Inhaltsverzeichnis
- 15.1. Einführung
- 15.2. Überblick
- 15.3. Quelldateien für Speicher-Engines erstellen
- 15.4. Erstellung des
Handlerton - 15.5. Die Erzeugung von Handlern
- 15.6. Definiton von Dateierweiterungen
- 15.7. Tabellen anlegen
- 15.8. Tabellen öffnen
- 15.9. Einfaches Tabellenscanning implementieren
- 15.10. Tabellen schließen
- 15.11.
INSERT-Unterstützung für Speicher-Engines - 15.12.
UPDATE-Unterstützung für Speicher-Engines - 15.13.
DELETE-Unterstützung für Speicher-Engines - 15.14. Unterstützung für nichtsequenzielle Leseoperationen
- 15.15. Unterstützung für Indizes
- 15.15.1. Überblick über Indizes
- 15.15.2. Indexinformationen während
CREATE TABLE-Operationen erhalten - 15.15.3. Erzeugen von Indexschlüsseln
- 15.15.4. Schlüsselinformationen parsen
- 15.15.5. Indexinformationen an den Optimierer liefern
- 15.15.6. Nutzung des Indexes vorbereiten mit
index_init() - 15.15.7. Aufräumen mit
index_end() - 15.15.8. Implementierung der Funktion
index_read() - 15.15.9. Implementierung der Funktion
index_read_idx() - 15.15.10. Implementierung der Funktion
index_next() - 15.15.11. Implementierung der Funktion
index_prev() - 15.15.12. Implementierung der Funktion
index_first() - 15.15.13. Implementierung der Funktion
index_last()
- 15.16. Unterstützung für Transaktionen
- 15.17. Die API-Referenz
- 15.17.1. bas_ext
- 15.17.2. close
- 15.17.3. create
- 15.17.4. delete_row
- 15.17.5. delete_table
- 15.17.6. external_lock
- 15.17.7. extra
- 15.17.8. index_end
- 15.17.9. index_first
- 15.17.10. index_init
- 15.17.11. index_last
- 15.17.12. index_next
- 15.17.13. index_prev
- 15.17.14. index_read_idx
- 15.17.15. index_read
- 15.17.16. info
- 15.17.17. open
- 15.17.18. position
- 15.17.19. records_in_range
- 15.17.20. rnd_init
- 15.17.21. rnd_next
- 15.17.22. rnd_pos
- 15.17.23. start_stmt
- 15.17.24. store_lock
- 15.17.25. update_row
- 15.17.26. write_row
Mit MySQL 5.1 hat die Firma MySQL AB eine Architektur für eine Pluggable Storage Engine eingeführt. Dadurch ist es jetzt möglich, neue Speicher-Engines zu erstellen und einem laufenden MySQL Server hinzuzufügen, ohne den Server selbst neu kompilieren zu müssen.
Durch diese Architektur wird es leichter, neue Speicher-Engines für MySQL zu entwickeln und einzusetzen.
Dieses Kapitel soll Ihnen als Leitfaden dienen und bei der Entwicklung einer Speicher-Engine für die neue Pluggable Storage Engine-Architektur helfen.
Ein spezielles Forum zu Speicher-Engines finden Sie unter http://forums.mysql.com/list.php?94.
Der MySQL Server ist modular aufgebaut:
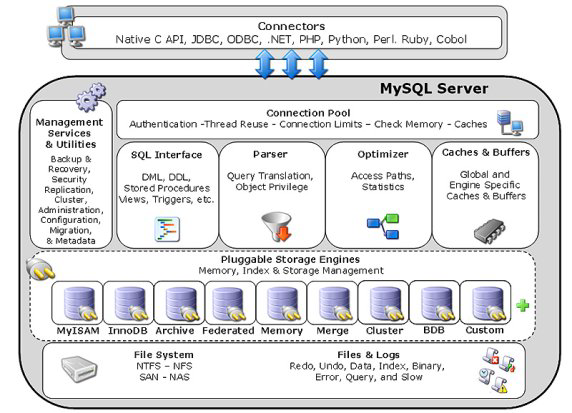
Die Speicher-Engines übernehmen die Datenspeicherung und die Indexverwaltung für MySQL. Der MySQL Server kommuniziert mit den Speicher-Engines über eine klar definierte API.
Jede Speicher-Engine ist eine Klasse und jede Instanz dieser
Klasse kommuniziert mit dem MySQL Server über ein spezielles
Handler-Interface.
Für jeden Thread, der mit einer bestimmten Tabelle arbeiten muss, wird ein Handler angelegt. Zum Beispiel: Wenn drei Verbindungen alle mit derselben Tabelle zu arbeiten beginnen, müssen drei Handler-Instanzen erzeugt werden.
Sobald eine Handler-Instanz erzeugt wurde, erteilt der MySQL Server dem Handler Befehle, damit dieser Datenspeicherungs- und Abrufoperationen ausführt, wie beispielsweise eine Tabelle öffnen, Datensätze ändern und Indizes verwalten.
Selbst erstellte Speicher-Engines können progressiv aufgebaut
werden: So könnte ein Entwickler mit einer nur-lesenden Engine
beginnen und später Unterstützung für
INSERT-, UPDATE- und
DELETE-Operationen hinzufügen, um noch ein
wenig später Indizierung, Transaktionen und andere
fortgeschrittene Operationen zu implementieren.
Der einfachste Weg zur Implementierung einer neuen Speicher-Engine
besteht darin, die EXAMPLE-Engine zu kopieren
und zu modifizieren. Die Dateien
ha_example.cc und
ha_example.h liegen im Verzeichnis
storage/example des MySQL 5.1-Quellbaums. Wie
Sie an den Quellbaum von MySQL 5.1 gelangen, erfahren Sie unter
Abschnitt 2.8.3, „Installation vom Entwicklungs-Source-Tree“.
Beim Kopieren der Dateien ändern Sie deren Namen von
ha_example.cc und
ha_example.h in etwas für Ihre Speicher-Engine
Passenderes ab, wie etwa ha_foo.cc und
ha_foo.h.
