Festplatten oder Netzwerkverbindungen.
Der Standardwert ist 2 Mbyte.
BackupMemoryDieser Parameter ist einfach die Summe von
BackupDataBufferSizeundBackupLogBufferSize.Der Standardwert ist 2 Mbyte + 2 Mbyte = 4 Mbyte.
BackupWriteSizeDieser Parameter spezifiziert die Größe der Meldungen, die von den Backup Log- und Backup Data-Puffern auf die Festplatte geschrieben werden.
Der Standardwert ist 32 Kbyte.
Die [MYSQLD]-Abschnitte in der
config.ini-Datei definieren das Verhalten
der MySQL Server (SQL-Knoten), die für den Zugriff auf
Cluster-Daten eingesetzt werden. Keiner dieser Parameter ist
obligatorisch. Wenn kein Computer- oder Hostname angegeben
ist, kann jeder Host diesen SQL-Knoten benutzen.
IdDer Wert
Idwird verwendet, um den Knoten in allen Cluster-internen Nachrichten zu identifizieren. Es ist ein Integer zwischen 1 und 63 einschließlich, der unter allen Knoten-IDs im Cluster einzigartig sein muss.ExecuteOnComputerBezieht sich auf einen der Computer (Hosts), die in einem
[COMPUTER]-Abschnitt der Konfigurationsdatei genannt sind.ArbitrationRankDieser Parameter gibt an, welche Knoten als Arbitrator fungieren können. Sowohl MGM- als auch SQL-Knoten können Arbitrator sein. Der Wert 0 bedeutet, dass der betreffende Knoten nie Arbitrator sein kann, 1 gibt ihm die höchste Priorität als Arbitrator und 2 verleiht ihm eine niedrige Priorität. In einer normalen Konfiguration wird der Management-Server als Arbitrator eingesetzt, indem sein
ArbitrationRankauf 1 (den Default) und die der SQL-Knoten auf 0 gesetzt werden.ArbitrationDelayWird dieser Parameter auf irgendeinen anderen Wert als 0 (den Standardwert) gesetzt, so werden die Antworten des Arbitrators auf Arbitration-Requests um diese Anzahl Millisekunden verzögert. Normalerweise ist es nicht nötig, diesen Wert zu ändern.
BatchByteSizeFür Anfragen, die in vollständige Tabellenscans oder Indexbereichsscans übersetzt werden, ist es aus Performancegründen wichtig, die Datensätze in Stapeln (Batches) der richtigen Größe abzuholen. Diese richtige Größe kann man sowohl als eine Anzahl von Datensätzen (
BatchSize) als auch in Bytes (BatchByteSize) einstellen. Die tatsächliche Batch-Größe wird von beiden Parametern eingeschränkt.Je nachdem, wie dieser Parameter eingestellt ist, kann die Geschwindigkeit von Anfragen um 40 Prozent variieren. In künftigen Releases wird MySQL Server anhand des Anfragetyps fundierte Annahmen über die Batch-Größe treffen.
Dieser Parameter wird in Bytes angegeben und hat den Standardwert 32 Kbyte.
BatchSizeDieser Parameter wird als Anzahl von Datensätzen angegeben und ist standardmäßig auf 64 eingestellt. Seine Maximalgröße beträgt 992.
MaxScanBatchSizeDie Batch-Größe ist die Größe jedes Batchs von jedem Datenknoten. Die meisten Scans werden parallel ausgeführt, damit der MySQL Server nicht von vielen Knoten parallel zu viele Daten übermittelt bekommt. Dieser Parameter setzt eine Obergrenze der gesamten Batch-Größe quer über alle Knoten.
Standardmäßig ist dieser Parameter auf 256 Kbyte eingestellt; seine Maximalgröße beträgt 16 Mbyte.
TCP/IP ist der Standardtransportmechanismus zur Einrichtung
von Verbindungen in MySQL Cluster. Normalerweise ist es nicht
nötig, Verbindungen zu definieren, da Cluster automatisch
zwischen allen Datenknoten untereinander, zwischen allen
Datenknoten und allen MySQL Server-Knoten sowie zwischen allen
Datenknoten und dem Management-Server Verbindungen einrichtet.
(Die einzige Ausnahme von dieser Regel wird unter
Abschnitt 16.4.4.8, „MySQL Cluster: TCP/IP-Verbindungen mittels direkter Verbindungen“,
beschrieben.) [TCP]-Abschnitte in der
config.ini-Datei definieren explizit
TCP/IP-Verbindungen zwischen Knoten im Cluster.
Es ist nur dann notwendig, eine Verbindung zu definieren, wenn
die Standardverbindungsparameter außer Kraft gesetzt werden
sollen. In diesem Fall müssen mindestens
NodeId1, NodeId2 und die
zu ändernden Parameter angegeben werden.
Die Standardwerte dieser Parameter können Sie auch ändern,
indem Sie sie im [TCP DEFAULT]-Abschnitt
setzen.
NodeId1,NodeId2Um eine Verbindung zwischen zwei Knoten zu identifizieren, müssen ihre Knoten-IDs im
[TCP]-Abschnitt der Konfigurationsdatei angegeben werden. Dabei handelt es sich um dieselben eindeutigenId-Werte für einzelne Knoten, wie in Abschnitt 16.4.4.6, „Festlegung von SQL-Nodes in einem MySQL Cluster“, beschrieben.SendBufferMemoryTCP-Transporter speichern alle Nachrichten in einem Puffer, ehe sie den Sendeaufruf an das Betriebssystem starten. Wenn dieser Puffer 64 Kbyte erreicht, wird sein Inhalt übersandt; das Gleiche geschieht, wenn eine Runde Nachrichten ausgeführt worden ist. Um mit vorübergehenden Überlastungen umgehen zu können, ist es auch möglich, einen größeren Send-Puffer zu definieren. Seine Standardgröße beträgt 256 Kbyte.
SendSignalIdUm ein Diagramm mit verteilten Nachrichen nachvollziehen zu können, muss jede Nachricht genau identifiziert sein. Wenn dieser Parameter
Yist, werden die Message-IDs über das Netzwerk transportiert. In der Standardeinstellung ist dieses Feature ausgeschaltet.ChecksumDieser boolesche Parameter ist standardmäßig deaktiviert. (Um ihn zu aktivieren, setzen Sie ihn auf
Yoder1, um ihn zu deaktivieren, aufNoder0.) Wird er aktiviert, so werden für alle Nachrichten, ehe sie in den Send-Puffer geladen werden, Prüfsummen berechnet. Dadurch wird gewährleistet, dass die Nachrichten nicht durch den Transportmechanismus oder beim Warten im Send-Puffer geschädigt werden.PortNumber(OBSOLET)Dieser Parameter gab früher einmal die Nummer des Ports an, auf dem das System nach Verbindungen anderer Knoten lauschte. Der Parameter sollte nicht mehr benutzt werden.
ReceiveBufferMemoryGibt die Größe des Puffers zum Empfangen von Daten von dem TCP/IP-Socket an. Es ist kaum jemals erforderlich, den Standardwert von 64 Kbyte zu ändern, es sei denn, um Speicher zu sparen.
Um einen Cluster mit Direktverbindungen zwischen den
Datenknoten einzurichten, müssen Sie explizit die
Crossover-IP-Adressen der Datenknoten angeben, die so im
[TCP]-Abschnitt der
config.ini-Datei des Clusters verbunden
werden.
Im folgenden Beispiel planen wir einen Cluster mit mindestens
vier Hosts, nämlich einem Management-Server, einem SQL-Knoten
und zwei Datenknoten. Der Cluster als Ganzes residiert im
Subnetz 172.23.72.* eines LANs. Zusätzlich
zu den normalen Netzwerkverbindungen existiert eine
Direktverbindung zwischen den beiden Datenknoten über ein
standardmäßiges Crossover-Kabel. Die beiden können direkt
über IP-Adressen im Adressbereich 1.1.0.*
miteinander kommunizieren:
# Management-Server [NDB_MGMD] Id=1 HostName=172.23.72.20 # SQL-Knoten [MYSQLD] Id=2 HostName=172.23.72.21 # Datenknoten [NDBD] Id=3 HostName=172.23.72.22 [NDBD] Id=4 HostName=172.23.72.23 # TCP/IP-Verbindungen [TCP] NodeId1=3 NodeId2=4 HostName1=1.1.0.1 HostName2=1.1.0.2
Direktverbindungen zwischen Datenknoten können die Gesamtleistung des Clusters steigern, da die Datenknoten auf diese Weise ein Ethernet-Gerät wie etwa einen Switch, Hub oder Router umgehen können, was die Latenzzeit im Cluster reduziert. Wichtig: Um von solchen Direktverbindungen zwischen mehr als zwei Datenknoten maximal zu profitieren, benötigen Sie eine Direktverbindung jedes Datenknotens mit jedem anderen Datenknoten derselben Knotengruppe.
MySQL Cluster versucht, den Shared Memory Transporter zu
nutzen und wenn möglich automatisch zu konfigurieren, vor
allem, wenn mehrere Knoten gleichzeitig auf demselben
CLuster-Host laufen. (In sehr frühen Versionen von MySQL
Cluster funktionierten Shared Memory-Segmente nur, wenn die
-max-Binärversion mit der Option
--with-ndb-shm gebaut wurde.) In den
[SHM]-Abschnitten der
config.ini-Datei werden Shared
Memory-Verbindungen zwischen Knoten im Cluster explizit
definiert. Wenn explizit Shared Memory als Verbindungsmethode
konfiguriert ist, müssen mindestens auch
NodeId1, NodeId2 und
ShmKey definiert sein. Alle anderen
Parameter müssten mit ihren Standardeinstellungen im
Normalfall gut funktionieren.
Wichtig: Die Funktionalität von SHM befindet sich noch im Experimentierstadium. Sie wird offiziell von keinem MySQL-Release bis einschließlich 5.1 unterstützt. Sie müssen also entweder nach eigenem Ermessen oder anhand von Informationen aus unseren kostenlosen Ressourcen (Foren, Mailinglisten) entscheiden, ob dieses Feature in Ihrem speziellen Fall richtig ans Laufen gebracht werden kann.
NodeId1,NodeId2Um eine Verbindung zwischen zwei Knoten identifizieren zu können, müssen Sie für jeden von ihnen einen Knotenbezeichner verwenden, etwa
NodeId1undNodeId2.ShmKeyBei der Einrichtung von Shared Memory-Segmenten wird das für die Kommunikation zu verwendende Segment durch eine Knoten-ID (einen Integer) eindeutig identifiziert. Einen Standardwert gibt es nicht.
ShmSizeJede SHM-Verbindung hat ein Shared Memory-Segment, in welchem die Nachrichten zwischen den Knoten vom Absender gespeichert und vom Empfänger gelesen werden. Die Größe dieses Segments wird durch
ShmSizefestgelegt und beträgt nach Voreinstellung 1 Mbyte.SendSignalIdUm den Pfad einer verteilten Nachricht zurückverfolgen zu können, benötigt jede Nachricht einen eindeutigen Bezeichner. Wird dieser Parameter auf
Ygesetzt, werden auch Message-IDs über das Netzwerk transportiert. Nach Voreinstellung ist dieses Feature deaktiviert.ChecksumDieser boolesche Parameter ist standardmäßig ausgeschaltet (er kann
YoderNsein). Wird er eingeschaltet, werden für alle Nachrichten Prüfsummen berechnet, ehe sie in den Puffer gelegt werden.Dieses Feature verhindert, dass Nachrichten beschädigt werden, während sie im Puffer warten. Außerdem wirkt es als Versicherung gegen Datenkorruption auf dem Transportweg.
In [SCI]-Abschnitten der
config.ini-Datei werden explizit SCI
(Scalable Coherent Interface)-Verbindungen zwischen
Cluster-Knoten definiert. Die Verwendung von SCI Transportern
in MySQL Cluster wird nur dann unterstützt, wenn die
MySQL-Max-Binaries mit der Option
--with-ndb-sci=
gebaut wurden. Der /your/path/to/SCIpath sollte auf
ein Verzeichnis verweisen, das zumindest
lib- und
include-Verzeichnisse mit
SISCI-Bibliotheken und Header-Dateien enthält. (Mehr zum
Thema SCI finden Sie unter
Abschnitt 16.7, „Verwendung von Hochgeschwindigkeits-Interconnects mit MySQL Cluster“.)
Darüber hinaus erfordert SCI spezielle Hardware.
Wir raten Ihnen dringend, SCI Transporter nur für die Kommunikation zwischen ndbd-Prozessen zu verwenden. Beachten Sie bitte auch, dass SCI Transporter dazu führen, dass die ndbd-Prozesse niemals schlafen. Aus diesem Grund sollten SCI Transporter nur auf Computern eingesetzt werden, die mindestens zwei CPUs ausschließlich für ndbd-Prozesse reserviert haben. Es muss mindestens eine CPU pro ndbd-Prozess vorhanden sein, und mindestens eine CPU muss für die Betriebssystemaktivitäten übrig bleiben.
NodeId1,NodeId2Um eine Verbindung zwischen zwei Knoten genau identifizieren zu können, müssen beide Knoten einen Bezeichner haben, etwa
NodeId1undNodeId2.Host1SciId0Die SCI-Knoten-ID für den ersten Cluster-Knoten (den mit der Bezeichnung
NodeId1).Host1SciId1Man kann SCI Transporter zur Ausfallsicherung zwischen zwei SCI-Karten einsetzen, die dann allerdings separate Netzwerke zwischen den Knoten verwenden sollten. Dieser Parameter definiert die Knoten-ID und die zweite SCI-Karte für den ersten Knoten.
Host2SciId0Dieser Parameter identifiziert die SCI-Knoten-ID für den zweiten Cluster-Knoten (den mit der Bezeichnung
NodeId2).Host2SciId1Wenn zur Ausfallsicherung zwei SCI-Karten eingesetzt werden, identifiziert dieser Parameter die zweite SCI-Karte für den zweiten Knoten.
SharedBufferSizeJeder SCI Transporter hat ein Shared Memory-Segment für die Kommunikation zwischen den Knoten. Für die meisten Anwendungen müsste es ausreichen, die Größe dieses Segments auf dem Standardwert 1 Mbyte zu belassen. Ein kleinerer Wert kann bei vielen parallelen Einfügeoperationen Probleme verursachen; wenn der Shared Buffer zu klein ist, kann überdies der gesamte ndbd-Prozess abstürzen.
SendLimitEin kleiner Puffer vor den SCI-Medien speichert Nachrichten, ehe sie über das SCI-Netzwerk verschickt werden. Nach Voreinstellung ist er 8 Kbyte groß. Unsere Benchmarks weisen zwar die beste Performance bei 64 Kbyte aus, aber 16 Kbyte kommen schon bis auf wenige Prozente an diesen Höchstwert heran, und es gibt wenig Anlass, über den Wert von 8 Kbyte hinauszugehen.
SendSignalIdUm eine verteilte Nachricht zurückverfolgen zu können, benötigt jede Nachricht einen eindeutigen Bezeichner. Wird dieser Parameter auf
Ygesetzt, werden auch Message-IDs über das Netzwerk transportiert. Nach Voreinstellung ist dieses Feature deaktiviert.ChecksumDieser boolesche Parameter ist standardmäßig deaktiviert. Wird
Checksumaktiviert, so werden für alle Nachrichten, ehe sie in den Send-Puffer geladen werden, Prüfsummen berechnet. Dadurch wird gewährleistet, dass die Nachrichten nicht durch den Transportmechanismus oder beim Warten im Send-Puffer geschädigt werden.
Um die Verwaltung von MySQL Cluster zu verstehen, müssen Sie vier wichtige Prozesse kennen: In den folgenden Abschnitten dieses Kapitels werden wir feststellen, welche Rollen diese Prozesse in einem Cluster spielen, wie sie benutzt werden und welche Startoptionen für sie zur Verfügung stehen:
mysqld ist der traditionelle MySQL
Server-Prozess. Um ihn mit MySQL Cluster zu verwenden, muss
mysqld mit Unterstützung für die
Speicher-Engine NDB Cluster gebaut werden,
wie sie in den -max-Binaries von
http://dev.mysql.com/downloads/ bereits vorkompiliert ist.
Wenn Sie MySQL von der Quellversion bauen, müssen Sie
configure mit der Option
--with-ndbcluster aufrufen, um NDB
Cluster-Unterstützung zu erhalten.
Wenn die mysqld-Binary mit
Cluster-Unterstützung erstellt wurde, ist die Speicher-Engine
NDB Cluster nach Voreinstellung immer noch
ausgeschaltet. Um sie zu aktivieren, haben Sie zwei
Möglichkeiten:
Sie können
--ndbclusterals Startoption auf der Kommandozeile setzen, wenn Sie mysqld starten.Sie können in den Abschnitt
[mysqld]Ihrermy.cnf-Datei eine Zeile mit dem Eintragndbclustereinsetzen.
Eine einfache Möglichkeit, zu überprüfen, ob Ihr Server mit
der Speicher-Engine NDB Cluster läuft,
besteht darin, im MySQL Monitor (mysql) die
SHOW ENGINES-Anweisung zu geben. Dann müsste
der Wert YES als
Support-Wert in der Zeile für
NDBCLUSTER stehen. Steht dort ein
NO oder ist diese Zeile in der Ausgabe gar
nicht vorhanden, so ist Ihre laufende MySQL-Version nicht
NDB-fähig. Wenn in dieser Zeile der Wert
DISABLED steht, müssen Sie die
NDB-Unterstützung in einer der beiden oben
beschriebenen Weisen aktivieren.
Um Cluster-Konfigurationsdaten lesen zu können, benötigt der MySQL Server mindestens drei Informationen:
die eigene Cluster-Knoten-ID des MySQL Servers
den Hostnamen oder die IP-Adresse für den Management-Server (MGM-Knoten)
die Nummer des TCP/IP-Ports, auf dem er sich mit dem Management-Server verbinden kann
Da Knoten-IDs dynamisch zugewiesen werden können, müssen sie nicht unbedingt explizit angegeben werden.
Der mysqld-Parameter
ndb-connectstring gibt den Verbindungs-String
an, entweder auf der Kommandozeile beim Starten von
mysqld oder in der Datei
my.cnf. Der Verbindungs-String enthält den
Hostnamen oder die IP-Adresse, unter der der Management-Server
zu erreichen ist, sowie den verwendeten TCP/IP-Port.
Im folgenden Beispiel ist ndb_mgmd.mysql.com
der Management-Server-Host und 1186 der Port, auf dem dieser auf
Cluster-Nachrichten lauscht:
shell> mysqld --ndb-connectstring=ndb_mgmd.mysql.com:1186
Mehr über Verbindungs-Strings erfahren Sie unter
Abschnitt 16.4.4.2, „MySQL Cluster: connectstring“.
Mit diesen Informationen wird der MySQL Server zum vollwertigen Mitglied des Clusters. (Manchmal bezeichnen wir einen mysqld-Prozess, der auf diese Weise ausgeführt wird, auch als SQL-Knoten.) Er kennt dann alle Cluster-Datenknoten und ihren Status und wird Verbindungen zu ihnen einrichten. In diesem Fall ist er in der Lage, jeden Datenknoten als Transaktionskoordinator zu benutzen und Knotendaten zu lesen und zu ändern.
ndbd ist der Prozess, der alle Tabellendaten behandelt, die mit der Speicher-Engine NDB Cluster gespeichert sind. Dieser Prozess kann einen Speicherknoten auch in die Lage versetzen, verteilte Transaktionen, Knoten-Recovery, Checkpointing auf der Festplatte, Online-Sicherung und ähnliche Aufgaben zu erfüllen.
In einem MySQL Cluster kümmern sich mehrere ndbd-Prozesse gemeinsam um die Behandlung der Daten. Diese Prozesse können auf demselben Computer/Host oder auf verschiedenen Computern ausgeführt werden. Die Beziehungen zwischen Datenknoten und Cluster-Hosts ist komplett konfigurierbar.
ndbd generiert einige Logdateien, die in
einem im DataDir-Abschnitt der
Konfigurationsdatei config.ini genannten
Verzeichnis abgelegt werden. Diese Logdateien sind unten
aufgeführt. Beachten Sie, dass
node_id der eindeutige Bezeichner des
Knotens ist. So ist beispielsweise
ndb_2_error.log das Fehlerlog, das der
Speicherknoten mit der Knoten-ID 2 generiert.
ndb_ist eine Datei mit Aufzeichnungen aller Crashes, die dem angegebenen ndbd-Prozess begegnet sind. Jeder Datensatz in dieser Datei enthält einen kurzen Fehler-String und eine Referenz auf eine Trace-Datei für den betreffenden Crash. Ein typischer Eintrag könnte folgendermaßen aussehen:node_id_error.logDate/Time: Saturday 30 July 2004 - 00:20:01 Type of error: error Message: Internal program error (failed ndbrequire) Fault ID: 2341 Problem data: DbtupFixAlloc.cpp Object of reference: DBTUP (Line: 173) ProgramName: NDB Kernel ProcessID: 14909 TraceFile: ndb_2_trace.log.2 ***EOM***
Hinweis: Sie müssen immer daran denken, dass der letzte Eintrag in der Fehlerlogdatei nicht unbedingt der neueste ist (das wäre sogar höchst unwahrscheinlich). Eintragungen im Fehlerlog sind nicht chronologisch, sondern spiegeln die Reihenfolge der Trace-Dateien wider, wie sie in der Datei
ndb_(siehe unten) festgelegt ist. Daher werden Fehlerlogeinträge zyklisch und nicht sequenziell überschrieben.node_id_trace.log.nextndb_ist eine Trace-Datei, die genau beschreibt, was unmittelbar vor Eintreten des Fehlers geschah. Diese Information ist nützlich für die Analysen des MySQL Cluster-Entwicklungsteams.node_id_trace.log.trace_idSie können konfigurieren, wie viele von diesen Trace-Dateien erzeugt werden, ehe die alten überschrieben werden.
trace_idist eine Zahl, die mit jeder sukzessiven Trace-Datei um eins erhöht wird.Die Datei
ndb_behält im Auge, welche Trace-Datei-Nummer als Nächste zugewiesen wird.node_id_trace.log.nextDie Datei
ndb_enthält die Datenausgabe des ndbd-Prozesses. Diese Datei wird nur angelegt, wenn ndbd als Daemon gestartet wird.node_id_out.logDie Datei
ndb_enthält die Prozess-ID des ndbd-Prozesses, wenn dieser als Daemon gestartet wird. Sie fungiert auch als Sperrdatei, damit keine Knoten mit demselben Bezeichner gestartet werden.node_id.pidDie Datei
ndb_ist nur in Debugversionen von ndbd vorhanden, wo es möglich ist, alle ein- und ausgehenden sowie internen Nachrichten mit ihren Daten im ndbd-Prozess nachzuvollziehen.node_id_signal.log
Bitte verwenden Sie kein mit NFS gemountetes Verzeichnis, da
dies in manchen Umgebungen Probleme verursachen kann, wobei die
Sperre auf der .pid-Datei auch nach dem
Ende des Prozesses in Kraft bleibt.
Um ndbd starten zu können, ist es unter Umständen notwendig, den Hostnamen des Management-Servers und den Port anzugeben, auf dem er lauscht. Optional können Sie auch die ID des Knotens angeben, den der Prozess benutzen soll.
shell> ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"
Mehr zu diesem Thema finden Sie unter
Abschnitt 16.4.4.2, „MySQL Cluster: connectstring“.
Abschnitt 16.5.5, „Befehlsoptionen für MySQL Cluster-Prozesse“, beschreibt
weitere Optionen für ndbd.
Wenn der ndbd-Prozess startet, werden in Wirklichkeit zwei Prozesse initiiert: Der erste heißt „Engelprozess“ und hat nur die Aufgabe, zu entdecken, wenn die Ausführung des Prozesses beendet ist, und dann den ndbd-Prozess neu zu starten, wenn er so konfiguriert ist. Wenn Sie also versuchen, ndbd mit dem Unix-Befehl kill anzuhalten, müssen Sie beide Prozesse anhalten, und zwar den Engelprozess als ersten. Einen ndbd-Prozess stoppen Sie am besten, indem Sie den Management-Client benutzen, um den Prozess von dort aus anzuhalten.
Der Ausführungsprozess verwendet nur einen einzigen Thread für das Lesen, Schreiben und Scannen der Daten sowie alle anderen Aktivitäten. Dieser Thread ist asynchron implementiert, damit er Tausende von nebenläufigen Aktivitäten leicht bewältigen kann. Zusätzlich überwacht ein Wachhund-Thread diesen Ausführungs-Thread, um sicherzustellen, dass dieser nicht in einer Endlosschleife stecken bleibt. Ein Pool von Threads kümmert sich um die Dateiein- und -ausgaben, wobei jeder Thread für eine geöffnete Datei zuständig ist. Auch die Transporter im ndbd-Prozess können für ihre Transporterverbindungen Threads nutzen. In einem System, das viele Operationen - darunter auch Updates - ausführt, kann der ndbd-Prozess bis zu 2 CPUs mit Beschlag belegen, wenn ihm dies erlaubt ist. Auf einem Mehrprozessorcomputer ist es empfehlenswert, mehrere ndbd-Prozesse für die verschiedenen Knotengruppen zu verwenden.
Der Management-Server ist der Prozess, der die Cluster-Konfigurationsdatei liest und diese Informationen auf alle Knoten im Cluster verteilt, die nach ihnen fragen. Außerdem pflegt er ein Log der Cluster-Aktivitäten. Management-Clients können sich mit dem Management-Server verbinden und den Status des Clusters überprüfen.
Es ist nicht unbedingt erforderlich, beim Start des Management-Servers einen Verbindungs-String anzugeben. Wenn Sie allerdings mehrere Management-Server einsetzen, ist ein solcher String notwendig und jeder Knoten im Cluster muss explizit seine Knoten-ID angeben.
Weitere Informationen über die Verwendung von
Verbindungs-Strings finden Sie unter
Abschnitt 16.4.4.2, „MySQL Cluster: connectstring“.
Abschnitt 16.5.5, „Befehlsoptionen für MySQL Cluster-Prozesse“, beschreibt
andere Optionen für ndb_mgmd.
Die folgenden Dateien werden von ndb_mgmd in
seinem Startverzeichnis angelegt oder benutzt, und sie werden
gemäß den Angaben in der Konfigurationsdatei
config.ini in das
DataDir übernommen. In der nachfolgenden
Liste ist node_id der eindeutige
Knotenbezeichner.
config.iniist die Konfigurationsdatei für den Cluster insgesamt. Diese Datei wird vom Benutzer angelegt und vom Management-Server gelesen. In Abschnitt 16.4, „MySQL Cluster: Konfiguration“, ist die Einrichtung dieser Datei beschrieben.Das Ereignislog des Clusters ist
ndb_. Dort werden Ereignisse festgehalten, die beispielsweise beim Starten und Beenden von Checkpoints, beim Starten von Knoten oder beim Absturz eines Knotens auftreten, und es wird das Ausmaß der Arbeitsspeichernutzung protokolliert. Eine vollständige Liste der Cluster-Ereignisse samt Beschreibungen finden Sie unter Abschnitt 16.6, „Management von MySQL Cluster“.node_id_cluster.logWenn das Cluster-Log auf eine Million Byte angewachsen ist, wird die Datei in
ndb_umbenannt, wobeinode_id_cluster.log.seq_idseq_iddie laufende Nummer der Cluster-Logdatei ist. (Ein Beispiel: Sind bereits Dateien mit den laufenden Nummern 1, 2 und 3 vorhanden, bekommt die nächste Logdatei die Nummer4.)Die Datei
ndb_wird fürnode_id_out.logstdoutundstderrgenutzt, wenn der Management-Server als Daemon läuft.ndb_ist die Prozess-ID-Datei, wenn der Management-Server als Daemon läuft.node_id.pid
Der Management-Client-Prozess ist eigentlich nicht erforderlich, um den Cluster zu betreiben. Sein Wert liegt in der Bereitstellung von Befehlen zur Überprüfung des Cluster-Status, zum Starten von Datensicherungen und zur Ausführung anderer administrativer Funktionen. Der Management-Client greift über eine C-API auf den Management-Server zu. Fortgeschrittene Benutzer können über diese API auch dedizierte Management-Prozesse programmieren, die sich um ähnliche Aufgaben kümmern wie ndb_mgm.
Um den Management-Client zu starten, müssen Sie den Hostnamen und die Portnummer des Management-Servers angeben:
shell> ndb_mgm [host_name [port_num]]
Ein Beispiel:
shell> ndb_mgm ndb_mgmd.mysql.com 1186
Der Standardhostname ist localhost und der
Standardport ist 1186.
Mehr über die Verwendung von ndb_mgm lesen Sie unter Abschnitt 16.5.5.4, „Befehlsoptionen für ndb_mgm“, und Abschnitt 16.6.2, „Befehle des Management-Clients“.
Alle MySQL Cluster-Executables (außer
mysqld) nehmen die in diesem Abschnitt
aufgeführten Optionen entgegen. Benutzer älterer Versionen von
MySQL Cluster sollten berücksichtigen, dass einige dieser
Optionen gegenüber MySQL 4.1 Cluster geändert wurden, um sie
miteinander und mit mysqld zu
vereinheitlichen. Die Option --help zeigt Ihnen
die Liste der unterstützten Optionen an.
Die folgenden Abschnitte beschreiben Optionen, die für einzelne NDB-Programme spezifisch sind.
--help--usage,-?Gibt eine kurze Liste mit Beschreibungen der verfügbaren Befehlsoptionen aus.
--connect-string=,connect_string-cconnect_stringconnect_stringstellt den Verbindungs-String für den Management-Server als Befehlsoption ein.shell>
ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"--debug[=options]Diese Option kann nur für Versionen verwendet werden, die mit Debugging kompiliert wurden. Sie aktiviert die Ausgabe von Debugaufrufen in derselben Weise wie für den mysqld-Prozess.
--execute=command-ecommandKann einen Befehl von der System-Shell an die Cluster-Executable schicken. Die beiden folgenden Befehle:
shell>
ndb_mgm -e showoder
shell>
ndb_mgm --execute="SHOW"sind äquivalent zu
NDB> SHOW;
Analog funktionieren die Optionen
--executeund-emit dem Kommandozeilen-Client von mysql. Siehe auch Abschnitt 4.3.1, „Befehlszeilenoptionen für mysqld“.--version,-VGibt die Versionsnummer des ndbd-Prozesses aus. Dabei handelt es sich um die Nummer der MySQL Cluster-Version. Diese ist wichtig, da nicht alle Versionen zusammen benutzt werden können. Der MySQL Cluster-Prozess prüft beim Hochfahren, ob die Versionen der verwendeten Binaries überhaupt in demselben Cluster nebeneinander existieren können. Das ist auch beim Online-Softwareupgrade von MySQL Cluster von Bedeutung.
--ndb-connectstring=connect_stringWenn die Speicher-Engine
NDB Clusterbenutzt wird, gibt diese Option an, welcher Management-Server die Daten für die Cluster-Konfiguration verteilt.--ndbclusterDie Speicher-Engine
NDB Clusterist für die Benutzung von MySQL Cluster erforderlich. Wenn eine mysqld-Binary die Speicher-EngineNDB Clusterunterstützt, ist diese Engine nach Voreinstellung deaktiviert. Mit der Option--ndbclusterwird sie aktiviert und mit--skip-ndbclusterexplizit deaktiviert.
Optionen für alle NDB-Programme finden Sie unter Abschnitt 16.5.5, „Befehlsoptionen für MySQL Cluster-Prozesse“.
--daemon,-dLässt ndbd als Daemon-Prozess laufen. Dies ist das Standardverhalten. Die Option
--nodaemonkann verwendet werden, wenn der Prozess nicht als Daemon laufen soll.--initialLässt ndbd einen Initialstart durchführen. Beim Initialstart werden alle Dateien gelöscht, die von früheren ndbd-Instanzen zu Wiederherstellungszwecken angelegt wurden. Außerdem rekonstruiert diese Option die Recovery-Logdateien. Beachten Sie, dass dieser Prozess auf manchen Betriebssystemen viel Zeit braucht.
Ein
--initial-Start soll nur beim allerersten Hochfahren des ndbd-Prozesses ausgeführt werden, da er alle Dateien aus dem Cluster-Dateisystem löscht und alle Recovery-Logdateien wiederherstellt. Von dieser Regel gibt es zwei Ausnahmen:Ein Softwareupgrade, bei dem Dateiinhalte geändert worden sind.
Der Neustart eines Knotens mit einer neuen Version von ndbd.
Als letztes Mittel, wenn aus irgendeinem Grund der Neustart eines Knotens oder des Systems immer wieder scheitert. In diesem Fall müssen Sie jedoch berücksichtigen, dass der Knoten nun nicht mehr zur Wiederherstellung von Daten taugt, da seine Datendateien zerstört wurden.
Diese Option wirkt sich auf keine Sicherungsdateien aus, die von dem betroffenen Knoten bereits erzeugt worden sind.
--nodaemonVeranlasst, dass ndbd nicht als Daemon-Prozess startet. Dies ist nützlich, wenn Sie ndbd debuggen und die Ausgabe auf den Bildschirm umleiten möchten.
--nostartLässt ndbd nicht automatisch starten. Wenn diese Option benutzt wird, verbindet sich ndbd mit dem Management-Server, holt sich von diesem Konfigurationsdaten und initialisiert Kommunikationsobjekte. Die Ausführung wird jedoch erst dann gestartet, wenn der Management-Server es ausdrücklich verlangt, indem er dem Management-Client einen ausdrücklichen Befehl dafür gibt.
Optionen, die allen NDB-Programmen gemeinsam sind, finden Sie unter Abschnitt 16.5.5, „Befehlsoptionen für MySQL Cluster-Prozesse“.
--config-file=,file_name-f,file_nameSagt dem Management-Server, welches seine Konfigurationsdatei ist. Diese Option muss gesetzt werden; ihr Standardwert ist
config.ini.Achtung: Diese Option kann auch als
-cangegeben werden, aber diese Abkürzung ist veraltet und soll nicht in neueren Installationen verwendet werden.file_name--daemon,-dLässt ndb_mgmd als Daemon-Prozess starten. Dies ist das Standardverhalten.
--nodaemonLässt ndb_mgmd nicht als Daemon-Prozess starten.
Optionen, die allen NDB-Programmen gemeinsam sind, finden Sie unter Abschnitt 16.5.5, „Befehlsoptionen für MySQL Cluster-Prozesse“.
--try-reconnect=numberWenn die Verbindung zum Management-Server abbricht, versucht der Knoten alle 5 Sekunden, sich erneut zu verbinden, bis er damit Erfolg hat. Mit dieser Option können Sie die Anzahl der Verbindungsversuche auf
numberbegrenzen. Danach gibt der Knoten auf und meldet einen Fehler.
Zur Verwaltung eines MySQL Clusters gehören diverse Aufgaben, darunter an erster Stelle das Konfigurieren und Starten von MySQL Cluster. Dies wird in Abschnitt 16.4, „MySQL Cluster: Konfiguration“ und Abschnitt 16.5, „Prozessverwaltung in MySQL Cluster“, beschrieben.
In den folgenden Abschnitten wird beschrieben, wie man einen laufenden MySQL Cluster verwaltet.
Im Wesentlichen gibt es zwei Methoden, um einen laufenden MySQL
Cluster aktiv zu verwalten. Die erste: Sie können Befehle in den
Management-Client eingeben, um den Cluster-Status zu prüfen, die
Logebenen zu ändern, Datensicherungen zu starten und anzuhalten
und Knoten hoch- oder herunterzufahren. Die zweite Methode: Sie
prüfen den Inhalt des Cluster-Logs
ndb_
im node_id_cluster.logDataDir-Verzeichnis des Management-Servers.
(Denken Sie daran, dass node_id der
eindeutige Bezeichner des Knotens ist, dessen Aktivität
protokolliert wird.) Das Cluster-Log enthält Ereignisberichte,
die von ndbd generiert wurden. Es ist auch
möglich, Cluster-Logeinträge an ein Unix-Systemlog zu senden.
Dieser Abschnitt beschreibt die Schritte zum Starten eines Clusters.
Wie Sie hier sehen, gibt es mehrere Starttypen und -modi:
Initialstart: Der Cluster startet mit einem sauberen Dateisystem auf allen Knoten. Dies geschieht entweder, wenn der Cluster zum allerersten Mal gestartet wird, oder wenn er mit der Option
--initialneu gestartet wird.Neustart des Systems: Der Cluster startet und liest die in den Datenknoten gespeicherten Daten. Dies geschieht, wenn der Cluster, nachdem er nach Benutzung heruntergefahren wurde, den Betrieb an dem Punkt wieder aufnehmen soll, an dem er sich verabschiedet hatte.
Neustart eines Knotens: Dies ist der Online-Neustart eines Cluster-Knotens, während der Cluster selbst noch läuft.
Initialer Knoten-Neustart: Dies ist im Grunde dasselbe wie der Neustart eines Knotens, nur dass der Knoten hier neu initialisiert und mit einem sauberen Dateisystem hochgefahren wird.