Nach dem Kopieren und Umbenennen der Dateien müssen Sie
EXAMPLE und example jeweils
durch den Namen Ihrer Speicher-Engine ersetzen. Wenn Sie mit
sed vertraut sind, können diese Schritte
automatisch ausgeführt werden (in diesem Beispiel lautet der Name
der Speicher-Engine „FOO“):
sed s/EXAMPLE/FOO/g ha_example.h | sed s/example/foo/g ha_foo.h sed s/EXAMPLE/FOO/g ha_example.cc | sed s/example/foo/g ha_foo.cc
Der Handlerton (eine Abkürzung für
„Handler Singleton“) definiert die Speicher-Engine
und enthält Funktionszeiger auf diejenigen Funktionen, die für
die Speicher-Engine als Ganzes gelten, im Gegensatz zu jenen
Funktionen, die auf Tabellenebene arbeiten. Dazu gehören
beispielsweise die Transaktionsfunktionen für Commits und
Rollbacks.
Hier sehen Sie ein Beispiel aus der Speicher-Engine
EXAMPLE.
handlerton example_hton= {
"EXAMPLE",
SHOW_OPTION_YES,
"Example storage engine",
DB_TYPE_EXAMPLE_DB,
NULL, /* Initialisierung */
0, /* Slot */
0, /* Savepoint-Größe */
NULL, /* close_connection */
NULL, /* Savepoint */
NULL, /* Rollback zum Savepoint */
NULL, /* Savepoint freigeben */
NULL, /* Commit */
NULL, /* Rollback */
NULL, /* Prepare */
NULL, /* Recover */
NULL, /* commit_by_xid */
NULL, /* rollback_by_xid */
NULL, /* create_cursor_read_view */
NULL, /* set_cursor_read_view */
NULL, /* close_cursor_read_view */
example_create_handler, /* Neuen Handler anlegen */
NULL, /* Eine Datenbank löschen */
NULL, /* Panik-Aufruf */
NULL, /* Temporäre Latches freigeben */
NULL, /* Statistik aktualisieren */
NULL, /* Konsistenten Snapshot starten */
NULL, /* Logs auf die Platte schreiben */
NULL, /* Status anzeigen */
NULL, /* Replication Report Sent Binlog */
HTON_CAN_RECREATE
};
Es folgt die Definition des Handlerton aus
handler.h:
typedef struct
{
const char *name;
SHOW_COMP_OPTION state;
const char *comment;
enum db_type db_type;
bool (*init)();
uint slot;
uint savepoint_offset;
int (*close_connection)(THD *thd);
int (*savepoint_set)(THD *thd, void *sv);
int (*savepoint_rollback)(THD *thd, void *sv);
int (*savepoint_release)(THD *thd, void *sv);
int (*commit)(THD *thd, bool all);
int (*rollback)(THD *thd, bool all);
int (*prepare)(THD *thd, bool all);
int (*recover)(XID *xid_list, uint len);
int (*commit_by_xid)(XID *xid);
int (*rollback_by_xid)(XID *xid);
void *(*create_cursor_read_view)();
void (*set_cursor_read_view)(void *);
void (*close_cursor_read_view)(void *);
handler *(*create)(TABLE *table);
void (*drop_database)(char* path);
int (*panic)(enum ha_panic_function flag);
int (*release_temporary_latches)(THD *thd);
int (*update_statistics)();
int (*start_consistent_snapshot)(THD *thd);
bool (*flush_logs)();
bool (*show_status)(THD *thd, stat_print_fn *print, enum ha_stat_type stat);
int (*repl_report_sent_binlog)(THD *thd, char *log_file_name, my_off_t end_offset);
uint32 flags;
} handlerton;
Es gibt insgesamt 30 Handlerton-Elemente, von denen aber nur
wenige obligatorisch sind (insbesondere die ersten vier Elemente
und die create()-Funktion).
Der Name der Speicher-Engine. Dieser Name wird beim Anlegen von Tabellen verwendet (
CREATE TABLE ... ENGINE =).FOO;Der Wert, der im
Status-Feld angezeigt wird, wenn ein Benutzer den BefehlSHOW STORAGE ENGINESeingibt.Der Kommentar zur Speicher-Engine, eine Beschreibung, die durch den Befehl
SHOW STORAGE ENGINESangezeigt wird.Ein Integer, der die Speicher-Engine im MySQL Server eindeutig bezeichnet. Die von den eingebauten Speicher-Engines benutzten Konstanten werden in der Datei
handler.hdefiniert. Selbst erstellte Engines solltenDB_TYPE_CUSTOMverwenden.Ein Funktionszeiger auf die Initialisierungsfunktion der Speicher-Engine. Diese Funktion wird nur ein einziges Mal beim Starten des Servers aufgerufen, damit die Speicher-Engine-Klasse vor der Instanziierung der Handler die notwendigen Aufräumarbeiten erledigen kann.
Der Slot. Jede Speicher-Engine hat ihren eigenen Speicherbereich (in Wirklichkeit ein Zeiger) im
thdzur Speicherung von Verbindungsdaten für jede Verbindung. Angesprochen wird er mitthd->ha_data[. Die Slot-Nummer wird von MySQL nach dem Aufruf vonfoo_hton.slot]foo_init()thdfinden Sie unter Abschnitt 15.16.3, „Implementierung von ROLLBACK“.Der Savepoint-Offset. Um Daten pro Savepoint speichern zu können, besitzt die Speicher-Engine einen Speicherbereich in der angeforderten Größe (
0, wenn kein Savepoint-Speicher notwendig ist).Der Savepoint-Offset muss als fester Wert mit der Größe des benötigten Speichers initialisiert werden, um Daten pro Savepoint speichern zu können. Nach
foo_initMehr zum Thema unter Abschnitt 15.16.5.1, „Den Savepoint-Offset angeben“.
Transaktionssichere Speicher-Engines bereinigen den ihrem Slot zugewiesenen Speicher.