Vor dem Starten muss jeder Datenknoten
(ndbd-Prozess) initialisiert werden. Hierzu
gehören folgende Schritte:
eine Knoten-ID besorgen
die Konfigurationsdaten beschaffen
die Ports für die Kommunikation zwischen den Knoten zuweisen
Hauptspeicher gemäß den Vorgaben der Konfigurationsdatei reservieren
Nachdem die Datenknoten initialisiert sind, kann der Startprozess des Clusters fortfahren. Dabei macht der Cluster folgende Stadien durch:
Stadium 0
Das Dateisystem des Clusters wird geleert. Dieses Stadium tritt nur dann ein, wenn der Cluster mit der Option
--initialgestartet wurde.Stadium 1
Nun werden die Cluster-Verbindungen eingerichtet, die Kommunikationskanäle zwischen den Knoten zugewiesen und die Heartbeats des Clusters gestartet.
Stadium 2
Der Arbitratorknoten wird ausgewählt. Wenn es sich um einen Neustart des Systems handelt, ermittelt der Cluster den letzten wiederherstellbaren globalen Checkpoint.
Stadium 3
Eine Reihe von internen Cluster-Variablen wird initialisiert.
Stadium 4
Für einen Initialstart oder initialen Knoten-Neustart werden die Redo-Logdateien angelegt. Die Anzahl dieser Dateien ist gleich
NoOfFragmentLogFiles.Bei einem System-Neustart:
werden das oder die Schema(ta) gelesen,
werden die Daten aus dem lokalen Checkpoint und den Redo-Logs gelesen,
werden alle Redo-Informationen angewendet, bis der letzte wiederherstellbare globale Checkpoint erreicht wurde.
Für einen Knoten-Neustart muss der Logtail des Redo-Logs gefunden werden.
Stadium 5
Wenn es sich um einen Initialstart handelt, werden die internen Systemtabellen
SYSTAB_0undNDB$EVENTSangelegt.Bei einem Knoten-Neustart oder initialen Knoten-Neustart:
wird der Knoten in die Transaktions-Behandlungsoperationen einbezogen.
wird das Knotenschema mit dem des Masters verglichen und synchronisiert,
werden die in
INSERT-Form von den anderen Datenknoten der Knotengruppe dieses Knotens empfangenen Daten synchronisiert.In allen Fällen wird gewartet, bis der Arbitrator bestimmt, dass ein lokaler Checkpoint vollständig ist.
Stadium 6
Interne Variablen werden aktualisiert.
Stadium 7
Interne Variablen werden aktualisiert.
Stadium 8
Bei einem Neustart eines Systems werden alle Indizes neu aufgebaut.
Stadium 9
Interne Variablen werden aktualisiert.
Stadium 10
Bei einem Knoten-Neustart oder initialen Knoten-Neustart können sich an diesem Punkt APIs mit dem Knoten verbinden und Ereignisse empfangen.
Stadium 11
Bei einem Knoten-Neustart oder initialen Knoten-Neustart wird an diesem Punkt die Lieferung von Ereignissen an den Knoten übergeben, der dem Cluster beitritt. Dieser neue Knoten übernimmt dann die Verantwortung für die Lieferung seiner primären Daten an die Abonnenten.
Nachdem dieser Prozess für einen Initialstart oder Neustart eines Systems abgeschlossen ist, wird die Transaktionsunterstützung aktiviert. Bei einem Knoten-Neustart oder initialen Knoten-Neustart bedeutet das Ende des Startprozesses, dass der Knoten nun als Transaktionskoordinator fungieren kann.
Ein Cluster kann nicht nur durch die zentrale Konfigurationsdatei, sondern auch über eine Kommandozeilenschnittstelle kontrolliert werden, die im Management-Client ndb_mgm zur Verfügung steht. Diese ist die wichtigste Administrationsschnittstelle für den Betrieb eines Clusters.
Befehle für die Ereignislogs stehen in Abschnitt 16.6.3, „Ereignisberichte, die MySQL Cluster erzeugt“, und Befehle für die Erstellung von Datensicherungen und die Wiederherstellung aus Datensicherungen in Abschnitt 16.6.5, „Online-Backup eines MySQL Clusters“.
Der Management-Client kennt folgende Grundbefehle. In der
nachfolgenden Liste steht node_id
entweder für eine Datenbankknoten-ID oder für das
Schlüsselwort ALL, das bedeutet, dass der
Befehl für alle Datenknoten des Clusters gilt.
HELPZeigt Informationen über die verfügbaren Befehle an.
SHOWZeigt Informationen über den Cluster-Status an.
Achtung: In einem Cluster, in dem mehrere Management-Knoten in Gebrauch sind, zeigt dieser Befehl nur über diejenigen Datenknoten Informationen an, die gerade mit dem aktuellen Management-Server verbunden sind.
node_idSTARTStartet den Datenknoten, der durch die
node_ididentifiziert ist (oder alle Datenknoten).node_idSTOPStoppt den Datenknoten, der durch die
node_ididentifiziert ist (oder alle Datenknoten).node_idRESTART [-N] [-I]Startet den Datenknoten neu, der durch die
node_ididentifiziert ist (oder alle Datenknoten).node_idSTATUSZeigt Statusinformationen über den Datenknoten an, der durch die
node_ididentifiziert ist (oder über alle Datenknoten).ENTER SINGLE USER MODEnode_idGeht in den Einbenutzermodus, wobei nur der MySQL Server, der durch die Knoten-ID
node_ididentifiziert ist, auf die Datenbank zugreifen darf.EXIT SINGLE USER MODEVerlässt den Einbenutzermodus, sodass alle SQL-Knoten (also alle laufenden mysqld-Prozesse) auf die Datenbank zugreifen können.
QUITBeendet den Management-Client.
SHUTDOWNFährt alle Cluster-Knoten außer den SQL-Knoten herunter und beendet den Management-Client.
In diesem Abschnitt geht es um die Ereignislog-Typen, die MySQL Cluster zur Verfügung stellt, und um die darin protokollierten Ereignisarten.
MySQL Cluster stellt zwei Typen von Ereignislogs zur Verfügung: das Cluster-Log mit Ereignissen, die von allen Cluster-Knoten generiert werden, und die Knoten-Logs, die lokal für die einzelnen Datenknoten geführt werden.
Die vom Cluster-Ereignislogging generierte Ausgabe kann mehrere
Ziele haben: eine Datei, die Konsole des Management-Servers oder
auch syslog. Die Ausgabe des
Knoten-Ereignisloggings wird in das Konsolenfenster des
Datenknotens geschrieben.
Beide Typen von Ereignislogs können auf die Protokollierung verschiedener Ereignisse eingestellt werden.
Hinweis: Das Cluster-Log ist das Log, das für die meisten Anwendungen empfohlen wird, da es Informationen über einen ganzen Cluster in einer einzigen Datei zur Verfügung stellt. Die Knoten-Logs sind nur für die Anwendungsentwicklung oder für das Debugging von Anwendungscode gedacht.
Protokollierbare Ereignisse können nach drei verschiedenen Kriterien unterschieden werden:
Kategorie (Category): Diese kann einer der folgenden Werte sein:
STARTUP,SHUTDOWN,STATISTICS,CHECKPOINT,NODERESTART,CONNECTION,ERRORoderINFO.Priorität (Priority): Diese wird in Ganzzahlen von 1 bis 15 einschließlich angegeben, wobei 1 „am wichtigsten“ und 15 „am unwichtigsten“ bedeutet.
Ernsthaftigkeit (Severity Level): Dies kann einer der folgenden Werte sein:
ALERT,CRITICAL,ERROR,WARNING,INFOoderDEBUG.
Sowohl Cluster- als auch Knoten-Log können anhand dieser Eigenschaften gefiltert werden.
Die folgenden Management-Befehle beziehen sich auf das Cluster-Log:
CLUSTERLOG ONSchaltet das Cluster-Log ein.
CLUSTERLOG OFFSchaltet das Cluster-Log aus.
CLUSTERLOG INFOGibt Informationen über die Einstellungen des Cluster-Logs.
node_idCLUSTERLOGcategory=thresholdProtokolliert
category-Ereignisse mit einer Priorität kleiner oder gleichthresholdim Cluster-Log.CLUSTERLOG FILTERseverity_levelSchaltet Cluster-Logging von Ereignissen des angegebenen
severity_levelein oder aus.
Die folgende Tabelle beschreibt die Standardeinstellung (für alle Datenknoten) für den Kategorie-Schwellenwert des Cluster-Logs. Ist die Priorität eines Ereignisses kleiner oder gleich dem Prioritäts-Schwellenwert, wird es in das Cluster-Log aufgenommen.
Beachten Sie, dass die Ereignisse pro Datenknoten gemeldet werden und dass der Schwellenwert (Threshold) für verschiedene Knoten unterschiedlich eingestellt werden kann.
| Kategorie | Standardschwellenwert (alle Datenknoten) |
STARTUP | 7 |
SHUTDOWN | 7 |
STATISTICS | 7 |
CHECKPOINT | 7 |
NODERESTART | 7 |
CONNECTION | 7 |
ERROR | 15 |
INFO | 7 |
Die Schwellenwerte dienen dazu, die Ereignisse innerhalb der
Kategorien zu filtern. So wird beispielsweise ein
STARTUP-Ereignis mit der Priorität 3 erst
protokolliert, wenn der Schwellenwert für
STARTUP auf 3 oder noch niedriger
eingestellt wird. Ist der Schwellenwert 3, werden nur
Ereignisse mit der Prioritätszahl drei oder kleiner als drei
protokolliert.
Die folgende Tabelle zeigt die Ernsthaftigkeit (den
Severity-Level) von Ereignissen.
(Hinweis: Diese Abstufungen
entsprechen den Ebenen des Unix-syslog, mit
Ausnahme von LOG_EMERG und
LOG_NOTICE, die nicht verwendet bzw.
zugeordnet werden.)
| 1 | ALERT | Eine Bedingung, die unverzüglich behoben werden muss, wie beispielsweise eine beschädigte Systemdatenbank |
| 2 | CRITICAL | Kritische Bedingungen, wie beispielsweise Gerätefehler oder unzureichende Ressourcen |
| 3 | ERROR | Bedingungen, die korrigiert werden sollten, wie beispielsweise Konfigurationsfehler |
| 4 | WARNING | Bedingungen, die zwar keine Fehler darstellen, aber eine Sonderbehandlung erfordern könnten |
| 5 | INFO | Meldungen zu Informationszwecken |
| 6 | DEBUG | Debugging-Meldungen, die für die Entwicklung von NDB
Cluster verwendet werden |
Die Ernsthaftigkeitsebenen für Ereignisse können ein- oder
ausgeschaltet werden (mit CLUSTERLOG
FILTER, siehe oben). Wenn eine Ernsthaftigkeitsebene
eingeschaltet ist, werden alle Ereignisse, deren Priorität
kleiner oder gleich dem Schwellenwert für die betreffende
Kategorie ist, protokolliert. Wenn die Ernsthaftigkeitsebene
ausgeschaltet ist, werden Ereignisse, die auf dieser Ebene
liegen, nicht protokolliert.
Ein Ereignisbericht in den Ereignislogs hat folgendes Format:
datetime[string]severity--message
Zum Beispiel:
09:19:30 2005-07-24 [NDB] INFO -- Node 4 Start phase 4 completed
Der folgende Abschnitt beschreibt alle Ereignisse, die gemeldet werden können, geordnet nach Kategorien und innerhalb der Kategorie nach Ernsthaftigkeit.
GCP und LCP bedeuten in den Ereignisbeschreibungen „Global Checkpoint“ und „Local Checkpoint“.
CONNECTION-Ereignisse
Diese Ereignisse hängen mit Verbindungen zwischen Cluster-Knoten zusammen.
| Ereignis | Priorität | Ernsthaftigkeit | Beschreibung |
DB nodes connected | 8 | INFO | Datenknoten verbunden |
DB nodes disconnected | 8 | INFO | Verbindung zum Datenknoten getrennt |
Communication closed | 8 | INFO | SQL-Knoten oder Datenknoten-Verbindung geschlossen |
Communication opened | 8 | INFO | Verbindung zum SQL- oder Datenknoten geöffnet |
CHECKPOINT-Ereignisse
Die folgenden Logmeldungen hängen mit Checkpoints zusammen.
| Ereignis | Priorität | Ernsthaftigkeit | Beschreibung |
LCP stopped in calc keep GCI | 0 | ALERT | LCP gestoppt |
Local checkpoint fragment completed | 11 | INFO | LCP auf einem Fragment abgeschlossen |
Global checkpoint completed | 10 | INFO | GCP fertig |
Global checkpoint started | 9 | INFO | Start eines GCP: REDO-Log wird auf Platte geschrieben |
Local checkpoint completed | 8 | INFO | LCP normal abgeschlossen |
Local checkpoint started | 7 | INFO | Start eines LCP: Daten auf Platte geschrieben |
Report undo log blocked | 7 | INFO | UNDO-Logging blockiert; Puffer läuft fast über |
STARTUP-Ereignisse
Die folgenden Ereignisse werden als Reaktion auf den Erfolg oder Misserfolg beim Starten eines Knotens oder des Clusters generiert. Außerdem geben sie Informationen über den Fortschritt des Startprozesses einschließlich Informationen über Logging-Aktivitäten.
| Ereignis | Priorität | Ernsthaftigkeit | Beschreibung |
Internal start signal received STTORRY | 15 | INFO | Blöcke, die nach Ende des Neustarts empfangen wurden |
Undo records executed | 15 | INFO | (Beschreibung nicht verfügbar) |
New REDO log started | 10 | INFO | GCI behält X, neuester wiederherstellbarer
GCI Y |
New log started | 10 | INFO | Log-Teil X, Beginn bei MB
Y, Ende bei MB
Z |
Node has been refused for inclusion in the cluster | 8 | INFO | Knoten kann wegen eines Konfigurationsfehlers nicht in den Cluster einbezogen werden, Kommunikation kann nicht hergestellt werden oder anderes Problem |
DB node neighbors | 8 | INFO | Zeigt benachbarte Datenknoten |
DB node start phase | 4 | INFO | Eine Startphase eines Datenknotens ist abgeschlossen |
Node has been successfully included into the cluster | 3 | INFO | Zeigt den Knoten, Manager-Knoten und dynamische ID an |
DB node start phases initiated | 1 | INFO | NDB Cluster-Knoten starten |
DB node all start phases completed | 1 | INFO | Gestartete NDB Cluster-Knoten |
DB node shutdown initiated | 1 | INFO | Herunterfahren des Datenknotens hat begonnen |
DB node shutdown aborted | 1 | INFO | Datenknoten kann nicht normal heruntergefahren werden |
NODERESTART-Ereignisse
Die folgenden Ereignisse werden beim Neustart eines Knotens generiert und geben Aufschluss über den Erfolg oder Misserfolg des Neustart-Prozesses.
| Ereignis | Priorität | Ernsthaftigkeit | Beschreibung |
Node failure phase completed | 8 | ALERT | Meldet den Abschluss von Node Failure-Phasen |
Node has failed, node state was | 8 | ALERT | Meldet das Scheitern eines Knotens |
Report arbitrator results | 2 | ALERT | Arbitration-Versuche können 8 mögliche Ergebnisse haben:
|
Completed copying a fragment | 10 | INFO | |
Completed copying of dictionary information | 8 | INFO | |
Completed copying distribution information | 8 | INFO | |
Starting to copy fragments | 8 | INFO | |
Completed copying all fragments | 8 | INFO | |
GCP takeover started | 7 | INFO | |
GCP takeover completed | 7 | INFO | |
LCP takeover started | 7 | INFO | |
LCP takeover completed (state = | 7 | INFO | |
Report whether an arbitrator is found or not | 6 | INFO | Die Suche nach einem Arbitrator kann 7 mögliche Ergebnisse haben:
|
STATISTICS-Ereignisse
Die folgenden Ereignisse sind statistischer Natur. Sie melden beispielsweise die Anzahl der Transaktionen oder anderer Operationen, die Datenmengen, die von einzelnen Knoten gesendet oder empfangen wurden, oder die Speicherauslastung.
| Ereignis | Priorität | Ernsthaftigkeit | Beschreibung |
Report job scheduling statistics | 9 | INFO | Mittelwerte der internen Job-Planungsstatistik |
Sent | 9 | INFO | Durchschnittliche Anzahl der an Knoten X
gesandten Bytes |
Received | 9 | INFO | Durchschnittliche Anzahl der von Knoten X
empfangenen Bytes |
Report transaction statistics | 8 | INFO | Anzahl von Transaktionen, Commits, Leseoperationen, Simple Reads, Schreiboperationen, nebenläufigen Operationen, Attributinformationen und Abbrüchen |
Report operations | 8 | INFO | Anzahl der Operationen |
Report table create | 7 | INFO | |
Memory usage | 5 | INFO | Ausnutzung von Data und Index Memory (80 %, 90 % und 100 %) |
ERROR-Ereignisse
Diese Ereignisse betreffen Fehler und Warnungen im Cluster. Ihr Auftreten ist ein Hinweis auf eine größere Fehlfunktion oder ein Versagen.
| Ereignis | Priorität | Ernsthaftigkeit | Beschreibung |
Dead due to missed heartbeat | 8 | ALERT | Der Knoten X wird für „tot“
erklärt, weil kein Heartbeat empfangen wurde |
Transporter errors | 2 | ERROR | |
Transporter warnings | 8 | WARNING | |
Missed heartbeats | 8 | WARNING | Beim Knoten X sind
Y Heartbeats ausgefallen |
General warning events | 2 | WARNING |
INFO-Ereignisse
Diese Ereignisse liefern allgemeine Informationen über den Zustand des Clusters und die mit seiner Wartung zusammenhängenden Aktivitäten, wie beispielsweise Logging und die Übermittlung von Heartbeats.
| Ereignis | Priorität | Ernsthaftigkeit | Beschreibung |
Sent heartbeat | 12 | INFO | Heartbeat, der an den Knoten X gesandt wurde |
Create log bytes | 11 | INFO | Logteil, Logdatei, MB |
General information events | 2 | INFO |
Im Einbenutzermodus kann der Datenbankadministrator den Zugriff auf das Datenbanksystem auf einen einzigen MySQL Server (SQL-Knoten) beschränken. Beim Eintritt in den Einbenutzermodus werden alle Verbindungen zu allen anderen MySQL Servern geräuschlos geschlossen und alle laufenden Transaktionen abgebrochen. Es dürfen keine neuen Transaktionen gestartet werden.
Sobald der Cluster im Einbenutzermodus läuft, hat nur noch der eine angegebene SQL-Knoten Zugriff auf die Datenbank.