Ein Funktionszeiger auf die Handler-Funktion
savepoint_set(). Dieser wird genutzt, um einen Savepoint anzulegen und in dem entsprechend großen zugewiesenen Arbeitsspeicherbereich abzulegen.Mehr zum Thema unter Abschnitt 15.16.5.2, „Implementierung der Funktion
savepoint_set“.Ein Funktionszeiger auf die Handler-Funktion
rollback_to_savepoint(). Dieser wird verwendet, um während einer Transaktion zu einem Savepoint zurückzukehren. Er wird nur für Speicher-Engines angelegt, die Savepoints unterstützen.Mehr zum Thema unter Abschnitt 15.16.5.3, „Implementierung der Funktion
savepoint_rollback()“.Ein Funktionszeiger auf die Handler-Funktion
release_savepoint(). Er wird verwendet, um die Ressourcen eines Savepoints während einer Transaktion freizugeben. Der Zeiger wird optional für Speicher-Engines, die Savepoints unterstützen, angelegt.Mehr zum Thema unter Abschnitt 15.16.5.4, „Implementierung der Funktion
savepoint_release()“.Ein Funktionszeiger auf die Handler-Funktion
commit(). Wird verwendet, um eine Transaktion festzuschreiben. Er wird nur für Speicher-Engines angelegt, die Savepoints unterstützen.Mehr zum Thema unter Abschnitt 15.16.4, „Implementierung von COMMIT“.
Ein Funktionszeiger auf die Handler-Funktion
rollback(). Wird verwendet, um eine Transaktion zurückzurollen. Er wird nur für Speicher-Engines angelegt, die Savepoints unterstützen.Mehr zum Thema unter Abschnitt 15.16.3, „Implementierung von ROLLBACK“.
Erforderlich für transaktionssichere XA-Speicher-Engines. Bereitet eine Transaktion auf das Commit vor.
Erforderlich für transaktionssichere XA-Speicher-Engines. Gibt eine Liste von Transaktionen zurück, die sich im vorbereiteten Zustand befinden.
Erforderlich für transaktionssichere XA-Speicher-Engines. Schreibt die Transaktion XID fest.
Erforderlich für transaktionssichere XA-Speicher-Engines. Rollt die Transaktion XID zurück.
Wird beim Anlegen eines Cursors aufgerufen, damit die Speicher-Engine eine konsistente Read-View erzeugen kann.
Wird aufgerufen, um auf eine bestimmte konsistente Read-View umzustellen.
Wird aufgerufen, um eine bestimmte Read-View zu schließen.
OBLIGATORISCH . Erzeugt eine Handler-Instanz und gibt sie zurück.
Mehr zum Thema unter Abschnitt 15.5, „Die Erzeugung von Handlern“.
Wird verwendet, wenn die Speicher-Engine beim Löschen eines Schemas besondere Maßnahmen ergreifen muss (wie zum Beispiel eine Speicher-Engine, die Tablespaces verwendet).
Bereinigungsfunktion, die nach dem Herunterfahren oder Abstürzen eines Servers aufgerufen wird.
InnoDB-spezifische Funktion.InnoDB-spezifische Funktion, die beim Start vonSHOW ENGINE InnoDB STATUSaufgerufen wird.Funktion, die aufgerufen wird, um einen konsistenten Read zu beginnen.
Wird aufgerufen, um anzuzeigen, dass die Logs auf einem zuverlässigen Speichermedium gespeichert werden sollen.
Liefert für Menschen lesbare Statusinformationen über die Speicher-Engine für
SHOW ENGINE.fooSTATUSInnoDB-spezifische Funktion, die zur Replikation verwendet wird.Handlerton-Flags, welche die Fähigkeiten der Speicher-Engine anzeigen. Die möglichen Werte sind in
sql/handler.hdefiniert und werden hier noch einmal aufgeführt:#define HTON_NO_FLAGS 0 #define HTON_CLOSE_CURSORS_AT_COMMIT (1 << 0) #define HTON_ALTER_NOT_SUPPORTED (1 << 1) #define HTON_CAN_RECREATE (1 << 2) #define HTON_FLUSH_AFTER_RENAME (1 << 3) #define HTON_NOT_USER_SELECTABLE (1 << 4)
HTON_ALTER_NOT_SUPPORTEDzeigt an, dass die Speicher-Engine keineALTER TABLE-Anweisungen annehmen kann. DieFEDERATED-Speicher-Engine ist ein Beispiel dafür.HTON_FLUSH_AFTER_RENAMEzeigt an, dassFLUSH LOGSnach der Umbenennung einer Tabelle aufgerufen werden muss.HTON_NOT_USER_SELECTABLEbedeutet, dass die Speicher-Engine nicht angezeigt werden darf, wenn ein BenutzerSHOW STORAGE ENGINESaufruft. Wird für System-Speicher-Engines wie zum Beispiel die Dummy-Engine für Binärlogs verwendet.
Als Erstes muss die Speicher-Engine den Methodenaufruf zur Erzeugung einer neuen Handler-Instanz unterstützen.
Vor dem Handlerton muss in der Quelldatei der
Speicher-Engine ein Funktions-Header für die
Instanziierungsfunktion definiert werden. Hier ist ein Beispiel
aus der CSV-Engine:
static handler* tina_create_handler(TABLE *table);
Wie Sie sehen, nimmt die Funktion einen Zeiger auf die Tabelle entgegen, welche der Handler verwalten soll, und liefert das Handler-Objekt zurück.
Wenn der Funktions-Header definiert ist, wird die Funktion durch
einen Funktionszeiger im
create()-handlerton-Element
angesprochen, um anzuzeigen, dass sie für die Erzeugung neuer
Handler-Instanzen zuständig ist.
Das folgende Beispiel zeigt die Instanziierungsfunktion der
Speicher-Engine MyISAM:
static handler *myisam_create_handler(TABLE *table)
{
return new ha_myisam(table);
}
Dieser Aufruf arbeitet mit dem Konstruktor der Speicher-Engine.
Das folgende Beispiel stammt von der Storage-Engine
FEDERATED:
ha_federated::ha_federated(TABLE *table_arg)
:handler(&federated_hton, table_arg),
mysql(0), stored_result(0), scan_flag(0),
ref_length(sizeof(MYSQL_ROW_OFFSET)), current_position(0)
{}
Und hier ist ein weiteres Beispiel mit der Storage-Engine
EXAMPLE:
ha_example::ha_example(TABLE *table_arg)
:handler(&example_hton, table_arg)
{}
Die zusätzlichen Elemente im
FEDERATED-Beispiel sind
Handler-Initialisierungen. Die erforderliche
Minimalimplementierung ist die
handler()-Initialisierung aus dem
EXAMPLE-Beispiel.