Mit dem Befehl ALL STATUS können Sie sehen, wann der Cluster in den Einbenutzermodus gegangen ist.
Beispiel:
ndb_mgm> ENTER SINGLE USER MODE 5
Wenn dieser Befehl ausgeführt worden und der Cluster in den
Einbenutzermodus eingetreten ist, ist der SQL-Knoten mit der ID
5 der einzige zugelassene Benutzer des
Clusters.
Der im obigen Befehl angegebene Knoten muss ein MySQL Server-Knoten sein. Jeder Versuch, einen anderen Knotentyp anzugeben, wird zurückgewiesen.
Hinweis: Wenn der obige Befehl aufgerufen wird, werden alle auf dem angegebenen Knoten laufenden Transaktionen abgebrochen, die Verbindung wird geschlossen und der Server muss neu gestartet werden.
Der Befehl EXIT SINGLE USER MODE stellt den Status der Datenknoten des Clusters vom Einbenutzer- auf den normalen Modus um. MySQL Server, die auf eine Verbindung mit dem Cluster warten (d. h. darauf, dass der Cluster bereit ist und wieder zur Verfügung steht), erhalten wieder die Erlaubnis, eine Verbindung herzustellen. Der als Einbenutzer-SQL-Knoten gekennzeichnete MySQL Server läuft während und nach der Zustandsänderung weiter (sofern er immer noch verbunden ist).
Beispiel:
NDB> EXIT SINGLE USER MODE
Im Einbenutzermodus gibt es zwei empfohlene Vorgehensweisen für den Umgang mit einem Knoten-Absturz:
Methode 1:
Sie beenden alle Einbenutzertransaktionen.
Sie geben den Befehl EXIT SINGLE USER MODE ein.
Sie starten die Datenknoten des Clusters neu.
Methode 2:
Sie starten die Datenbankknoten neu, bevor Sie in den Einbenutzermodus gehen.
Dieser Abschnitt beschreibt, wie eine Datenbanksicherung erstellt und wie die Datenbank später aus einer Sicherung wiederhergestellt wird.
Eine Datensicherung ist eine Momentaufnahme der Datenbank zu einem gegebenen Zeitpunkt. Sie besteht aus drei Hauptteilen:
Metadaten: die Namen und Definitionen aller Datenbanktabellen
Tabellendatensätze: die Daten, die in den Datenbanktabellen zum Zeitpunkt der Datensicherung tatsächlich gespeichert waren
Transaktionslog: ein sequenzieller Logeintrag, der Ihnen sagt, wie und wann Daten in der Datenbank gespeichert wurden
Jeder dieser Teile wird auf allen Knoten gespeichert, deren Daten gesichert werden. Während der Datensicherung speichert jeder Knoten diese drei Teile in drei Dateien auf der Festplatte:
BACKUP-backup_id.node_id.ctlEine Steuerungsdatei mit Steuerungsinformationen und Metadaten. Jeder Knoten speichert dieselben Tabellendefinitionen (für alle Tabellen im Cluster) in seiner eigenen Version dieser Datei.
BACKUP-backup_id-0.node_id.dataEine Datendatei mit den Tabellendaten, die pro Fragment gespeichert werden. Das bedeutet, dass verschiedene Knoten während der Datensicherung verschiedene Fragmente speichern. Die Datei eines Knotens fängt immer mit einem Header an, auf dem die Tabelle steht, zu welcher die Datensätze gehören. Nach der Liste der Datensätze folgt ein Footer mit einer Prüfsumme für alle Datensätze.
BACKUP-backup_id.node_id.logEine Logdatei mit Datensätzen von committeten Transaktionen. Nur Transaktionen auf Tabellen, die in der Sicherung gespeichert sind, werden im Log festgehalten. Die gesicherten Knoten speichern unterschiedliche Datensätze, da unterschiedliche Knoten unterschiedliche Datenbankfragmente hosten.
Im obigen Listing ist backup_id der
Bezeichner für die Sicherung und
node_id der eindeutige Bezeichner
für den Knoten, welcher die Datei anlegt.
Ehe Sie eine Datensicherung starten, müssen Sie sich vergewissern, dass der Cluster dafür richtig konfiguriert ist. (Siehe Abschnitt 16.6.5.4, „Konfiguration für Cluster-Backup“.)
Um mit dem Management-Server eine Sicherung vorzunehmen, tun Sie Folgendes:
Sie starten den Management-Server (ndb_mgm).
Sie führen den Befehl
START BACKUPaus.Der Management-Server wird mit der Nachricht
Start of backup orderedantworten. Dies bedeutet, dass er den Request an den Cluster übermittelt, aber noch keine Reaktion empfangen hat.Der Management-Server antwortet mit
Backup, wobeibackup_idstartedbackup_idwieder der eindeutige Bezeichner für diese Sicherung ist. (Dieser Bezeichner wird auch im Cluster-Log gespeichert, wenn nichts anderes konfiguriert wurde.) Dies bedeutet, dass der Cluster den Backup-Request empfangen und verarbeitet hat. Es bedeutet jedoch nicht, dass die Sicherung abgeschlossen ist.Der Management-Server signalisiert durch die Nachricht
Backup, dass die Datensicherung abgeschlossen ist.backup_idcompleted
Um eine laufende Sicherung abzubrechen, gehen Sie folgendermaßen vor:
Sie starten den Management-Server.
Sie führen den Befehl
ABORT BACKUPaus. Die Zahlbackup_idbackup_idist der Backup-Bezeichner, der in der Antwort des Management-Servers beim Starten der Datensicherung angegeben wurde (in der NachrichtBackup).backup_idstartedDer Management-Server quittiert den Abbruchbefehl mit einem
Abort of backup. Beachten Sie, dass er bisher noch keine wirkliche Antwort auf diesen Request erhalten hat.backup_idorderedNach dem Abbruch der Datensicherung meldet der Management-Server
Backup. Dies bedeutet, dass der Cluster die Datensicherung beendet hat und alle mit ihr verbundenen Dateien aus dem Dateisystem des Clusters gelöscht wurden.backup_idhas been aborted for reasonXYZ
Es ist auch möglich, eine laufende Datensicherung von der System-Shell aus mit folgendem Befehl abzubrechen:
shell> ndb_mgm -e "ABORT BACKUP backup_id"
Hinweis: Wenn zum Zeitpunkt
des Abbruchbefehls keine Sicherung mit der
backup_id läuft, erstattet der
Management-Server darüber keine explizite Meldung. Immerhin
wird der ungültige Abbruchbefehl jedoch im Cluster-Log
erwähnt.
Das Programm zur Cluster-Wiederherstellung ist als separate Kommandozeilen-Utility namens ndb_restore implementiert. Es liest die angelegten Sicherungsdateien und fügt die darin gespeicherten Informationen in die Datenbank ein. Das Wiederherstellungsprogramm muss für jeden Satz von Sicherungsdateien einmal ausgeführt werden, also so viele Male, wie Datenbankknoten zum Zeitpunkt der Datensicherung ausgeführt wurden.
Wenn Sie das Wiederherstellungsprogramm
ndb_restore erstmals ausführen, müssen
Sie auch die Metadaten rekonstruieren. Mit anderen Worten: Sie
müssen die Datenbanktabellen wiederherstellen. (Beachten Sie,
dass der Cluster eine leere Datenbank haben müsste, wenn die
Wiederherstellung der Sicherung beginnt.) Das
Wiederherstellungsprogramm fungiert als API zum Cluster und
erfordert daher eine freie Verbindung zum Cluster. Ob diese
vorhanden ist, sagt Ihnen der
ndb_mgm-Befehl SHOW (den
Sie mit ndb_mgm -e SHOW auf der
System-Shell absetzen können). Mit der Option -c
können Sie
den MGM-Knoten angeben (mehr zu Verbindungs-Strings erfahren
Sie unter Abschnitt 16.4.4.2, „MySQL Cluster: connectstringconnectstring“). Die
Sicherungsdateien müssen in dem Verzeichnis liegen, welches
dem Wiederherstellungsprogramm als Argument übergeben wird.
Es ist möglich, eine Datenbanksicherung mit einer anderen
Konfiguration als die Erzeugung der Datenbank zu fahren.
Nehmen wir beispielsweise an, dass eine Sicherung mit der ID
12, die in einem Cluster mit zwei
Datenbankknoten mit den Knoten-IDs 2 und
3 angelegt wurde, in einem Cluster mit vier
Knoten wiederhergestellt werden soll. Dazu muss der Befehl
ndb_restore zweimal ausgeführt werden:
einmal für jeden Datenbankknoten in dem Cluster, in dem die
Sicherung durchgeführt wurde.
Hinweis: Schneller geht die Wiederherstellung, wenn sie parallel ausgeführt wird, vorausgesetzt, es stehen genügend Cluster-Verbindungen zur Verfügung. Allerdings müssen die Datendateien immer vor den Logs angewendet werden.
Vier Konfigurationsparameter sind für die Datensicherung äußerst wichtig:
BackupDataBufferSizeGibt an, wie viel Arbeitsspeicher für das Puffern von Daten zur Verfügung steht, ehe diese auf die Platte geschrieben werden.
BackupLogBufferSizeGibt an, wie viel Arbeitsspeicher für das Puffern von Logeinträgen zur Verfügung steht, ehe diese auf die Platte geschrieben werden.
BackupMemoryGibt an, wie viel Arbeitsspeicher in einem Datenbankknoten insgesamt für Datensicherungen reserviert ist. Dieser Wert sollte die Summe des zugewiesenen Speichers für Backup-Datenpuffer plus Backup-Logpuffer sein.
BackupWriteSizeDie Blockgröße, in der Daten auf die Platte geschrieben werden. Gilt sowohl für Backup-Datenpuffer als auch für Backup-Logpuffer.
Genauere Einzelheiten über diese Parameter finden Sie unter Abschnitt 16.4, „MySQL Cluster: Konfiguration“.
Wenn auf einen Backup-Request ein Fehlercode zurückgegeben wird, liegt dies wahrscheinlich an unzureichendem Arbeits- oder Festplattenspeicher. Sie sollten sich vergewissern, dass für die Datensicherung genügend Hauptspeicher zur Verfügung steht und dass auch auf der Festplattenpartition, die von der Datensicherung genutzt wird, ausreichend Platz ist.
NDB unterstützt keine Repeatable Reads,
was zu Problemen mit dem Wiederherstellungsprozess führen
kann. Zwar ist der Sicherungsprozess selbst
„heiß“, aber die Wiederherstellung eines MySQL
Clusters aus einer Datensicherung ist eben nicht zu 100 % ein
„heißer“ Prozess. Dies liegt daran, dass für
die Dauer des Wiederherstellungsprozesses laufende
Transaktionen Non-Repeatable Reads von der rekonstruierten
Datenbank erhalten. Das bedeutet, dass der Zustand der Daten
inkonsistent ist, während die Wiederherstellung noch läuft.
Schon bevor im Jahre 1996 mit dem Entwurf von NDB
Cluster
begonnen wurde, war offensichtlich, dass die Kommunikation
zwischen Knoten im Netzwerk eines der Hauptprobleme in der
Konstruktion von parallelen Datenbanken sein würde. Daher wurde
NDB Cluster schon von Anfang an für mehrere
verschiedene Datentransportmechanismen ausgelegt. In diesem Manual
verwenden wir für diese den Oberbegriff
Transporter.
Zurzeit unterstützt die MySQL Cluster-Codebasis vier verschiedene Transporter. Die meisten Anwender nutzen heutzutage TCP/IP über Ethernet, da diese Technik allgegenwärtig ist. Zudem ist TCP/IP der mit Abstand am besten getestete Transporter in MySQL Cluster.
Wir arbeiten daran, sicherzustellen, dass die Kommunikation mit dem ndbd-Prozess in möglichst großen „Happen“ abgewickelt wird, da dies für alle Arten der Datenübermittlung nur vorteilhaft ist.
Wer es wünscht, kann die Leistung sogar noch stärker steigern, indem er Direktverbindungen zwischen Clustern (Interconnects) verwendet. Es gibt zwei Möglichkeiten, diese zu errichten: entweder mit einem selbst definierten Transporter oder mit Socketimplementierungen, die den TCP/IP-Stapel bis zu einem gewissen Grade umgehen. Wir haben beide Techniken mit der SCI(Scalable Coherent Interface)-Technologie von Dolphin ausprobiert.
In diesem Abschnitt zeigen wir, wie man einen Cluster, der für normale TCP/IP-Kommunikation konfiguriert ist, auf SCI Sockets umstellt. Diese Dokumentation beruht auf der SCI Sockets-Version 2.3.0 auf dem Stand vom 1. Oktober 2004.
Voraussetzungen:
Alle Computer, die SCI Sockets nutzen sollen, müssen mit SCI-Karten ausgerüstet sein.
SCI Sockets können mit jeder beliebigen Version von MySQL Cluster benutzt werden. Es sind keine besonderen Builds erforderlich, da diese Technologie die ganz normalen Socketaufrufe verwendet, die in MySQL Cluster bereits zur Verfügung stehen. Allerdings werden SCI Sockets zurzeit nur von den Linux-Kernels 2.4 und 2.6 unterstützt. SCI Transporter wurden erfolgreich auch auf anderen Betriebssystemen getestet; wir selbst haben sie bisher allerdings nur auf Linux 2.4 erprobt.
Für SCI Sockets sind im Wesentlichen vier Dinge erforderlich:
Sie müssen die SCI Socket-Bibliotheken erstellen.
Sie müssen die Kernel-Bibliotheken von SCI Socket installieren.
Sie müssen eine oder zwei Konfigurationsdateien installieren.
Die Kernel-Bibliothek von SCI Socket muss entweder für den gesamten Computer oder für die Shell, in der MySQL Cluster-Prozesse gestartet werden, aktiviert sein.
Dieser Prozess muss für jeden Computer im Cluster wiederholt werden, auf dem SCI Sockets für die Kommunikation zwischen Knoten eigesetzt werden sollen.
Um SCI Sockets einsetzen zu können, müssen Sie zwei Packages beschaffen:
das Quellcode-Package mit den DIS-Support-Bibliotheken für die SCI Sockets-Bibliotheken
das Quellcode-Package für die SCI Socket-Bibliotheken selbst
Diese stehen gegenwärtig nur im Quellcodeformat zur Verfügung.
Die neuesten Versionen dieser Packages (zu dem Zeitpunkt, da
dies geschrieben wurde) sind
DIS_GPL_2_5_0_SEP_10_2004.tar.gz und
SCI_SOCKET_2_3_0_OKT_01_2004.tar.gz. Diese
oder neuere Versionen finden Sie unter
http://www.dolphinics.no/support/downloads.html.
Installation der Packages
Wenn Sie die Bibliotheks-Packages bekommen haben, müssen Sie sie als Erstes in die passenden Verzeichnisse entpacken, wobei die SCI Sockets-Bibliotheken in ein Verzeichnis unterhalb des DIS-Codes gelegt werden müssen. Als Nächstes müssen Sie die Bibliotheken erstellen. Das folgende Beispiel zeigt, mit welchen Befehlen dies auf Linux/x86 getan wird:
shell>tar xzf DIS_GPL_2_5_0_SEP_10_2004.tar.gzshell>cd DIS_GPL_2_5_0_SEP_10_2004/src/shell>tar xzf ../../SCI_SOCKET_2_3_0_OKT_01_2004.tar.gzshell>cd ../adm/bin/Linux_pkgsshell>./make_PSB_66_release
Diese Bibliotheken können auch für einige 64-Bit-Prozessoren erstellt werden. Um sie für Opteron-CPUs mit den 64-Bit-Erweiterungen einzurichten, führen Sie make_PSB_66_X86_64_release statt make_PSB_66_release aus. Wird der Build auf einem Itanium-Computer ausgeführt, verwenden Sie den Befehl make_PSB_66_IA64_release. Die X86-64-Variante müsste auf Intel EM64T-Architekturen funktionieren, wurde aber (unseres Wissens) noch nicht getestet.
Wenn der Build-Prozess abgeschlossen ist, liegen die
kompilierten Bibliotheken in einer gezippten tar-Datei namens
DIS-.
Nun muss das Package noch am richtigen Ort installiert werden.
In diesem Beispiel legen wir die Installation in das Verzeichnis
<operating-system>-time-date/opt/DIS.
(Hinweis: Wahrscheinlich
müssen Sie die Anweisungen als Systembenutzer
root ausführen.)
shell>cp DIS_Linux_2.4.20-8_181004.tar.gz /opt/shell>cd /optshell>tar xzf DIS_Linux_2.4.20-8_181004.tar.gzshell>mv DIS_Linux_2.4.20-8_181004 DIS
Netzwerkkonfiguration
Nun, da alle Bibliotheken und Binaries am richtigen Platz sind, müssen Sie noch dafür sorgen, dass die SCI-Karten die richtigen Knoten-IDs im SCI-Adressraum haben.
Außerdem müssen Sie eine Entscheidung über die Netzwerkstruktur treffen, ehe Sie fortfahren. In diesem Zusammenhang sind drei Arten von Netzwerkstrukturen möglich:
ein einfacher, eindimensionaler Ring
ein oder mehrere SCI-Switches mt einem Ring pro Switch-Port
ein zwei- oder dreidimensionaler Torus
Jede dieser Netzwerktopologien hat ihre eigene Methode, um Knoten-IDs zu liefern. Alle diese Methoden werden im Folgenden kurz erklärt.
Ein einfacher Ring verwendet IDs, die von Null verschiedene Vielfache von 4 sind: 4, 8, 12, ...
Die nächste Möglichkeit verwendet SCI-Switches. Ein SCI-Switch hat 8 Ports, von denen jeder einen Ring unterstützen kann. Sie müssen dafür sorgen, dass verschiedene Ringe verschiedene ID-Räume benutzen. In einer typischen Konfiguration nutzt der erste Port Knoten-IDs unter 64 (4 – 60), der nächste Port die nächsten 64 Knoten-IDs (68–124), und so weiter, sodass die Knoten-IDs 452–508 dem 8. Port zugewiesen werden.
Zwei- und dreidimensionale Torus-Netzwerktopologien nehmen Rücksicht darauf, wo der einzelne Knoten in welcher Dimension angesiedelt ist, indem sie für jeden Knoten in der ersten Dimension um 4 hochzählen, für jeden in der zweiten Dimension um 64 und (wenn vorhanden) für jeden in der dritten Dimension um 1024. Auf der Website von Dolphin finden Sie Genaueres zum Thema.