Die Speicher-Engines sind notwendig, damit der MySQL Server eine Liste von Erweiterungen bekommt, die von der betreffenden Engine für eine gegebene Tabelle sowie ihre Daten und Indizes benutzt werden können.
Erweiterungen werden in Form eines mit Null endenden String-Arrays
erwartet. Das folgende Array wird von der
CSV-Engine verwendet:
static const char *ha_tina_exts[] = {
".CSV",
NullS
};
Dieses Array wird zurückgegeben, wenn die Funktion
bas_ext()
aufgerufen wird:
const char **ha_tina::bas_ext() const
{
return ha_tina_exts;
}
Wenn Sie MySQL über die verwendeten Erweiterungen informieren,
müssen Sie keine DROP TABLE-Funktionalität
implementieren. Der MySQL Server nimmt Ihnen dies ab, indem er die
Tabelle schließt und alle Dateien mit den von Ihnen angegebenen
Erweiterungen löscht.
Wenn Sie einen Handler erzeugt haben, werden Sie normalerweise als Nächstes eine Tabelle anlegen.
Hierzu muss Ihre Speicher-Engine die virtuelle Funktion
create()
implementieren:
virtual int create(const char *name, TABLE *form, HA_CREATE_INFO *info)=0;
Diese Funktion sollte alle notwendigen Dateien erzeugen, muss jedoch nicht die Tabelle öffnen. Darum wird sich später der MySQL Server kümmern.
Der Parameter *name ist der Tabellenname und
der Parameter *form ist eine
TABLE-Struktur, welche die Tabelle definiert
und den Inhalt der zuvor bereits vom MySQL Server angelegten
tablename.frmtablename.frm
Der Parameter *info ist eine Struktur, die
Informationen über die CREATE TABLE-Anweisung
enthält, mit welcher die Tabelle angelegt wurde. Diese in
handler.h definierte Struktur geben wir hier
für Sie wieder:
typedef struct st_ha_create_information
{
CHARSET_INFO *table_charset, *default_table_charset;
LEX_STRING connect_string;
const char *comment,*password;
const char *data_file_name, *index_file_name;
const char *alias;
ulonglong max_rows,min_rows;
ulonglong auto_increment_value;
ulong table_options;
ulong avg_row_length;
ulong raid_chunksize;
ulong used_fields;
SQL_LIST merge_list;
enum db_type db_type;
enum row_type row_type;
uint null_bits; /* NULL-Bits am Anfang des Datensatzes */
uint options; /* OR von HA_CREATE_-Optionen */
uint raid_type,raid_chunks;
uint merge_insert_method;
uint extra_size; /* Länge des zusätzlichen Datensegments */
bool table_existed; /* 1 in create, falls Tabelle bereits vorhanden */
bool frm_only; /* 1, wenn kein ha_create_table() */
bool varchar; /* 1, wenn die Tabelle eine VARCHAR-Spalte hat */
} HA_CREATE_INFO;
Eine einfache Speicher-Engine kann den Inhalt von
*form and *info ignorieren,
denn im Grunde genügt es, die von der Speicher-Engine benutzten
Datendateien anzulegen und gegebenenfalls zu initialisieren
(vorausgesetzt, die Speicher-Engine arbeitet mit Dateien).
Das folgende Beispiel zeigt die Implementierung der
Speicher-Engine CSV:
int ha_tina::create(const char *name, TABLE *table_arg,
HA_CREATE_INFO *create_info)
{
char name_buff[FN_REFLEN];
File create_file;
DBUG_ENTER("ha_tina::create");
if ((create_file= my_create(fn_format(name_buff, name, "", ".CSV",
MY_REPLACE_EXT|MY_UNPACK_FILENAME),0,
O_RDWR | O_TRUNC,MYF(MY_WME))) < 0)
DBUG_RETURN(-1);
my_close(create_file,MYF(0));
DBUG_RETURN(0);
}
Im obigen Beispiel kümmert sich die CSV-Engine
gar nicht um die *table_arg- oder
*create_info-Parameter, sondern legt einfach
die erforderlichen Datendateien an, schließt sie wieder und kehrt
zurück.
Die Funktionen my_create und
my_close sind Hilfsfunktionen. Ihre Definition
steht in src/include/my_sys.h.
Ehe auf der Tabelle irgendwelche Lese- oder Schreiboperationen ausgeführt werden, ruft der MySQL Server die Methode handler::open() auf, um die Datendateien und (sofern vorhanden) die Indexdateien der Tabelle zu öffnen.
int open(const char *name, int mode, int test_if_locked);
Der erste Parameter ist der Name der zu öffnenden Tabelle und der
zweite legt fest, welche Datei geöffnet oder welche Operation
ausgeführt werden soll. Die Werte sind in
handler.h definiert und werden hier noch
einmal wiedergegeben:
O_RDONLY - Mit nur-lesendem Zugriff öffnen O_RDWR - Mit Lese-/Schreibzugriff öffnen
Die letzte Option legt fest, ob der Handler auf eine Tabellensperre achten soll, bevor er die Tabelle öffnet. Folgende Möglichkeiten stehen zur Verfügung:
#define HA_OPEN_ABORT_IF_LOCKED 0 /* der Default */ #define HA_OPEN_WAIT_IF_LOCKED 1 #define HA_OPEN_IGNORE_IF_LOCKED 2 #define HA_OPEN_TMP_TABLE 4 /* es ist eine temporäre Tabelle */ #define HA_OPEN_DELAY_KEY_WRITE 8 /* nicht den Index aktualisieren */ #define HA_OPEN_ABORT_IF_CRASHED 16 #define HA_OPEN_FOR_REPAIR 32 /* auch öffnen, wenn sie abgestürzt ist */
Die Speicher-Engine muss in der Regel irgendeine Art von
Zugriffskontrolle implementieren, um in einer Multithread-Umgebung
Schäden an der Tabelle zu verhüten. Ein Beispiel für die
Implementierung von Dateisperren finden Sie in den Methoden
get_share() und
free_share() von
sql/examples/ha_tina.cc.