In unseren Tests haben wir Switches verwendet, obwohl die meisten großen Cluster-Installationen 2- oder 3-dimensionale Torusstrukturen verwenden. Switches haben den Vorteil, dass man mit dualen SCI-Karten und dualen Switches relativ einfach ein redundantes Netzwerk aufbauen kann, wobei die durchschnittlichen Ausfallzeiten im SCI-Netzwerk im Bereich von 100 Mikrosekunden liegen. Dies wird von dem SCI Transporter in MySQL Cluster unterstützt und auch für die SCI Socket-Implementierung zurzeit entwickelt.
Auch für den 2D-/3D-Torus ist eine Ausfallsicherung möglich, doch hierfür ist es erforderlich, an alle Knoten neue Routing-Indizes auszusenden. Dies nimmt allerdings nur circa 100 Millisekunden Zeit in Anspruch, was für die meisten Hochverfügbarkeitssysteme noch akzeptabel sein dürfte.
Indem Sie die Cluster-Datenknoten in der geswitchten Architektur sorgfältig platzieren, können Sie mit 2 Switches eine Struktur aufbauen, in der 16 Computer miteinander verbunden sind und nie mehr als einer von ihnen durch einen einzelnen Fehler ausfallen kann. Mit 32 Computern und 2 Switches können Sie den Cluster so konfigurieren, dass ein einzelner Absturz nie mehr als 2 Knoten betreffen kann und dass darüber hinaus bekannt wird, um welches Knotenpaar es sich handelt. Indem Sie diese beiden Knoten dann in separate Knotengruppen verlegen, können Sie sogar eine „sichere“ MySQL Cluster-Installation bekommen.
Um die Knoten-ID für eine SCI-Karte zu setzen, geben Sie
folgenden Befehl im Verzeichnis
/opt/DIS/sbin ein. In diesem Beispiel ist
-c 1 die Nummer der SCI-Karte (diese ist immer
1, wenn nur eine Karte in den Computer eingebaut ist),
-a 0 ist der Adapter 0 und
68 ist die Knoten-ID:
shell> ./sciconfig -c 1 -a 0 -n 68
Wenn mehrere SCI-Karten in demselben Computer eingebaut sind,
können Sie mit folgendem Befehl ermitteln, welche Karte welchen
Steckplatz hat (wir gehen wieder davon aus, dass
/opt/DIS/sbin das aktuelle
Arbeitsverzeichnis ist):
shell> ./sciconfig -c 1 -gsn
So erhalten Sie die Seriennummer der SCI-Karte. Diesen Vorgang
wiederholen Sie dann mit -c 2 und so weiter
für jede Karte im Computer. Sobald Sie jede Karte einem
Steckplatz zugeordnet haben, können Sie für alle Karten
Knoten-IDs einrichten.
Sobald die notwendigen Bibliotheken und Binaries installiert und
die SCI-Knoten-IDs gesetzt sind, ordnen Sie als Nächstes die
Hostnamen oder IP-Adressen den SCI-Knoten-IDs zu. Dies tun Sie
in der Konfigurationsdatei für SCI Sockets, die normalerweise
unter /etc/sci/scisock.conf gespeichert
sein müsste.
In dieser Datei ist jeder SCI-Knoten-ID über die jeweilige
SCI-Karte der Hostname oder die IP-Adresse zugeordnet, mit der
sie kommunizieren soll. Hier sehen Sie ein sehr einfaches
Beispiel für eine solche Konfigurationsdatei:
#host #nodeId alpha 8 beta 12 192.168.10.20 16
Sie können die Konfiguration auch so einschränken, dass sie
nur für einen Teil der verfügbaren Ports für diese Hosts
gilt. Hierfür können Sie eine zusätzliche Konfigurationsdatei
namens /etc/sci/scisock_opt.conf verwenden:
#-key -type -values EnablePortsByDefault yes EnablePort tcp 2200 DisablePort tcp 2201 EnablePortRange tcp 2202 2219 DisablePortRange tcp 2220 2231
Treiberinstallation
Wenn die Konfigurationsdateien eingerichtet sind, können die Treiber installiert werden.
Als Erstes installieren Sie die Treiber der unteren Ebene und dann den SCI Socket-Treiber:
shell>cd DIS/sbin/shell>./drv-install add PSB66shell>./scisocket-install add
Auf Wunsch kann die Installation mit einem Skript überprüft werden, das nachschaut, ob auf alle Knoten in den SCI Socket-Konfigurationsdateien Zugriff besteht:
shell>cd /opt/DIS/sbin/shell>./status.sh
Wenn Sie auf einen Fehler stoßen und die SCI Socket-Konfiguration ändern müssen, so tun Sie dies mit ksocketconfig:
shell>cd /opt/DIS/utilshell>./ksocketconfig -f
Das Setup testen
Mit dem Testprogramm latency_bench können
Sie sich vergewissern, dass auch tatsächlich die SCI Sockets
benutzt werden. Mit der Serverkomponente dieses Dienstprogramms
können sich die Clients mit dem Server verbinden, um die
Verbindungslatenz zu überprüfen. Wenn Sie die Latenz
beobachten, haben Sie schnell heraus, ob SCI aktiviert ist oder
nicht. (Hinweis: Bevor Sie
latency_bench sagen, müssen Sie die
Umgebungsvariable LD_PRELOAD so einstellen,
wie es weiter unten in diesem Abschnitt gezeigt wird.)
Um einen Server einzurichten, tun Sie Folgendes:
shell>cd /opt/DIS/bin/socketshell>./latency_bench -server
Um einen Client zu betreiben, führen Sie
latency_bench erneut aus, diesmal allerdings
mit der Option -client:
shell>cd /opt/DIS/bin/socketshell>./latency_bench -clientserver_hostname
Die SCI Socket-Konfiguration sollte nun abgeschlossen und MySQL Cluster bereit für die Nutzung von SCI Sockets und SCI Transporter sein (siehe Abschnitt 16.4.4.10, „MySQL Cluster: SCI-Transportverbindungen“).
Den Cluster starten
Der nächste Schritt besteht darin, MySQL Cluster zu starten. Um
SCI Sockets einzuschalten, müssen Sie die Umgebungsvariable
LD_PRELOAD einstellen, bevor Sie
ndbd, mysqld und
ndb_mgmd laufen lassen. Diese Variable sollte
auf die Kernel-Bibliothek von SCI Sockets verweisen.
Folgendermaßen wird ndbd in einer Bash-Shell gestartet:
bash-shell>export LD_PRELOAD=/opt/DIS/lib/libkscisock.sobash-shell>ndbd
In einer tcsh-Umgebung erreichen Sie dasselbe mit:
tcsh-shell>setenv LD_PRELOAD=/opt/DIS/lib/libkscisock.sotcsh-shell>ndbd
Hinweis: MySQL Cluster kann nur die Kernel-Variante von SCI Sockets nutzen.
Der ndbd-Prozess hat eine Reihe von einfachen Konstrukten, um auf die Daten in einem MySQL Cluster zuzugreifen. Wir haben eine ganz einfache Benchmark erstellt, um die jeweilige Leistung dieser Konstrukte zu testen und herauszufinden, wie sich die verschiedenen Verbindungen zwischen den Knoten auf diese Leistung auswirken.
Es gibt vier Zugriffsmethoden:
Zugriff über Primärschlüssel
Das ist der Zugriff auf einen Datensatz über seinen Primärschlüssel. Im einfachsten Fall wird immer nur auf einen einzigen Datensatz zugegriffen, was bedeutet, dass dieser eine einzige Request den vollen Aufwand verursacht, der erforderlich ist, um mehrere TCP/IP-Nachrichten und Kontextwechsel zu bewältigen. Wenn dagegen mehrere Primärschlüsselzugriffe in einem Stapel versandt werden, teilen sich diese Zugriffe die Kosten der notwendigen TCP/IP-Nachrichten und Kontextwechsel. Wenn die TCP/IP-Nachrichten an verschiedene Ziele gehen, müssen allerdings zusätzliche TCP/IP-Nachrichten eingerichtet werden.
Zugriff über eindeutigen Schlüssel
Zugriffe über eindeutige (unique) Schlüssel ähneln den Primärschlüsselzugriffen, allerdings mit dem Unterschied, dass sie als Leseoperation auf einer Indextabelle mit nachgeschaltetem Primärschlüsselzugriff auf die Tabelle funktionieren. Allerdings wird nur ein einziger Request vom MySQL Server abgeschickt und der Lesevorgang auf der Indextabelle wird von ndbd ausgeführt. Auch diese Art von Requests profitiert von der Stapelverarbeitung.
Vollständiger Tabellenscan
Wenn für einen Tabellen-Lookup keine Indizes vorhanden sind, wird ein vollständiger Tabellenscan ausgeführt. Dieser wird als ein einziger Request an den ndbd-Prozess gesandt, der dann den Tabellenscan in eine Menge von parallelen Scans auf alle ndbd-Prozesse im Cluster verteilt. In künftigen Versionen von MySQL Cluster wird ein SQL-Knoten in der Lage sein, manche dieser Scans herauszufiltern.
Bereichsscan mit geordnetem Index
Wenn ein geordneter Index verwendet wird, führt dieser eine Art vollständigen Tabellenscan aus, scannt aber nur die Datensätze in dem Intervall, welches die vom MySQL Server (SQL-Knoten) übermittelte Anfrage angibt. Alle Partitionen werden parallel gescannt, wenn alle gebundenen Indexattribute alle Attribute im Partitionierungsschlüssel enthalten.
Um die Grundleistung dieser Zugriffsmethoden testen zu können, haben wir eine Reihe von Benchmarks entwickelt. Eine davon, nämlich testReadPerf, testet einzeln und im Stapel übersandte Zugriffe über Primärschlüssel oder eindeutige Schlüssel. Diese Benchmark misst auch den Setup-Aufwand von Bereichsscans, indem sie Scans ausführt, die einen einzelnen Datensatz zurückliefern. Eine andere Variante dieser Benchmark holt mit einem Bereichsscan eine Menge von Datensätzen ab.
So können wir die Kosten eines einzelnen Schlüsselzugriffs und eines einzelnen Datensatzscans ermitteln und zusätzlich festellen, wie sich die Kommunikationsmedien bei welcher Zugriffsmethode auswirken.
In unseren Tests haben wir die Basis-Benchmarks sowohl für einen normalen Transporter mit TCP/IP-Sockets als auch für eine ähnliche Umgebung mit SCI Sockets ermittelt. Die Zahlen in der folgenden Tabelle gelten für kleinere Abfragen mit 20 Datensätzen pro Zugriff. Die Differenz zwischen seriellem und Stapelzugriff access schrumpft um den Faktor 3 bis 4, wenn stattdessen 2-Kbyte-Datensätze verwendet werden. SCI Sockets wurden nicht mit 2-Kbyte-Datensätzen getestet. Die Tests wurden auf einem Cluster mit 2 Datenknoten gefahren, der auf zwei Computern mit je zwei CPUs (AMD MP1900+-Prozessoren) residiert.
| Zugriffsart | TCP/IP-Sockets | SCI Socket |
| Serieller Primärschlüsselzugriff | 400 Mikrosekunden | 160 Mikrosekunden |
| Primärschlüsselzugriff im Stapel | 28 Mikrosekunden | 22 Mikrosekunden |
| Serieller Zugriff auf eindeutigen Schlüssel | 500 Mikrosekunden | 250 Mikrosekunden |
| Stapelzugriff auf eindeutigen Schlüssel | 70 Mikrosekunden | 36 Mikrosekunden |
| Indizierter eq-bound | 1.250 Mikrosekunden | 750 Mikrosekunden |
| Indexbereich | 24 Mikrosekunden | 12 Mikrosekunden |
In einer anderen Testreihe haben wir die Leistung der SCI Sockets der des SCI Transporters und diese beiden wiederum der Leistung eines TCP/IP-Transporters gegenübergestellt. Alle diese Tests verwendeten Primärschlüsselzugriffe, entweder seriell und mit mehreren Threads oder mit mehreren Threads und im Stapel.
Die Tests haben gezeigt, dass SCI Sockets um rund 100 % schneller waren als TCP/IP. Der SCI Transporter war in den meisten Fällen schneller als SCI Sockets. Ein bemerkenswerter Fall trat bei einem Testprogramm mit vielen Threads auf: Hier zeigte sich, dass der SCI Transporter keine gute Leistung brachte, wenn er für den mysqld-Prozess benutzt wird.
Insgesamt zeigen unsere Tests, dass SCI Sockets in den meisten Benchmarks rund 100 % schneller sind als TCP/IP, außer in seltenen Fällen, in denen es nicht auf die Geschwindigkeit der Kommunikation ankommt. Dies kann der Fall sein, wenn die meiste Verarbeitungszeit für Scanfilter verbraucht wird oder wenn sehr große Stapel von Primärschlüsselzugriffen zustande kommen. In diesem Fall macht die CPU-Last der ndbd-Prozesse einen großen Teil des Aufwands aus.
Eine Verwendung des SCI Transporters anstelle von SCI Sockets ist nur für die Kommunikation zwischen ndbd-Prozessen interessant. Der SCI Transporter ist jedoch auch eine Option, wenn eine CPU für den ndbd-Prozess dediziert werden kann, da der SCI Transporter dafür sorgen kann, dass dieser Prozess niemals schläft. Außerdem ist es wichtig, zu gewährleisten, dass die Priorität des ndbd-Prozesses so eingestellt wird, dass er auch nach langem Laufen seine Priorität nicht einbüßt. Dies kann in Linux 2.6 durch das Sperren von Prozessen in CPUs getan werden. Wenn eine solche Konfiguration machbar ist, legt der ndbd-Prozess im Vergleich zu einer Lösung mit SCI Sockets um 10 bis 70 % zu. (Die größeren Zahlen kommen bei Updates und möglicherweise auch bei Parallelscans zustande.)
Es gibt noch mehrere andere optimierte Socketimplementierungen für Computer-Cluster, darunter Myrinet, Gigabit Ethernet, Infiniband und die VIA-Schnittstelle. Wir haben MySQL Cluster bisher jedoch nur mit SCI Sockets getestet. Unter Abschnitt 16.7.1, „Konfiguration von MySQL Cluster für SCI Sockets“, erfahren Sie, wie Sie SCI Sockets mit normalem TCP/IP für MySQL Cluster einrichten.
In diesem Abschnitt finden Sie eine Liste bekannter
Einschränkungen in den MySQL Cluster-Releases der
5.1.x-Serie im Vergleich zu den Features, die beim
Einsatz der Speicher-Engines MyISAM und
InnoDB zur Verfügung stehen. Es ist zurzeit
nicht geplant, diese Einschränkungen in den nächsten Releases
von MySQL 5.1 zu beseitigen, aber wir werden
versuchen, in der darauf folgenden Serie von Releases Lösungen
für diese Probleme zu finden. Wenn Sie in der
MySQL-Bugs-Datenbank http://bugs.mysql.com unter
der Kategorie „Cluster“ nachschauen, erfahren Sie,
welche bekannten Bugs (soweit sie mit
„5.1“ markiert sind) in den nächsten
Releases von MySQL 5.1 behoben werden sollen.
Die hier aufgeführte Liste sollte unter den soeben genannten Bedingungen komplett sein. Falls Ihnen irgendwelche Diskrepanzen auffallen, können Sie diese an die MySQL-Bugs-Datenbank melden, wie es unter Abschnitt 1.8, „Wie man Bugs oder Probleme meldet“, beschrieben ist. Wenn wir nicht planen, das Problem in MySQL 5.1 zu beheben, werden wir es mit auf die Liste setzen.
Nichtkonforme Syntax (führt zu Fehlern bei der Ausführung vorhandener Anwendungen):
Textindizes werden nicht unterstützt.
Geometrische Datentypen (
WKTundWKB) werden inNDB-Tabellen in MySQL 5.1 unterstützt, aber raumbezogene (spatial) Indizes nicht.Es ist nicht möglich, Partitionen von
NDB-Tabellen mitALTER TABLE ... DROP PARTITIONzu löschen. Die anderen Partitionierungserweiterungen fürALTER TABLE, nämlichADD PARTITION,REORGANIZE PARTITIONundCOALESCE PARTITION, werden für Cluster-Tabellen unterstützt, aber Kopieren usw. ist nicht optimiert. Siehe auch Abschnitt 17.3.1, „Verwaltung vonRANGE- undLIST-Partitionen“, und Abschnitt 13.1.2, „ALTER TABLE“.Seit MySQL 5.1.6 werden alle Cluster-Tabellen standardmäßig nach
KEYpartitioniert, wobei der Primärschlüssel der Tabelle als Partitionierungsschlüssel verwendet wird. Ist für die Tabelle nicht explizit ein Primärschlüssel definiert, wird automatisch von der Speicher-EngineNDBein „verborgener“ Primärschlüssel erzeugt und benutzt. Mehr zu diesem und verwandten Themen finden Sie unter Abschnitt 17.2.4, „KEY-Partitionierung“.
Nichtkonforme Grenzwerte oder Verhalten (kann bei der Ausführung vorhandener Anwendungen zu Fehlern führen):
Transaktionsbehandlung:
NDB Clusterunterstützt als einzige Ebene der TransaktionsisolationREAD COMMITTED.Ein teilweises Zurückrollen von Transaktionen ist nicht möglich. Ein Fehler wegen eines doppelten Schlüssels oder etwas Ähnlichem führt dazu, dass die gesamte Transaktion zurückgerollt wird.
Wichtig: Wenn ein
SELECTauf einer Cluster-Tabelle eine Spalte des TypsBLOB,TEXToderVARCHARenthält, wird die TransaktionsisolationsebeneREAD COMMITTEDin einen Lesevorgang mit Lesesperre umgewandelt. Dies wird getan, um die Konsistenz zu garantieren, da Teile der in solchen Spalten gespeicherten Werte in Wirklichkeit aus einer anderen Tabelle gelesen werden.
Es gibt eine Reihe von harten Grenzwerten, die konfigurierbar sind, aber der im Cluster verfügbare Hauptspeicher setzt auf jeden Fall Grenzen. Die vollständige Liste der Konfigurationsparameter finden Sie in Abschnitt 16.4.4, „Konfigurationsdatei“. Die meisten dieser Parameter können online aktualisiert werden. Die erwähnten festen Grenzen sind:
Jeweiliger Arbeitsspeicher für Datenbank und Index (
DataMemoryundIndexMemory).Wie viele Transaktionen höchstens ausgeführt werden können, ist im Konfigurationsparameter
MaxNoOfConcurrentOperationsfestgelegt. Beachten Sie, das Massenladeoperationen,TRUNCATE TABLE, undALTER TABLEals Sonderfälle mit mehreren Transaktionen abgearbeitet werden und daher nicht dieser Einschränkung unterliegen.Verschiedene Grenzwerte für Tabellen und Indizes. So wird beispielsweise die Höchstzahl der geordneten Indizes pro Tabelle durch
MaxNoOfOrderedIndexesfestgesetzt.
Datenbank-, Tabellen- und Attributnamen dürfen in
NDB-Tabellen nicht so lang sein wie bei anderen Tabellen-Handlern. Attributnamen werden auf 31 Zeichen gekappt. Wenn sie dann nicht mehr eindeutig sind, gibt es einen Fehler. Datenbank- und Tabellennamen können insgesamt 122 Zeichen lang sein. (Das bedeutet, dass ein Name einerNDB Cluster-Tabelle maximal 122 Zeichen minus die Länge des Namens der Datenbank haben kann, zu welcher die Tabelle gehört.)Alle Zeilen von Cluster-Tabellen haben eine feste Länge. Wenn also (zum Beispiel) eine Tabelle ein oder mehrere
VARCHAR-Felder mit relativ kleinen Werten hat, brauchen diese bei der Speicher-EngineNDBmehr Speicherplatz als bei der Speicher-EngineMyISAM. (Mit anderen Worten, eineVARCHAR-Spalte belegt beispielsweise ebenso viel Speicher wie eine gleich großeCHAR-Spalte.)Die Höchstzahl der Tabellen in einer Cluster-Datenbank ist auf 1.792 beschränkt.
Die Höchstzahl der Attribute pro Tabelle ist auf 128 beschränkt.
Die maximal zulässige Größe einer Zeile ist 8 Kbyte, nicht inbegriffen die in
BLOB-Spalten gespeicherten Daten.Die Höchstzahl der Attribute pro Schlüssel beträgt 32.
Nicht unterstützte Features (verursachen keinen Fehler, werden aber nicht unterstützt oder verlangt):
Das Fremdschlüsselkonstrukt wird, genau wie in
MyISAM-Tabellen, ignoriert.Savepoints und Rollbacks zu Savepoints werden, genau wie in
MyISAM-Tabellen, ignoriert.
Probleme im Zusammenhang mit Leistung und Einschränkungen:
Aufgrund des sequenziellen Zugriffs hat die
NDB-Speicher-Engine Leistungsprobleme mit Anfragen. Auch ist es aufwändiger als mitMyISAModerInnoDB, viele Bereichsscans auszuführen.Die
Records in range-Statistik wird nicht unterstützt, sodass sich in einigen Fällen ungünstige Anfragenpläne ergeben. Als Workaround empfehlen sichUSE INDEXoderFORCE INDEX.Sie können keine mit
USING HASHerzeugten eindeutigen Hash-Indizes für den Zugriff auf eine Tabelle verwenden, wennNULLals Teil des Schlüssels angegeben ist.MySQL Cluster unterstützt keine permanenten Commits auf der Platte. Commits werden repliziert, aber es gibt keine Garantie dafür, dass die Logs beim Committen auf die Platte zurückgeschrieben werden.
Fehlende Features:
Die einzige Isolationsebene, die unterstützt wird, ist
READ COMMITTED. (InnoDB unterstütztREAD COMMITTED,READ UNCOMMITTED,REPEATABLE READundSERIALIZABLE.) Unter Abschnitt 16.6.5.5, „Backup: Troubleshooting“, können Sie nachlesen, wie sich dies auf die Sicherung und Wiederherstellung von Cluster-Datenbanken auswirkt.Es gibt keine dauerhaften Commits auf der Platte. Die Commits werden repliziert, aber es gibt keine Garantie dafür, dass die Logs beim Committen auf die Platte zurückgeschrieben werden.
Probleme mit mehreren MySQL Servern (betreffen nicht
MyISAModerInnoDB):ALTER TABLEsperrt nicht vollständig, wenn mehrere MySQL Server betrieben werden (keine verteilte Tabellensperre).MySQL-Replikation funktioniert nicht richtig, wenn Updates auf mehreren MySQL Servern ausgeführt werden. Wenn jedoch das Datenbank-Partitionierungsschema auf Anwendungsebene durchgeführt wird und keine Transaktionen über diese Partitionen hinweg stattfinden, kann die Replikation funktionieren.
Das selbstständige Erkennen von Datenbanken wird nicht für mehrere MySQL Server unterstützt, die auf denselben MySQL Cluster zugreifen. Die selbstständige Erkennung von Tabellen wird dagegen in diesen Fälllen unterstützt. Wenn also eine Datenbank namens
db_namemit einem einzigen MySQL Server angelegt oder importiert wurde, müssen Sie für jeden weiteren Server, der auf denselben MySQL Cluster zugreift, eineCREATE SCHEMA-Anweisung erteilen. Wenn dies für einen gegebenen MySQL Server erledigt ist, müsste dieser in der Lage sein, die Datenbanktabellen ohne Fehler zu erkennen.db_name
Probleme, die ausschließlich MySQL Cluster betreffen (nicht
MyISAModerInnoDB):Alle Cluster-Computer müssen dieselbe Architektur haben. Das bedeutet, dass alle Knoten-Hosts konsistent entweder big-endian oder little-endian sein müssen. Beispielsweise darf es keinen Management-Knoten auf einem Power-PC geben, der einen Datenknoten auf einer x86-Maschine regelt. Diese Einschränkung gilt nicht für Computer, die einfach nur mysql ausführen, oder andere Clients, die vielleicht auf die SQL-Knoten des Clusters zugreifen.
Es sind keine Online-Schemaänderungen mit
ALTER TABLEoderCREATE INDEXmöglich, daNDB Clusternicht die selbstständige Erkennung solcher Änderungen unterstützt. (Sie können jedoch eine Tabelle importieren oder anlegen, die eine andere Speicher-Engine nutzt, und diese dann mitALTER TABLEin einetbl_nameENGINE=NDBCLUSTERNDB-Tabelle umwandeln. In solchen Fällen müssen Sie eineFLUSH TABLES-Anweisung geben, um den Cluster zu zwingen, die Änderung aufzugreifen.)Es ist nicht möglich, Knoten online hinzuzufügen oder zu löschen (der Cluster muss in solchen Fällen neu gestartet werden).
Wenn mehrere Management-Server verwendet werden, gelten folgende Regeln:
Sie müssen den Knoten in Verbindungs-Strings explizite IDs geben, da die automatische Zuweisung von Knoten-IDs nicht über mehrere Management-Server hinweg funktioniert.
Sie müssen genau darauf achten, dass alle Management-Server gleich konfiguriert sind. Der Cluster wird dies nicht extra prüfen.
Damit die Management-Knoten voneinander wissen, müssen Sie alle Datenknoten neu starten, nachdem der Cluster eingerichtet ist. (Genaue Erläuterungen finden Sie unter Bug#13070.)
Einige Netzwerkschnittstellen für Datenknoten werden nicht unterstützt. Wenn Sie diese verwenden, bekommen Sie Probleme: Wenn ein Datenknoten abstürzt, wartet ein SQL-Knoten auf die Bestätigung, dass der Datenknoten nicht mehr läuft, bekommt aber keine, da eine andere Route zu dem betroffenen Datenknoten weiterhin offen bleibt. Im Endeffekt kann dies den ganzen Cluster unbenutzbar machen.
Die Höchstzahl der Datenknoten beträgt 48.
Die Gesamtzahl aller Knoten in einem MySQL Cluster beträgt 63. Das umfasst sämtliche MySQL Server (SQL-Knoten), Datenknoten und Management-Server.
Die Höchstzahl der Metadatenobjekte in MySQL 5.1 Cluster beträgt 20.320. Diese Obergrenze ist fest eingegeben.
In diesem Abschnitt geht es um Änderungen an der Implementierung von MySQL Cluster in MySQL 5.1 im Vergleich zu MySQL 5.0. Außerdem werden wir unseren Fahrplan für künftige Verbesserungen an MySQL Cluster vorstellen, wie sie gegenwärtig für MySQL 5.2 vorgesehen sind.
Es gibt relativ wenig Änderungen zwischen der Implementierung von NDB Cluster in MySQL 5.0 und in 5.1, sodass der Upgrade relativ schnell und schmerzlos vonstatten gehen sollte.
Alle bedeutenden neuen Features, die für MySQL Cluster entwickelt werden sollen, kommen in den Baum von MySQL 5.1. Außerdem weisen wir weiter unten in diesem Abschnitt (siehe Abschnitt 16.9.2, „MySQL 5.1 Roadmap für die Entwicklung von MySQL Cluster“) darauf hin, was die Cluster in MySQL 5.1 voraussichtlich alles enthalten werden.
MySQL Cluster enthält in den Versionen 5.0.3-beta und folgende eine Reihe von neuen Features, die sicherlich interessant sein werden:
Pushdown-Bedingungen: Betrachten Sie folgende Anfrage:
SELECT * FROM t1 WHERE non_indexed_attribute = 1;
Diese Anfrage wird einen vollständigen Tabellenscan ausführen und die Bedingung wird in den Datenknoten des Clusters ausgewertet. Daher ist es nicht nötig, die Datensätze zur Auswertung durchs Netzwerk zu schicken. (Es werden also Funktionen und nicht Daten transportiert.) Bitte beachten Sie, dass dieses Feature gegenwärtig nach Voreinstellung deaktiviert ist (da die gründlicheren Tests noch nicht abgeschlossen sind), aber in den meisten Fällen bereits funktionieren müsste. Dieses Feature kann mit der Anweisung
SET engine_condition_pushdown = Onaktiviert werden. Alternativ können Sie mysqld so laufen lassen, dass das Feature eingeschaltet wird, indem Sie den MySQL Server mit der Option--engine-condition-pushdownstarten.Ein Hauptvorteil dieser Änderung besteht darin, dass Anfragen parallel ausgeführt werden können. So laufen Anfragen auf nichtindizierten Spalten unter Umständen fünf- bis zehnmal schneller als zuvor, und dies mal der Anzahl der Datenknoten, da mehrere CPUs die Anfrage parallel bearbeiten können.
Mit dem Befehl
EXPLAINkönnen Sie ermitteln, wann Pushdown-Bedingungen verwendet werden. Siehe auch Abschnitt 7.2.1, „EXPLAIN-Syntax (Informationen über einSELECTerhalten)“.Weniger Platzbedarf
IndexMemory: In MySQL 5.1 belegt jeder Datensatz ungefähr 25 Byte Index Memory und jeder eindeutige Index 25 Byte pro Datensatz (und zusätzlich noch einigen Platz im Data Memory, da diese Datensätze in einer separaten Tabelle gespeichert werden). Das liegt daran, dass der Primärschlüssel nun nicht mehr im Index Memory gespeichert wird.Der Anfragen-Cache ist für MySQL Cluster aktiviert: Mehr über die Konfiguration und Nutzung des Anfragen-Caches erfahren Sie unter Abschnitt 5.14, „MySQL-Anfragen-Cache“.
Neue Optimierungen: Eine Optimierung verdient eine gesonderte Erwähnung: Nämlich die, dass nun in manchen Anfragen ein Batched Read Interface verwendet wird. Betrachten Sie zum Beispiel folgende Anfrage:
SELECT * FROM t1 WHERE
primary_keyIN (1,2,3,4,5,6,7,8,9,10);Diese Anfrage wird zwei- bis dreimal schneller bearbeitet als in den früheren Versionen von MySQL Cluster, da alle zehn Schlüssel-Lookups in einem einzigen Schwung statt immer nacheinander übersandt werden.
Obergrenze für einige Metadatenobjekte: In MySQL 5.1 kann jede Cluster-Datenbank bis zu 20.320 Metadatenobjekte enthalten, einschließlich Datenbanktabellen, Systemtabellen, Indizes und
BLOBs.
Das Folgende ist ein Zustandsbericht über die neuesten Commits im MySQL 5.1-Quellbaum. Bitte beachten Sie, dass alle Entwicklungen an 5.1 sich noch laufend ändern können.
Gegenwärtig werden vier wichtige neue Features für MySQL 5.1 entwickelt:
Integration von MySQL Cluster in die MySQL-Replikation: Dadurch wird es möglich, von jedem beliebigen MySQL Server im Cluster Updates zu veranlassen und dennoch weiterhin die MySQL-Replikation von einem der MySQL Server im Cluster erledigen zu lassen, wobei der Status auf der Slave-Seite immer mit dem Cluster konsistent bleibt, der als Master fungiert.
Unterstützung für festplattenbasierte Datensätze: Datensätze auf Platte werden künftig unterstützt. Indizierte Felder mit Primärschlüssel-Hash-Index müssen zwar weiterhin im RAM gespeichert werden, aber alle anderen Felder können auf der Festplatte liegen.
Datensätze variabler Länge: Eine
VARCHAR(255)-Spalte belegt zurzeit unabhängig von dem tatsächlichen Inhalt des Datensatzes immer 260 Byte. In MySQL 5.1 Cluster-Tabellen wird nur der Teil der Spalte gespeichert, der tatsächlich von Datensatzdaten belegt ist. Dadurch kann der Speicherplatzbedarf für solche Spalten in vielen Fällen um maximal das Fünffache schrumpfen.Benutzerdefinierte Partitionierung: Die Benutzer können nun Partitionen anhand von Spalten definieren, die Teil des Primärschlüssels sind. Der MySQL Server kann feststellen, ob es möglich ist, einige der Partitionen aus der
WHERE-Klausel auszuschließen. Eine Partitionierung anhand derKEY-,HASH-,RANGE- undLIST-Handler wird nun ebenso wie eine Teilpartitionierung möglich sein. Dieses Feature sollte auch für viele andere Handler und nicht nur fürNDB Clusterzur Verfügung stehen.
Zusätzlich arbeiten wir daran, das 8-Kbyte-Limit auch für
Zeilen in Cluster-Tabellen heraufzusetzen, die andere
Spaltentypen als BLOB oder
TEXT enthalten. Denn gegenwärtig sind die
Zeilen noch auf diese Größe festgelegt und die Seitengröße
beträgt 32.768 Byte (minus 128 Byte für den Zeilen-Header).
Wenn wir also mehr als 8 Kbyte pro Datensatz gestatten, würde
daher der übrige Platz (bis zu ungefähr 14.000 Byte) leer
bleiben. In MySQL 5.1 wollen wir diese Einschränkung
beseitigen, sodass nicht mehr der ganze Rest der Seite
verschwendet wird, wenn mehr als 8 Kbyte für eine Zeile
benötigt werden.
In diesem Abschnitt werden häufig gestellte Fragen über MySQL Cluster beantwortet.
Was ist „NDB“?
Dies steht für „Network DataBase“.
Was macht es für einen Unterschied, ob ich Cluster oder Replikation nutze?
Bei einer Replikation aktualisiert ein MySQL-Master-Server einen oder mehrere Slaves. Transaktionen werden nacheinander committet und eine langsame Transaktion kann dazu führen, dass der Slave hinter dem Master zurückbleibt. Das bedeutet: Wenn der Master abstürzt, kann es dazu kommen, dass der Slave die letzten paar Transaktionen nicht mitbekommen hat. Wird eine transaktionssichere Engine wie
InnoDBbenutzt, so wird eine Transaktion auf dem Slave entweder abgeschlossen oder gar nicht angewendet. Bei der Replikation ist jedoch nicht garantiert, dass alle Daten auf dem Master und dem Slave zu jedem Zeitpunkt konsistent sind. In MySQL Cluster hingegen sind immer alle Datenknoten synchron und eine Transaktion, die von irgendeinem Datenknoten committet wird, wird für alle Datenknoten committet. Wenn ein Datenknoten abstürzt, bleiben alle übrigen Datenknoten in einem konsistenten Zustand zurück.Kurz: Während die MySQL-Replikation standardmäßig asynchron ist, ist MySQL Cluster synchron.
Wir planen, eine (asynchrone) Replikation für Cluster in MySQL 5.1 einzuführen. Dazu gehört auch die Fähigkeit, sowohl zwischen zwei Clustern als auch zwischen einem geclusterten und einem nichtgeclusterten MySQL Server zu replizieren.
Benötige ich ein spezielles Netzwerk für Cluster? (Wie kommunizieren Computer in einem Cluster?)
MySQL Cluster ist für die Benutzung in einer Umgebung mit großer Bandbreite und über TCP/IP verbundene Computer ausgelegt. Die Leistung des Clusters hängt direkt von der Schnelligkeit der Verbindungen zwischen den Cluster-Computern ab. Die Mindestanforderung für die Konnektivität in einem Cluster ist ein typisches 100-Megabit-Ethernet-Netzwerk oder etwas Entsprechendes. Wir empfehlen Ihnen, nach Möglichkeit ein 1-Gigabit-Ethernet einzusetzen.
Das schnellere SCI-Protokoll wird ebenfalls unterstützt, benötigt jedoch eine spezielle Hardware. Weitere Informationen über SCI finden Sie unter Abschnitt 16.7, „Verwendung von Hochgeschwindigkeits-Interconnects mit MySQL Cluster“.
Wie viele Computer sind für einen Cluster erforderlich und warum?
Für einen benutzbaren Cluster sind mindestens drei Computer notwendig. Empfohlen werden jedoch mindestens vier: je einer für den Management- und den SQL-Knoten und zwei, die als Speicherknoten dienen. Zwei Datenknoten sind wegen der Redundanz ratsam und der Management-Knoten muss auf einem eigenen Computer laufen, um auch beim Absturz eines Datenknotens weiterhin die Arbitrator-Funktion aufrechterhalten zu können.
Was tun die verschiedenen Computer in einem Cluster?
Ein MySQL Cluster hat sowohl eine physikalische als auch eine logische Struktur, wobei die Computer die physikalischen Elemente sind. Die logischen oder funktionalen Elemente eines Clusters werden als Knoten bezeichnet und ein Computer, auf dem ein Cluster-Knoten läuft, wird Cluster-Host genannt. Im Idealfall gibt es einen Knoten pro Cluster-Host, allerdings können auf einem einzelnen Host auch mehrere Knoten laufen. Es gibt drei Knotentypen, von denen jeder im Cluster eine bestimmte Rolle spielt:
Management-Knoten (MGM-Knoten): Leistet Management-Dienste für den Cluster als Ganzes, darunter Hochfahren, Herunterfahren, Datensicherungen und Bereitstellung von Konfigurationsdaten für die anderen Knoten. Der Management-Knoten-Server ist in Form der Anwendung ndb_mgmd implementiert, und der Management-Client, der den MySQL Cluster über den MGM-Knoten kontrolliert, ist ndb_mgm.
Datenknoten: Speichert und repliziert Daten. Seine Funktionalität erhält der Datenknoten von einer Instanz des NDB-Datenknotenprozesses ndbd.
SQL-Knoten: Dieser ist einfach eine Instanz von MySQL Server (mysqld), die mit Unterstützung für die Speicher-Engine
NDB Clustergebaut und mit der Option --ndb-cluster gestartet wurde, welche die Engine aktiviert.