Die simpelsten Speicher-Engines implementieren nur-lesende Tabellenscans. Solche Engines können eingesetzt werden, um SQL-Anfragen auf Logs oder anderen Datendateien zu unterstützen, die außerhalb von MySQL mit Daten gefüllt werden.
Die Implementierung der Methoden in diesem Absatz ist der erste Schritt zu anspruchsvolleren Speicher-Engines.
Im Folgenden sehen Sie, welche Methoden beim Scan einer
neunzeiligen Tabelle der CSV-Engine aufgerufen
werden:
ha_tina::store_lock ha_tina::external_lock ha_tina::info ha_tina::rnd_init ha_tina::extra - ENUM HA_EXTRA_CACHE Cache record in HA_rrnd() ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::extra - ENUM HA_EXTRA_NO_CACHE End caching of records (def) ha_tina::external_lock ha_tina::extra - ENUM HA_EXTRA_RESET Reset database to after open
Die Funktion
store_lock()
wird vor allen Lese- und Schreibvorgängen aufgerufen.
Bevor die Sperre dem Tabellensperren-Handler hinzugefügt wird,
ruft mysqld die Funktion
store_lock() mit den erforderlichen Sperren
auf. Die Funktion kann das Ausmaß der Sperrung ändern, also
beispielsweise eine blockierende Schreibsperre in eine
nichtblockierende umwandeln, die Sperre ignorieren (wenn keine
MySQL-Tabellensperren benutzt werden sollen) oder Sperren für
viele Tabellen hinzufügen (wie es bei Verwendung eines
MERGE-Handlers getan wird).
Berkeley DB stuft beispielsweise blockierende Tabellensperren
vom Typ TL_WRITE zu nichtblockierenden
TL_WRITE_ALLOW_WRITE-Sperren herab (ein
Hinweis darauf, dass zwar WRITE-Operationen
stattfinden, aber dennoch andere lesende und schreibende Prozesse
zugelassen sind).
Auch beim Aufheben von Sperren wird
store_lock() aufgerufen. In diesem Fall
muss in der Regel nichts weiter veranlasst werden.
Wenn store_lock das Argument
TL_IGNORE bekommt, bedeutet das, dass MySQL
vom Handler verlangt, dasselbe Ausmaß der Sperrung wie beim
letzten Mal zu speichern.
Die möglichen Sperrentypen sind in
includes/thr_lock.h definiert und werden
hier noch einmal aufgeführt:
enum thr_lock_type
{
TL_IGNORE=-1,
TL_UNLOCK, /* SPERREN AUFHEBEN */
TL_READ, /* Lesesperre */
TL_READ_WITH_SHARED_LOCKS,
TL_READ_HIGH_PRIORITY, /* Hat Priorität vor TL_WRITE. Nebenläufige Einfügeoperationen zulässig*/
TL_READ_NO_INSERT, /* READ, nebenläufige Einfügeoperationen unzulässig */
TL_WRITE_ALLOW_WRITE, /* Schreibsperre, aber andere Threads dürfen lesen/schreiben. */
TL_WRITE_ALLOW_READ, /* Schreibsperre, aber andere Threads dürfen lesen/schreiben. */
TL_WRITE_CONCURRENT_INSERT, /* WRITE-Sperre, die von nebenläufigen Einfügeoperationen benutzt wird. */
TL_WRITE_DELAYED, /* Schreibvorgang, der von INSERT DELAYED verwendet wird. READ-Sperren zulässig */
TL_WRITE_LOW_PRIORITY, /* WRITE-Sperre mit geringerer Priorität als TL_READ */
TL_WRITE, /* Normale WRITE-Sperre */
TL_WRITE_ONLY /* Jede neue Sperranforderung wird mit einem Fehler abgebrochen*/
};
Der tatsächliche Umgang mit Sperren hängt von der Implementierung Ihrer Sperren ab. Sie können alle, einige oder gar keine der geforderten Sperrentypen implementieren und eigene Methoden verwenden, wo es Ihnen passend erscheint. Im Folgenden sehen Sie eine Minimalimplementierung für eine Speicher-Engine, die keine Sperren herabstufen muss:
THR_LOCK_DATA **ha_tina::store_lock(THD *thd,
THR_LOCK_DATA **to,
enum thr_lock_type lock_type)
{
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK)
lock.type=lock_type;
*to++= &lock;
return to;
}
Eine komplexere Implementierung finden Sie unter
ha_berkeley::store_lock() und
ha_myisammrg::store_lock().
Die Funktion
external_lock()
wird am Anfang einer Anweisung und bei jedem LOCK
TABLES aufgerufen.
Beispiele für die Verwendung der Funktion
external_lock() finden Sie in den Dateien
sql/ha_innodb.cc und
sql/ha_berkeley.cc, doch die meisten
Speicher-Engines können auch einfach 0
zurückgeben, wie es auch die Speicher-Engine
EXAMPLE tut:
int ha_example::external_lock(THD *thd, int lock_type)
{
DBUG_ENTER("ha_example::external_lock");
DBUG_RETURN(0);
}
Die Funktion, die vor jedem Tabellenscan aufgerufen wird, ist
rnd_init().
Sie wird verwendet, um einen Tabellenscan vorzubereiten, indem
sie Zähler und Zeiger wieder auf den Anfang der Tabelle
zurücksetzt.
Das folgende Beispiel verwendet die Speicher-Engine
CSV:
int ha_tina::rnd_init(bool scan)
{
DBUG_ENTER("ha_tina::rnd_init");
current_position= next_position= 0;
records= 0;
chain_ptr= chain;
DBUG_RETURN(0);
}
Hat der Parameter scan den Wert
true, durchsucht MySQL die Tabelle
sequenziell; hat er den Wert false, werden
willkürliche Leseoperationen auf Zufallspositionen
durchgeführt.
Vor einem Tabellenscan wird die Funktion
info()
aufgerufen, um zusätzliche Tabelleninformationen für den
Optimierer zu beschaffen.
Diese Informationen werden dem Optimierer nicht über
Rückgabewerte geliefert, sondern durch Zuweisung bestimmter
Eigenschaften der Klasse der Speicher-Engine. Diese
Eigenschaften liest der Optimierer, bevor der Aufruf von
info() zurückkehrt.
Viele der von info() gesetzten Werte werden
nicht nur vom Optimierer genutzt, sondern auch von der
SHOW TABLE STATUS-Anweisung.
In sql/handler.h werden alle öffentlichen
Eigenschaften vollständig aufgeführt. Einige der
gebräuchlichsten werden hier noch einmal wiedergegeben:
ulonglong data_file_length; /* Länge der Datendatei */ ulonglong max_data_file_length; /* Länge der Datendatei */ ulonglong index_file_length; ulonglong max_index_file_length; ulonglong delete_length; /* Freie Bytes */ ulonglong auto_increment_value; ha_rows records; /* Datensätze in der Tabelle */ ha_rows deleted; /* Gelöschte Datensätze */ ulong raid_chunksize; ulong mean_rec_length; /* Physikalische Länge der Datensätze */ time_t create_time; /* Erstellungszeitpunkt der Tabelle */ time_t check_time; time_t update_time;
Die für einen Tabellenscan wichtigste Eigenschaft ist
records: Sie gibt an, wie viele Datensätze
die Tabelle hat. Zeigt die Speicher-Engine null oder eine Zeile
in der Tabelle an, verhält sich der Optimierer anders, als wenn
die Tabelle zwei oder mehr Zeilen hat. Daher ist es wichtig, vor
einem Scan von Tabellen, deren Größe nicht genau bekannt ist
(wie zum Beispiel in Fällen, wo die Daten aus einer externen
Quelle kommen), einen Wert größer gleich zwei zurückzugeben.
Vor manchen Operationen wird die Funktion
extra()
aufgerufen, um der Speicher-Engine zusätzliche Hinweise zu
geben, wie sie bestimmte Operationen auszuführen hat.
Die Implementierung der Hinweise im Aufruf von
extra ist nicht obligatorisch. Die meisten
Speicher-Engines geben hier 0 zurück:
int ha_tina::extra(enum ha_extra_function operation)
{
DBUG_ENTER("ha_tina::extra");
DBUG_RETURN(0);
}
Nach der Tabelleninitialisierung ruft der MySQL Server die
Handler-Funktion
rnd_next()
für jede zu untersuchende Zeile einmal auf, bis seine
Suchbedingung erfüllt oder das Ende der Datei erreicht ist. Im
letzteren Fall gibt er HA_ERR_END_OF_FILE
zurück.
Die Funktion rnd_next() nimmt einen
Byte-Array-Parameter namens *buf entgegen.
Dieser *buf-Parameter muss mit dem Inhalt der
Tabellenzeile im internen Format von MySQL gefüllt sein.
Der Server verwendet drei Datenformate: Zeilen mit fester
Länge, Zeilen mit variabler Länge und variabel lange Zeilen
mit BLOB-Zeigern. In jedem der Formate erscheinen die Spalten in
derselben Reihenfolge wie in der CREATE TABLE-Anweisung. (Die
Tabellendefinition wird in der .frm-Datei
gespeichert und Optimierer und Handler können beide die
Metadaten der Tabelle aus derselben Quelle holen, nämlich aus
ihrer TABLE-Struktur.)
Jedes Format beginnt mit einer „NULL-Bitmap“, die für jede nullfähige Spalte ein Bit enthält. Eine Tabelle mit 8 nullfähigen Spalten hat somit eine 1 Byte große Bitmap, während eine Tabelle mit 9 bis 16 nullfähigen Spalten eine 2 Byte große Bitmap besitzt, und so weiter. Eine Ausnahme bilden die Tabellen mit fester Breite: Da sie ein zusätzliches Startbit haben, würde eine solche Tabelle mit 8 nullfähigen Spalten dennoch eine 2 Byte große Bitmap aufweisen.
Hinter der NULL-Bitmap kommen nacheinander die Spalten an die
Reihe. Jede Spalte hat die in Kapitel 11, Datentypen,
angegebene Größe. Im Server sind die Spaltendatentypen in der
Datei sql/field.cc definiert. In einem
Format mit fester Zeilenbreite werden die Spalten einfach
nacheinander angeordnet. In einem Format mit variabler
Zeilenlänge werden die VARCHAR-Spalten mit
einer Länge von 1 oder 2 Byte, gefolgt von einem
Zeichen-String, kodiert. In einer variabel langen Zeile mit
BLOB-Spalten wird jeder BLOB in zwei Teilen
dargestellt: Zuerst kommt ein Integer, der die tatsächliche
Länge des BLOB darstellt, und dann ein
Zeiger auf den Speicherplatz des BLOB.
Beispiele für die Konvertierung (oder das
„Packen“) von Zeilen finden Sie ab der Funktion
rnd_next() in jedem Tabellen-Handler. So
zeigt beispielsweise in ha_tina.cc der Code
von find_current_row(), wie die
TABLE-Struktur (auf welche die Tabelle
verweist) und ein String-Objekt namens Buffer genutzt werden
können, um Zeichendaten aus einer CSV-Datei zu packen. Um eine
Zeile auf die Platte zurückzuspeichern, ist die umgekehrte
Konvertierung erforderlich: Die Zeilen müssen dann aus dem
internen Format wieder zurückkonvertiert werden.
Das folgende Beispiel stammt wieder aus der Speicher-Engine
CSV:
int ha_tina::rnd_next(byte *buf)
{
DBUG_ENTER("ha_tina::rnd_next");
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count, &LOCK_status);
current_position= next_position;
if (!share->mapped_file)
DBUG_RETURN(HA_ERR_END_OF_FILE);
if (HA_ERR_END_OF_FILE == find_current_row(buf) )
DBUG_RETURN(HA_ERR_END_OF_FILE);
records++;
DBUG_RETURN(0);
}
Die Funktion find_current_row() übernimmt
die Konvertierung aus dem internen Zeilenformat in ein
CSV-Zeilenformat:
int ha_tina::find_current_row(byte *buf)
{
byte *mapped_ptr= (byte *)share->mapped_file + current_position;
byte *end_ptr;
DBUG_ENTER("ha_tina::find_current_row");
/* EOF soll als Newline gelten*/
if ((end_ptr= find_eoln(share->mapped_file, current_position,
share->file_stat.st_size)) == 0)
DBUG_RETURN(HA_ERR_END_OF_FILE);
for (Field **field=table->field ; *field ; field++)
{
buffer.length(0);
mapped_ptr++; // Inkrementiere hinter dem ersten Anführungszeichen
for(;mapped_ptr != end_ptr; mapped_ptr++)
{
// Ist notwendig, um Zeilenvorschübe zu konvertieren!