Mit welchen Betriebssystemen kann ich Cluster benutzen?
MySQL Cluster wird offiziell für Linux, Mac OS X und Solaris unterstützt. Wir arbeiten daran, Cluster auch auf anderen Plattformen zu ermöglichen (einschließlich Windows), und haben uns das Ziel gesetzt, MySQL Cluster irgendwann auf allen Plattformen zu unterstützen, auf denen auch MySQL selbst läuft.
Es könnte möglich sein, Cluster-Prozesse auch auf anderen Betriebssystemen auszuführen. Einige Anwender berichten, Cluster bereits erfolgreich auf FreeBSD betrieben zu haben. Allerdings können Cluster auf anderen als den hier erwähnten drei Betriebssystemen bestenfalls als Alpha-Software gelten. Ihre Zuverlässigkeit in einer Produktionsumgebung kann nicht garantiert werden und wird nicht von MySQL AB unterstützt.
Welche Hardwareanforderungen stellt MySQL Cluster?
Cluster müssten auf jeder Plattform laufen, für die NDB-fähige Binaries zur Verfügung stehen. Natürlich wird die Leistung mit schnelleren CPUs und größerem Arbeitsspeicher besser, und 64-Bit-CPUs sind schneller als 32-Bit-Prozessoren. Die als Datenknoten verwendeten Computer müssen genug Arbeitsspeicher haben, um den Teil der Datenbank zu speichern, der auf diesem Datenknoten liegt (weitere Informationen siehe Wie viel RAM brauche ich?). Die Knoten können über ein normales TCP/IP-Netzwerk mit Standardhardware kommunizieren. Für die SCI-Unterstützung ist spezielle Netzwerkhardware erforderlich.
Wie viel RAM brauche ich? Kann überhaupt Festplattenspeicher benutzt werden?
Zurzeit sind Cluster lediglich arbeitsspeicherresident, sodass alle Tabellendaten (einschließlich Indizes) im Arbeitsspeicher abgelegt werden. Wenn Ihre Daten 1 Gbyte Platz benötigen und Sie sie einmal im Cluster replizieren möchten, benötigen Sie dafür folglich 2 Gbyte Hauptspeicher. Hinzu kommt der Arbeitsspeicher, den das Betriebssystem und irgendwelche sonstigen Anwendungen belegen, die auf den Cluster-Computern laufen.
Die folgende Formel liefert eine grobe Schätzung des für jeden Datenknoten im Cluster benötigten Arbeitsspeicherbedarfs:
(SizeofDatabase × NumberOfReplicas × 1.1 ) / NumberOfDataNodes
Um den Speicherbedarf genauer zu berechnen, müssen Sie für jede Tabelle in der Cluster-Datenbank den pro Zeile erforderlichen Speicher ermitteln (Einzelheiten siehe Abschnitt 11.5, „Speicherbedarf von Spaltentypen“) und diesen Wert mit der Zeilenzahl multiplizieren. Außerdem müssen Sie die Spaltenindizes wie folgt mit einkalkulieren:
Jeder Primärschlüssel oder Hash-Index auf einer
NDBCluster-Tabelle benötigt 21–25 Byte pro Datensatz. Diese Indizes nutzen dasIndexMemory.Jeder geordnete Index belegt pro Datensatz 10 Byte Speicher im
DataMemory.Jeder Primärschlüssel oder eindeutige Schlüsselindex erzeugt auch einen geordneten Index, wenn er nicht mit
USING HASHangelegt wurde. Mit anderen Worten: Ein ohneUSING HASHangelegter Primärschlüssel oder eindeutiger Index auf einer Cluster-Tabelle belegt in MySQL 5.1 31–35 Byte Speicher pro Datensatz.Beachten Sie, dass Tabellenänderungen generell schneller laufen, wenn alle Primärschlüssel und eindeutigen Indizes auf MySQL Cluster-Tabellen mit
USING HASHangelegt werden, da dann weniger Arbeitsspeicher erforderlich ist (weil keine geordneten Indizes erzeugt werden) und auch die Belastung der CPU geringer ist (weil weniger Indizes gelesen und womöglich geändert werden müssen).
Sehr wichtig: Bitte denken Sie daran, dass jede MySQL Cluster-Tabelle einen Primärschlüssel haben muss. Die Speicher-Engine
NDBlegt automatisch einen Primärschlüssel an, wenn nicht bereits einer definiert wurde, und dieser Primärschlüssel wird ohneUSING HASHerzeugt.Es gibt kein einfaches Mittel, um genau festzustellen, wann wie viel Arbeitsspeicher von Cluster-Indizes belegt wird, aber wenn 80 % des verfügbaren
DataMemoryoderIndexMemoryvoll sind, wird eine Warnung in das Cluster-Log geschrieben. Weitere Warnungen gibt es, wenn 85 %, 90 % usw. erreicht werden.Oft erreichen uns Fragen von Anwendern, die berichten, dass der Ladeprozess beim Laden von Daten in eine Cluster-Datenbank vorzeitig mit einer Fehlermeldung wie dieser abbricht:
ERROR 1114: The table 'my_cluster_table' is full
Wenn dies geschieht, haben Sie höchstwahrscheinlich nicht genügend RAM für alle Datentabellen und Indizes einschließlich des von der Speicher-Engine
NDBgeforderten Primärschlüssels, der automatisch erzeugt wird, wenn er in der Tabellendefinition fehlt.Außerdem müssen Sie berücksichtigen, dass alle Datenknoten gleich viel RAM haben sollten, da in einem Cluster kein Datenknoten mehr Speicher übrig hat als der an Speicher ärmste Datenknoten des Clusters. Mit anderen Worten: Wenn drei Computer Cluster-Datenknoten hosten und zwei davon 3 Gbyte RAM für Cluster-Daten übrig haben, während dem dritten nur 1 Gbyte verbleibt, können alle drei Datenknoten nur noch 1 Gbyte Speicher für den Cluster verwenden.
Da MySQL Cluster mit TCP/IP arbeitet: Bedeutet dies, dass ich den Cluster im Internet betreiben und einen oder mehrere Knoten remote halten kann?
Es ist mehr als zweifelhaft, dass ein Cluster unter solchen Bedingungen noch eine zuverlässige Leistung bringen könnte, da MySQL Cluster unter der Grundannahme entworfen und implementiert wurde, dass der Cluster eine Hochgeschwindigkeitsverbindung wie in einem LAN mit 100 Mbps oder einem Gigabit-Ethernet (vorzugsweise Letzterem) nutzen kann. Die Leistung mit einer langsameren Verbindung werden wir weder testen noch irgendwie gewährleisten.
Außerdem ist es außerordentlich wichtig, immer daran zu denken, dass die Kommunikation zwischen Knoten in einem MySQL Cluster nicht sicher ist. Die Datenübermittlungen werden weder verschlüsselt noch durch irgendeinen anderen Schutzmechanismus abgesichert. Die sicherste Konfiguration für einen Cluster ist ein privates Netzwerk hinter einer Firewall, ohne direkten Zugriff von außerhalb auf irgendwelche Cluster-Daten oder Management-Knoten. (Für SQL-Knoten sollten Sie dieselben Vorkehrungen treffen wie für jede andere Instanz des MySQL Servers.)
Muss ich für Cluster eine neue Programmiersprache oder Datenbank-Abfragesprache lernen?
Nein. Für die Verwaltung und Konfiguration des Clusters selbst werden zwar einige spezielle Befehle benötigt, aber für die folgenden Operationen sind nur (My)SQL-Standardabfragen und Standardbefehle erforderlich:
Tabellen anlegen, ändern und löschen
Tabellendaten einfügen, ändern und löschen
Primärschlüssel oder eindeutige Indizes anlegen, ändern und löschen
SQL-Knoten (MySQL Server) konfigurieren und verwalten.
Wie kann ich herausfinden, was eine Fehlermeldung oder Warnung bedeutet, wenn ich Cluster benutze?
Dafür gibt es zwei Möglichkeiten:
Sie können im mysql-Client direkt nachdem Sie den Fehler oder die Warnung bekommen haben, SHOW ERRORS oder SHOW WARNINGS aufrufen. Fehler und Warnungen werden auch im MySQL Query Browser angezeigt.
Sie können an einem Prompt der System-Shell perror --ndb
error_codeausführen.
Ist MySQL Cluster transaktionssicher? Welche Isolationsebenen werden unterstützt?
Ja. Für Tabellen, die mit der Speicher-Engine
NDBangelegt wurden, werden Transaktionen unterstützt. In MySQL 5.1 kennen Cluster allerdings als einzige Ebene der TransaktionsisolationREAD COMMITTED.Welche Speicher-Engines unterstützt MySQL Cluster?
Clustering wird in MySQL nur von der Speicher-Engine
NDBunterstützt. Um eine Tabelle für Cluster-Knoten tauglich zu machen, muss sie also mitENGINE=NDB(oder dem ÄquivalentENGINE=NDBCLUSTER) angelegt werden.(Es ist möglich, Tabellen mit anderen Speicher-Engines wie etwa
MyISAModerInnoDBauf einem MySQL Server anzulegen, der für Clustering verwendet wird, doch diese Nicht-NDB-Tabellen können nicht an dem Cluster beteiligt sein.)Welche Versionen von MySQL unterstützen Cluster? Muss ich die Quellversionen kompilieren?
Cluster wird in allen MySQL-max-Binaries der Release-Serie 5.1 unterstützt, mit den im folgenden Absatz genannten Ausnahmen. Ob Ihr Server NDB unterstützt, können Sie mit
SHOW VARIABLES LIKE 'have_%'oderSHOW ENGINESherausfinden. (Mehr Informationen finden Sie unter Abschnitt 5.3, „mysqld-max, ein erweiterter mysqld-Server“.)Linux-Benutzer müssen wissen, dass
NDBnicht in den Standard-RPMs für MySQL Server enthalten ist. Es gibt auch separate RPM-Packages für die Speicher-Engine NDB und die zugehörigen Management- und anderen Tools. Downloadsites für diese RPMs sind im Abschnitt für NDB RPM-Downloads der MySQL 5.1-Downloadseite angegeben. (Früher musste man die-max-Binaries verwenden, die als.tar.gz-Archive geliefert wurden. Auch dies ist immer noch möglich, aber nicht mehr nötig; heute können Sie den RPM-Manager Ihrer Linux-Distribution nutzen, wenn Sie es möchten.) NDB-Unterstützung bekommen Sie auch, indem Sie die-max-Binaries von der Quelle kompilieren, doch bloß um MySQL Cluster-Unterstützung zu bekommen, ist das nicht erforderlich. Um die neueste Binary, RPM oder Quelldistribution der MySQL 5.1-Serie herunterzuladen, gehen Sie zu http://dev.mysql.com/downloads/mysql/5.1.html.Würde ich im Katastrophenfall, etwa wenn die ganze Stadt einen Stromausfall hat und zusätzlich meine unterbrechungsfreie Stromversorgung versagt, alle meine Daten verlieren?
Da alle committeten Transaktionen protokolliert werden, ist es zwar möglich, dass einige Daten in einem solchen Katastrophenfall verloren gehen könnten, aber der Verlust dürfte sich in Grenzen halten. Der Datenverlust kann zusätzlich begrenzt werden, indem Sie die Anzahl der Operationen pro Transaktion reduzieren. (Es ist immer schlecht, zu viele Operationen in einer einzigen Transaktion auszuführen.)
Kann man in einem Cluster
FULLTEXT-Indizes benutzen?FULLTEXT-Indizes werden zurzeit weder vonNDBnoch von irgendeiner anderen Speicher-Engine außerMyISAMunterstützt. Wir arbeiten daran, diese Fähigkeit in einem künftigen Release hinzuzufügen.Kann ich mehrere Knoten auf einem einzigen Computer laufen lassen?
Das ist möglich, aber nicht ratsam. Einer der Hauptgründe für ein Cluster ist die Redundanz. Um jedoch alle Vorteile der Redundanz zu gewährleisten, sollte jeder Knoten auf einem eigenen Computer laufen. Wenn Sie mehrere Knoten auf einem einzigen Computer betreiben und dieser abstürzt, verlieren Sie alle diese Knoten. Wenn man bedenkt, dass MySQL Cluster auf Standardhardware mit einem billigen (oder sogar kostenlosen) Betriebssystem laufen kann, dann lohnt es sich wohl, ein oder zwei zusätzliche Rechner anzuschaffen, um missionskritische Daten zu sichern. Überdies sind die Anforderungen an einen Cluster-Host, auf dem ein Management-Knoten läuft, minimal: Diese Aufgabe kann schon ein 200-MHz-Pentium bewältigen, wenn er genügend RAM für das Betriebssystem plus einen geringen Overhead für die ndb_mgmd- und ndb_mgm-Prozesse hat.
Kann ich einem Cluster Knoten hinzufügen, ohne ihn neu starten zu müssen?
Zurzeit noch nicht. Allerdings ist ein Neustart alles, was Sie tun müssen, um einem Cluster neue MGM- oder SQL-Knoten hinzuzufügen. Wenn Sie Datenknoten hinzufügen, liegen die Dinge etwas komplizierter; dafür sind folgende Schritte nötig:
Sie sichern alle Cluster-Daten.
Sie fahren den Cluster und alle Cluster-Knoten-Prozesse vollständig herunter.
Sie starten den Cluster mit der Startoption
--initialneu.Sie stellen alle Cluster-Daten aus den Sicherungsdateien wieder her.
In einer künftigen Release-Serie von MySQL Cluster hoffen wir, MySQL Cluster eine „heiße“ Rekonfigurationsfähigkeit implementieren zu können, um die Anforderungen an den Neustart des Clusters nach dem Hinzufügen neuer Knoten zu minimieren (wenn nicht gar zu eliminieren).
Muss ich irgendwelche Einschränkungen berücksichtigen, wenn ich Cluster benutze?
Für
NDB-Tabellen gelten in MySQL folgende Einschränkungen:Sie unterstützen nicht alle Zeichensätze und Kollationen.
Sie unterstützen keine
FULLTEXT-Indizes und Indexpräfixe. Nur vollständige Spalten können indiziert werden.Sie unterstützen keine raumbezogenen Datentypen. Siehe auch Kapitel 18, Raumbezogene Erweiterungen in MySQL.
Sie unterstützen nur vollständige Rollbacks von Transaktionen. Teilweise Rollbacks und Rollbacks zu Savepoints werden nicht unterstützt.
Pro Tabelle dürfen maximal 128 Attribute verwendet werden und die Attributnamen dürfen nicht länger als 31 Zeichen sein. Für jede Tabelle beträgt die Höchstlänge für den Tabellen- plus Datenbanknamen 122 Zeichen.
Eine Tabellenzeile darf maximal 8 Kbyte lang sein,
BLOBs nicht inbegriffen. Für die Zeilenzahl pro Tabelle gibt es keine festgesetzte Obergrenze. Die Größenbeschränkungen für Tabellen hängen von mehreren Faktoren ab, besonders von dem für jeden Datenknoten verfügbaren Arbeitsspeicher.Die
NDB-Engine unterstützt keine Fremdschlüssel-Constraints. Diese werden wie inMyISAMignoriert.Query-Caching wird nicht unterstützt.
Weitere Informationen über Beschränkungen in Clustern finden Sie unter Abschnitt 16.8, „Bekannte Beschränkungen von MySQL Cluster“.
Wie importiere ich eine vorhandene MySQL-Datenbank in einen Cluster?
Wie in jede andere Version von MySQL können Sie auch in MySQL Cluster Datenbanken importieren. Außer den im obigen Absatz erwähnten Beschränkungen gibt es nur eine einzige weitere Sonderbedingung: Alle Tabellen, die in den Cluster eingebracht werden sollen, müssen die Speicher-Engine
NDBverwenden. Das bedeutet, dass die Tabellen mitENGINE=NDBoderENGINE=NDBCLUSTERangelegt werden müssen. Es ist auch möglich, bestehende Tabellen, die andere Speicher-Engines nutzen, mitALTER TABLEinNDB Clusterzu konvertieren, aber dafür ist ein zusätzlicher Workaround notwendig. Einzelheiten siehe Abschnitt 16.8, „Bekannte Beschränkungen von MySQL Cluster“.Wie kommunizieren Cluster-Knoten?
Cluster-Knoten können über drei Protokolle miteinander kommunizieren: TCP/IP, SHM (Shared Memory) und SCI (Scalable Coherent Interface). Wo es zur Verfügung steht, wird nach Voreinstellung SHM für Knoten benutzt, die auf demselben Cluster-Host residieren. SCI ist ein sehr schnelles (1 Gigabit pro Sekunde und mehr) und hochverfügbares Protokoll, das beim Aufbau skalierbarer Mehrprozessorsysteme zum Einsatz kommt. Es erfordert spezielle Hardware und Treiber. Unter Abschnitt 16.7, „Verwendung von Hochgeschwindigkeits-Interconnects mit MySQL Cluster“, erfahren Sie mehr über SCI als Transportmechanismus in MySQL Cluster.
Was ist ein „Arbitrator“?
Wenn ein oder mehrere Cluster-Knoten abstürzen, ist es möglich, dass nicht mehr alle Cluster-Knoten einander „sehen“ können. Es kann sogar passieren, dass zwei Knotenmengen durch eine Netzwerkpartitionierung voneinander isoliert werden, die man auch als „Split Brain“-Szenario bezeichnet. Eine solche Situation ist nicht wünschenswert, da jede der beiden Knotenmengen versuchen würde, den gesamten Cluster darzustellen.
Wenn Cluster-Knoten abstürzen, gibt es zwei Möglichkeiten: Wenn mehr als 50 % der verbleibenden Knoten miteinander kommunizieren können, haben wir eine so genannte „Majority Rules“-Situation („die Mehrheit regiert“), und diese Knotenmenge wird dann als der Cluster betrachtet. Der Arbitrator kommt ins Spiel, wenn es einen Gleichstand zwischen den Knoten gibt: In solchen Fällen wird die Knotenmenge, zu welcher der Arbitrator gehört, als der Cluster betrachtet, und die anderen Knoten werden heruntergefahren.