if (*mapped_ptr == '"' &&
(((mapped_ptr[1] == ',') && (mapped_ptr[2] == '"')) ||
(mapped_ptr == end_ptr -1 )))
{
mapped_ptr += 2; // Gehe hinter das , und das "
break;
}
if (*mapped_ptr == '\\' && mapped_ptr != (end_ptr - 1))
{
mapped_ptr++;
if (*mapped_ptr == 'r')
buffer.append('\r');
else if (*mapped_ptr == 'n' )
buffer.append('\n');
else if ((*mapped_ptr == '\\') || (*mapped_ptr == '"'))
buffer.append(*mapped_ptr);
else /* Dies kann nur bei einer extern erzeugten Datei passieren */
{
buffer.append('\\');
buffer.append(*mapped_ptr);
}
}
else
buffer.append(*mapped_ptr);
}
(*field)->store(buffer.ptr(), buffer.length(), system_charset_info);
}
next_position= (end_ptr - share->mapped_file)+1;
/* Vielleicht \N für null verwenden? */
memset(buf, 0, table->s->null_bytes); /* Nullen werden nicht implementiert! */
DBUG_RETURN(0);
}
Wenn der MySQL Server eine Tabelle nicht mehr benötigt, ruft er die Methode close() auf, um Zeiger auf Dateien zu schließen und andere Ressourcen freizugeben.
Speicher-Engines, die Methoden für einen gemeinsamen Zugriff
verwenden, wie sie in CSV und anderen
Beispiel-Engines vorkommen, müssen sich selbst aus der
share-Struktur entfernen:
int ha_tina::close(void)
{
DBUG_ENTER("ha_tina::close");
DBUG_RETURN(free_share(share));
}
Speicher-Engines mit eigenem Share Management-System sollten alle notwendigen Methoden einsetzen, um die Handler-Instanz aus der Freigabe (Share) für die Tabelle zu entfernen, die in ihrem Handler geöffnet ist.
Wenn Ihre Speicher-Engine Lesefähigkeiten bekommen hat, ist als
Nächstes die Unterstützung für
INSERT-Anweisungen an der Reihe. Beherrscht
Ihre Speicher-Engine INSERT, so kann sie auch
mit WORM(write once, read many)-Anwendungen wie etwa dem
Protokollieren und Archivieren von Daten zur späteren Analyse
umgehen.
Alle INSERT-Operationen werden von der Funktion
write_row()
erledigt:
int ha_foo::write_row(byte *buf)
Der Parameter *buf enthält die einzufügende
Zeile im internen Format von MySQL. Eine simple Speicher-Engine
könnte einfach an das Ende der Datendatei gehen und den Inhalt
des Puffers direkt dort anfügen (das würde auch das Lesen von
Zeilen vereinfachen, da man die Zeile lesen und direkt an den
Puffer-Parameter der Funktion rnd_next()
übergeben könnte).
Der Prozess zum Schreiben einer Zeile ist genau das Gegenteil vom
Leseprozess: Er nimmt die Daten im internen Zeilenformat von MySQL
und schreibt sie in die Datendatei. Das folgende Beispiel stammt
von der Speicher-Engine MyISAM:
int ha_myisam::write_row(byte * buf)
{
statistic_increment(table->in_use->status_var.ha_write_count,&LOCK_status);
/* Zeitstempel-Spalte, falls vorhanden, auf die aktuelle Zeit setzen */
if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_INSERT)
table->timestamp_field->set_time();
/*
Wenn eine auto_increment-Spalte vorhanden ist und wir eine geänderte oder neue Zeile laden,
muss der auto_increment-Wert im Datensatz aktualisiert werden.
*/
if (table->next_number_field && buf == table->record[0])
update_auto_increment();
return mi_write(file,buf);
}
Im obigen Beispiel sind drei Dinge bemerkenswert: Die
Tabellenstatistik für Schreiboperationen wird aktualisiert, der
Zeitstempel wird vor dem eigentlichen Schreibvorgang aktualisiert
und die AUTO_INCREMENT-Werte werden
hochgesetzt.
Der MySQL Server führt UPDATE-Anweisungen aus,
indem er so lange (Tabelle, Index, Bereich usw.) scannt, bis er
eine Zeile findet, die zu der WHERE-Klausel der
UPDATE-Anweisung passt. Dann ruft er die
Funktion
update_row()
auf:
int ha_foo::update_row(const byte *old_data, byte *new_data)
Der Parameter *old_data enthält die Daten, die
vor dem Update in der Zeile gespeichert waren, während der
Parameter *new_data den neuen Zeileninhalt
enthält (im internen Zeilenformat von MySQL).
Wie ein Update durchgeführt wird, hängt vom Zeilenformat und der Speicherimplementierung ab. Manche Speicher-Engines ersetzen Daten direkt, während andere Implementierungen die vorhandene Zeile löschen und die neue Zeile am Ende der Datendatei anfügen.
Speicher-Engines ohne Indizierung können den Inhalt des
Parameters *old_data ignorieren und müssen
sich nur mit dem Pufferinhalt *new_data
abgeben. Engines mit Transaktionsunterstützung müssen unter
Umständen die Puffer vergleichen, um für ein mögliches
späteres Rollback herauszufinden, welche Änderungen vorgenommen
wurden.
Enthält die zu ändernde Tabelle Zeitstempelspalten, muss die
Funktion update_row() auch diese Zeitstempel
aktualisieren. Das folgende Beispiel stammt von der
Speicher-Engine CSV:
int ha_tina::update_row(const byte * old_data, byte * new_data)
{
int size;
DBUG_ENTER("ha_tina::update_row");
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count,
&LOCK_status);
if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_UPDATE)
table->timestamp_field->set_time();
size= encode_quote(new_data);
if (chain_append())
DBUG_RETURN(-1);
if (my_write(share->data_file, buffer.ptr(), size, MYF(MY_WME | MY_NABP)))
DBUG_RETURN(-1);
DBUG_RETURN(0);
}
Beachten Sie, wie in diesem Beispiel der Zeitstempel eingestellt wurde.