Diese Darstellung ist etwas vereinfachend. Eine genauere Erkärung, die auch Knotengruppen berücksichtigt, folgt:
Wenn alle Knoten in mindestens einer Knotengruppe am Leben sind, entstehen keine Probleme mit Netzwerkpartitionierung, da kein einzelner Teil des Clusters einen funktionsfähigen Cluster bilden kann. Das eigentliche Problem entsteht, wenn in keiner Knotengruppe alle Knoten mehr am Leben sind. In diesem Fall wird eine Netzwerkpartitionierung, das so genannte „Split-Brain“-Szenario, möglich. Dann ist ein Arbitrator (engl. für „Schiedsrichter“) gefordert. Alle Cluster-Knoten betrachten denselben Knoten, normalerweise den Management-Knoten, als Arbitrator. Es ist jedoch möglich, stattdessen einen der MySQL Server im Cluster als Arbitrator zu konfigurieren. Der Arbitrator gestattet, dass die erste Knotenmenge mit ihm Kontakt aufnimmt, und fährt die andere Knotenmenge herunter. Die Wahl des Arbitrators wird durch den Konfigurationsparameter
ArbitrationRankfür MySQL Server- und Management-Server-Knoten gesteuert. (Einzelheiten siehe Abschnitt 16.4.4.4, „Festlegung des MySQL Cluster-Management-Servers“.) Beachten Sie außerdem, dass der Arbitrator an sich keine großen Anforderungen an den als Arbitrator ausgewählten Host stellt, er muss also nicht besonders schnell sein oder einen besonders großen Arbeitsspeicher haben, um für diese Aufgabe geeignet zu sein.Welche Datentypen unterstützt MySQL Cluster?
MySQL Cluster unterstützt alle üblichen MySQL-Datentypen, ausgenommen die raumbezogenen, die zur Spatial-Erweiterung von MySQL gehören. (Siehe Kapitel 18, Raumbezogene Erweiterungen in MySQL.) Darüber hinaus gibt es bei
NDB-Tabellen einige Abweichungen im Hinblick auf Indizes. Hinweis: MySQL Cluster-Tabellen (also Tabellen, die mitENGINE=NDBCLUSTERangelegt wurden) haben nur Zeilen mit fester Breite. Das bedeutet beispielsweise, dass ein Datensatz mit einerVARCHAR(255)-Spalte Speicher für 255 Zeichen belegt (wie Zeichensatz und die Kollation der Tabelle es erfordern), unabhängig davon, wie viele Zeichen tatsächlich in der Spalte gespeichert sind. Dieses Problem soll in einer künftigen Release-Serie von MySQL behoben werden.Mehr zu diesen Fragen lesen Sie unter Abschnitt 16.8, „Bekannte Beschränkungen von MySQL Cluster“.
Wie kann ich MySQL Cluster starten und anhalten?
Jeder Knoten im Cluster muss separat gestartet werden, und zwar in folgender Reihenfolge:
Sie starten den Management-Knoten mit dem Befehl ndb_mgmd.
Sie starten jeden Datenknoten mit dem Befehl ndbd.
Sie starten jeden MySQL Server (SQL-Knoten) mit dem Befehl mysqld_safe --user=mysql &.
Jeder dieser Befehle muss in der System-Shell des Computers ausgeführt werden, auf dem der betreffende Knoten ausgeführt wird. Ob der Cluster läuft, können Sie prüfen, indem Sie den MGM-Management-Client ndb_mgm auf dem Computer aufrufen, auf dem der MGM-Knoten läuft.
Was passiert mit den Cluster-Daten, wenn der Cluster heruntergefahren wird?
Die Daten, die in den Datenknoten des Clusters im Arbeitsspeicher liegen, werden auf die Platte geschrieben und beim nächsten Start des Clusters wieder in den Arbeitsspeicher geladen.
Um den Cluster herunterzufahren, geben Sie folgenden Befehl in die Shell des MGM-Knoten-Hosts ein:
shell>
ndb_mgm -e shutdownDas beendet geräuschlos ndb_mgm, ndb_mgm und alle ndbd-Prozesse. MySQL Server, die als SQL-Knoten eines Clusters laufen, können mit mysqladmin shutdown angehalten werden.
Weitere Informationen finden Sie unter Abschnitt 16.6.2, „Befehle des Management-Clients“, und Abschnitt 16.3.6, „Sicheres Herunterfahren und Neustarten“.
Ist es nützlich, mehr als einen Management-Knoten im Cluster zu haben?
Das kann als Ausfallsicherung hilfreich sein. Zwar wird der Cluster immer nur von einem MGM-Knoten gesteuert, aber es ist möglich, einen MGM als Primärknoten und andere als Ausfallsicherung zu konfigurieren, für den Fall, dass der Primär-MGM-Knoten abstürzt.
Kann ich in einem Cluster unterschiedliche Hardware und Betriebssysteme mixen?
Ja, aber nur wenn alle Computer und Betriebssysteme dieselbe "Endianness" haben (also entweder alle big-endian oder alle little-endian sind). Es ist auch möglich, auf verschiedenen Knoten verschiedene Releases von MySQL Cluster zu benutzen. Dies können wir jedoch nur im Rahmen einer laufenden Upgrade-Prozedur empfehlen.
Kann ich zwei Datenknoten auf einem einzigen Host betreiben? Oder zwei SQL-Knoten?
Ja, möglich wäre das schon. Wenn Sie mehrere Datenknoten haben, muss jeder Knoten ein anderes Data Directory benutzen. Wenn Sie mehrere SQL-Knoten auf derselben Maschine laufen lassen wollen, muss jede mysqld-Instanz einen anderen TCP/IP-Port benutzen.
Kann ich Hostnamen mit MySQL Cluster benutzen?
Ja, Sie können DNS und DHCP für Cluster-Hosts benutzen. Wenn Ihre Anwendung jedoch eine Verfügbarkeit von 99,999 Prozent benötigt, empfehlen wir feste IP-Adressen. Wenn Sie die Kommunikation zwischen Cluster-Hosts von Diensten wie DNS und DHCP abhängig machen, führen Sie damit zusätzliche Points of Failure ein. Je weniger es davon gibt, desto besser.
Die folgenden Begriffe sind wichtig für das Verständnis von MySQL Cluster oder haben in diesem Zusammenhang eine spezielle Bedeutung.
Cluster:
Im generischen Sinne ist ein Cluster eine Menge von Computern, die als Einheit funktionieren und zusammenarbeiten, um eine einzelne Aufgabe zu erfüllen.
NDB Cluster:Dies ist die Speicher-Engine, mit der MySQL eine auf mehrere Computer verteilte Implementierung von Datenspeicherung, -abruf und -verwaltung implementiert.
MySQL Cluster:
Eine Gruppe von Computern, die zusammenarbeiten und die Speicher-Engine
NDBverwenden, um eine verteilte MySQL-Datenbank in einer Share-Nothing-Architektur mit arbeitsspeicherresidenter Speicherung zu ermöglichen.Konfigurationsdateien:
Textdateien mit Anweisungen und Informationen über den Cluster, seine Hosts und seine Knoten. Diese werden beim Hochfahren des Clusters von dessen Management-Knoten gelesen. Einzelheiten siehe Abschnitt 16.4.4, „Konfigurationsdatei“.
Datensicherung (Backup):
Eine vollständige Kopie aller Cluster-Daten, Transaktionen und Logs, die auf der Festplatte oder einem anderen Langzeitspeicher abgelegt wird.
Wiederherstellung (Restore):
Den Cluster in den Zustand zurückversetzen, der in der Datensicherung gespeichert ist.
Checkpoint:
Im Allgemeinen: Wenn die Daten auf der Festplatte gespeichert werden, sagt man, dass ein Checkpoint erreicht wurde. Eher Cluster-spezifisch ausgedrückt, ein Checkpoint ist ein Zeitpunkt, zu dem alle committeten Transaktionen auf der Festplatte gespeichert werden. Im Hinblick auf die Speicher-Engine
NDBgibt es zwei Arten von Checkpoints, die zusammen gewährleisten, dass eine konsistente View der Cluster-Daten bewahrt bleibt:Lokaler Checkpoint (LCP):
Dieser Checkpoint ist für einen einzelnen Knoten spezifisch; allerdings können LCPs mehr oder weniger nebenläufig in allen Knoten im Cluster stattfinden. Bei einem LCP, der normalerweise alle paar Minuten eintritt, werden alle Daten eines Knotens auf der Platte gespeichert. Das genaue Intervall variiert ebenso wie die vom Knoten gespeicherte Datenmenge, der Grad der Cluster-Aktivität und andere Faktoren.
Globaler Checkpoint (GCP):
Ein GCP tritt alle paar Sekunden auf, wenn Transaktionen für alle Knoten synchronisiert werden und das Redo-Log auf die Festplatte geschrieben wird.
Cluster-Host:
Ein Computer, der einen Teil eines MySQL Clusters bildet. Ein Cluster hat sowohl eine physikalische als auch eine logische Struktur. Physikalisch besteht er aus einigen Computern, den so genannten Cluster-Hosts (oder einfach nur Hosts). Siehe auch Knoten und Knotengruppe weiter unten.
Knoten:
Eine logische oder funktionale Einheit eines MySQL Clusters, die machmal auch Cluster-Knoten genannt wird. Im Zusammenhang mit MySQL Cluster ist „Knoten“ eher ein Prozess als eine physikalische Komponente des Clusters. Für einen funktionierenden MySQL Cluster sind drei Arten von Knoten erforderlich:
Management(MGM)-Knoten:
Verwaltet die anderen Knoten im MySQL Cluster. Er liefert die Konfigurationsdaten an andere Knoten, startet und stoppt sie, kümmert sich um Netzwerkpartitionierung, legt Sicherungen an und stellt Daten aus Sicherungen wieder her usw.
SQL-Knoten (MySQL Server):
Instanzen des MySQL Servers, die als Frontend für Daten dienen, welche in den Datenknoten des Clusters liegen. Clients, die Daten speichern, abrufen oder ändern wollen, können auf einen SQL-Knoten wie auf jeden gewöhnlichen MySQL Server zugreifen, mit den üblichen Authentifizierungsmethoden und APIs. Die darunter liegende Verteilung der Daten auf Knotengruppen ist für Benutzer und Anwendungen nicht erkennbar. SQL-Knoten greifen auf die Datenbanken des Clusters als Ganzes zu, ohne sich um die Verteilung der Daten auf verschiedene Datenknoten oder Cluster-Hosts zu kümmern.
Datenknoten:
Diese Knoten speichern die tatsächlichen Daten. Tabellendatenfragmente werden in einer Menge von Knotengruppen gespeichert, wobei jede Knotengruppe eine andere Teilmenge der Tabellendaten speichert. Jeder Knoten, der zu einer Knotengruppe gehört, speichert eine Replik des Fragments, für das die Knotengruppe zuständig ist. Zurzeit kann ein einzelner Cluster insgesamt bis zu 48 Datenknoten unterstützen.
Mehrere Knoten können auf demselben Computer koexistieren. (Es ist sogar möglich, einen kompletten Cluster auf einer einzigen Maschine einzurichten, doch niemand würde dies in einer Produktionsumgebung tun.) Bitte merken Sie sich, dass sich der Begriff Host im Zusammenhang mit MySQL Cluster auf eine physikalische Komponente des Clusters bezieht, während mit Knoten eine logische oder funktionale Komponente (ein Prozess) gemeint ist.
Hinweis auf veraltete Begriffe: In älteren Versionen der Dokumentation zu MySQL Cluster wurden Datenknoten manchmal als „Datenbankknoten“, „DB-Knoten“ oder „Speicherknoten“ und SQL-Knoten als „Client-Knoten“ oder „API-Knoten“ bezeichnet. Diese ältere Terminologie wurde verworfen, um keine Verwirrung zu stiften, und sollte daher nicht mehr benutzt werden.
Knotengruppe:
Eine Menge von Datenknoten. Alle Datenknoten in einer Knotengruppe enthalten dieselben Daten (Fragmente) und alle Knoten einer Gruppe sollten auf verschiedenen Hosts residieren. Es ist möglich, zu steuern, welche Knoten zu welchen Gruppen gehören.
Knoten-Absturz:
MySQL Cluster ist nicht darauf angewiesen, dass jeder einzelne Knoten im Cluster funktioniert. Der Cluster kann auch dann weiterlaufen, wenn ein oder mehrere Knoten abstürzen. Wie viele abgestürzte Knoten ein Cluster im Einzelfall verträgt, hängt von der Anzahl der Knoten und der Konfiguration des Clusters ab.
Knoten-Neustart:
Der Prozess, einen abgestürzten Knoten wieder ans Laufen zu bringen.
Initialer Knoten-Neustart:
Der Prozess, einen Cluster-Knoten zu starten, dessen Dateisystem entfernt wurde. Dies wird manchmal bei Softwareupgrades oder unter anderen Sonderbedingungen getan.
System-Crash (oder Systemabsturz):
Dieser kann auftreten, wenn so viele Cluster-Knoten abgestürzt sind, dass der konsistente Zustand des Clusters nicht mehr garantiert werden kann.
System-Neustart:
Der Neustart eines Clusters samt Reinitialisierung seines Zustands aus den Festplatten-Logs und Checkpoints. Ist nach einem geplanten oder außerplanmäßigen Shutdown des Clusters erforderlich.
Fragment:
Ein Teil einer Datenbanktabelle. In der Speicher-Engine
NDBwird eine Tabelle in Fragmente zerlegt und so gespeichert. Ein Fragment wird manchmal auch „Partition“ genannt, doch „Fragment“ ist der bessere Begriff. Tabellen werden in MySQL Cluster fragmentiert, um die Lastverteilung zwischen Computern und Knoten zu erleichtern.Replik:
Unter der Speicher-Engine
NDBhat jedes Tabellenfragment eine Reihe von Replikas, die aus Redundanzgründen auf anderen Datenknoten gespeichert werden. Gegenwärtig kann es bis zu vier Replikas pro Fragment geben.Transporter:
Ein Protokoll für die Datenübermittlung zwischen Knoten. MySQL Cluster unterstützt zurzeit vier verschiedene Arten von Transporter-Verbindungen:
TCP/IP
Dies ist natürlich das vertraute Netzwerkprotokoll, das auch die Grundlage von HTTP, FTP (usw.) im Internet bildet. TCP/IP kann sowohl für lokale als auch für Remote-Verbindungen eingesetzt werden.
SCI
Scalable Coherent Interface ist ein Hochgeschwindigkeitsprotokoll, das zur Erstellung von Mehrprozessorsystemen und Anwendungen für die Parallelverarbeitung benutzt wird. Die Verwendung von SCI mit MySQL Cluster erfordert spezielle Hardware, wie in Abschnitt 16.7.1, „Konfiguration von MySQL Cluster für SCI Sockets“, beschrieben. Eine grundlegende Einführung in SCI finden Sie unter http://www.dolphinics.com/corporate/scitech.html.
SHM
Shared memory-Segmente wie bei Unix. Wenn SHM unterstützt wird, wird es automatisch für die Verbindung von Knoten auf demselben Host verwendet. Wenn Sie mehr über dieses Thema erfahren möchten, lesen Sie am besten auf der Unix-Manpage für
shmop(2)nach.
Hinweis: Der Cluster-Transporter ist für den Cluster intern. Anwendungen, die MySQL Cluster nutzen, kommunizieren mit SQL-Knoten wie mit jeder anderen Version von MySQL Server (über TCP/IP oder mittels Unix-Socketdateien oder der Named Pipes von Windows). Über die Standardclient-APIs von MySQL können Anfragen gesandt und Antworten abgerufen werden.
NDB:Die Abkürzung für Network Database, also die Speicher-Engine, mit der MySQL Cluster eingeschaltet wird. Diese Speicher-Engine unterstützt alle üblichen MySQL-Datentypen und SQL-Anweisungen und ist ACID-fähig. Außerdem bietet sie volle Transaktionsunterstützung (Commits und Rollbacks).
Share-Nothing-Architektur:
Die ideale Architektur für einen MySQL Cluster. In einer richtigen Share-Nothing-Umgebung läuft jeder Knoten auf einem separaten Host. Das hat den Vorteil, dass ein einzelner Host oder Knoten kein Single Point of Failure oder Leistungsengpass für das Gesamtsystem sein kann.
Speicherresident:
Alle Daten, die in den Datenknoten gespeichert sind, hält der Hostcomputer dieses Knotens im Arbeitsspeicher. Für jeden Datenknoten im Cluster muss daher RAM in der Größenordnung Datenbankgröße mal Anzahl Replikas geteilt durch Anzahl der Datenknoten vorgehalten werden. Wenn also die Datenbank 1 Gbyte belegt und Sie den Cluster mit vier Replikas und acht Datenknoten einrichten möchten, ist pro Knoten mindestens 500 Mbyte Arbeitsspeicher erforderlich. Beachten Sie, dass dazu noch der Speicherbedarf für das Betriebssystem und die anderen Anwendungen kommt, die vielleicht auf dem Host laufen.
Tabelle:
Wie es bei relationalen Datenbanken üblich ist, ist eine „Tabelle“ eine Menge identisch strukturierter Datensätze. In MySQL Cluster wird eine Datenbanktabelle auf einem Datenknoten in Form einer Reihe von Fragmenten gespeichert, wobei jedes Fragment auf anderen Datenknoten repliziert wird. Die Menge der Datenknoten, welche dieselben Fragmente replizieren, nennt man Knotengruppe.
Cluster-Programme:
Kommandozeilenprogramme, die zum Ausführen, Konfigurieren und Administrieren von MySQL Cluster erforderlich sind. Hierzu gehören beide Server-Daemons:
ndbd:
Der Datenknoten-Daemon (führt einen Datenknoten-Prozess aus)
ndb_mgmd:
Der Management-Server-Daemon (führt einen Management-Server-Prozess aus)
und Clientprogramme:
ndb_mgm:
Der Management-Client (stellt die Schnittstelle zur Ausführung von Management-Befehlen zur Verfügung)
ndb_waiter:
Prüft den Status aller Knoten in einem Cluster
ndb_restore:
Stellt Cluster-Daten aus einer Datensicherung wieder her
Mehr über diese Programme und ihre Verwendung erfahren Sie unter Abschnitt 16.5, „Prozessverwaltung in MySQL Cluster“.
Ereignislog:
MySQL Cluster protokolliert Ereignisse nach Kategorie (Starten, Herunterfahren, Fehler, Checkpoints usw.), Priorität und Ernsthaftigkeit. Eine vollständige Liste aller protokollierungsfähigen Ereignisse finden Sie unter Abschnitt 16.6.3, „Ereignisberichte, die MySQL Cluster erzeugt“. Es gibt zwei Arten von Ereignislogs:
Cluster-Log:
Zeichnet alle gewünschten protokollierbaren Ereignisse für den Cluster als Ganzes auf.
Knoten-Log:
Ein separates Log, das für jeden einzelnen Knoten gepflegt wird.
Unter normalen Umständen ist es notwendig und hinreichend, nur das Cluster-Log zu pflegen und zu untersuchen. In die Knoten-Logs schauen Sie nur bei der Anwendungsentwicklung und beim Debuggen hinein.