Der MySQL Server verwendet für
DELETE-Anweisungen denselben Ansatz wie für
UPDATE-Anweisungen: Er geht mithilfe der
Funktion rnd_next() zu der Zeile, die
gelöscht werden soll, und ruft dann die Funktion
delete_row()
auf:
int ha_foo::delete_row(const byte *buf)
Der Parameter *buf enthält den Inhalt der zu
löschenden Zeile. Speicher-Engines ohne Indizierung können
diesen Parameter ignorieren, aber Speicher-Engines mit
Transaktionsunterstützung müssen die gelöschten Daten für ein
späteres Rollback speichern.
Das folgende Beispiel stammt von der
CSV-Engine:
int ha_tina::delete_row(const byte * buf)
{
DBUG_ENTER("ha_tina::delete_row");
statistic_increment(table->in_use->status_var.ha_delete_count,
&LOCK_status);
if (chain_append())
DBUG_RETURN(-1);
--records;
DBUG_RETURN(0);
}
Das Wichtige an diesem Beispiel sind die Aktualisierung der
delete_count-Statistik und die Zeilenzählung.
Speicher-Engines können nicht nur Tabellenscanning implementieren, sondern auch Funktionen für ein nichtsequenzielles Lesen. Der MySQL Server nutzt diese Funktionen für bestimmte Sortieroperationen.
Die Funktion
position()
wird nach jedem rnd_next()-Aufruf
benötigt, wenn die Daten neu geordnet werden müssen:
void ha_foo::position(const byte *record)
Der Inhalt von *record ist Ihre Sache; was
Sie auch immer als Inhalt einsetzen, wird in einem späteren
Abruf der Zeile zurückgeliefert. Die meisten Speicher-Engines
speichern irgendeine Art von Offset oder Primärschlüsselwert.
Die Funktion
rnd_pos()
verhält sich ähnlich wie rnd_next(), hat
aber einen zusätzlichen Parameter:
int ha_foo::rnd_pos(byte * buf, byte *pos)
Dieser *pos-Parameter enthält die Position,
die zuvor mit der Funktion position()
ermittelt wurde.
Eine Speicher-Engine muss die Zeile an der angegebenen Position
ausfindig machen und durch *buf im internen
Zeilenformat von MySQL zurückgeben.
- 15.15.1. Überblick über Indizes
- 15.15.2. Indexinformationen während
CREATE TABLE-Operationen erhalten - 15.15.3. Erzeugen von Indexschlüsseln
- 15.15.4. Schlüsselinformationen parsen
- 15.15.5. Indexinformationen an den Optimierer liefern
- 15.15.6. Nutzung des Indexes vorbereiten mit
index_init() - 15.15.7. Aufräumen mit
index_end() - 15.15.8. Implementierung der Funktion
index_read() - 15.15.9. Implementierung der Funktion
index_read_idx() - 15.15.10. Implementierung der Funktion
index_next() - 15.15.11. Implementierung der Funktion
index_prev() - 15.15.12. Implementierung der Funktion
index_first() - 15.15.13. Implementierung der Funktion
index_last()
Sobald eine Engine über einfache Lese- und Schreiboperationen verfügt, muss als Nächstes Unterstützung für Indizes her. Ohne Indizes ist die Leistung einer Speicher-Engine äußerst mager.
Dieser Abschnitt beschreibt, welche Methoden implementiert werden müssen, damit eine Speicher-Engine Indizes unterstützt.
Indexunterstützung für eine Speicher-Engine bedeutet zweierlei: Informationen an den Optimierer zu geben und indexbezogene Methoden zu implementieren. Die Informationen, die der Optimierer erhält, helfen ihm zu entscheiden, welchen Index er verwenden soll oder ob er die Indizierung beiseite lassen und stattdessen einen Tabellenscan durchführen soll.
Die Indexmethoden lesen entweder Zeilen, die zu einem Schlüssel passen, scannen eine Zeilenmenge in der Reihenfolge ihrer Indizes oder lesen Informationen direkt aus dem Index.
Das folgende Beispiel zeigt die Funktionsaufrufe während einer
UPDATE-Anfrage, die einen Index nutzt, wie
beispielsweise in UPDATE foo SET ts = now() WHERE id =
1:
ha_foo::index_init ha_foo::index_read ha_foo::index_read_idx ha_foo::rnd_next ha_foo::update_row
Zusätzlich zu Methoden, die Indizes lesen, benötigt Ihre Speicher-Engine auch Methoden, die neue Indizes erstellen und Tabellenindizes auf dem Laufenden halten, wenn Zeilen hinzugefügt, modifiziert oder entfernt werden.
Speicher-Engines mit Indexunterstützung sollten die
Indexinformationen möglichst während einer CREATE
TABLE-Operation beschaffen und zur späteren
Verwendung speichern. Der Grund: Die Indexinformationen sind
beim Anlegen der Tabelle und des Indexes am einfachsten zu
bekommen und lassen sich später nicht mehr so leicht abrufen.
Die Daten des Tabellenindexes liegen in der
key_info-Struktur des
TABLE-Arguments der
create()-Funktion vor.
In der key_info-Struktur gibt es ein
flag, welches das Verhalten des Indexes
definiert:
#define HA_NOSAME 1 /* Keine Doppeleinträge vorhanden */ #define HA_PACK_KEY 2 /* String zu vorigem Schlüssel packen */ #define HA_AUTO_KEY 16 #define HA_BINARY_PACK_KEY 32 /* Alle Schlüssel zu vorigem Schlüssel packen */ #define HA_FULLTEXT 128 /* Volltextsuche */ #define HA_UNIQUE_CHECK 256 /* Schlüssel auf Eindeutigkeit prüfen */ #define HA_SPATIAL 1024 /* Raumbezogene Suche */ #define HA_NULL_ARE_EQUAL 2048 /* Gleichheitsvergleich für NULL in Schlüssel möglich */ #define HA_GENERATED_KEY 8192 /* Automatisch generierter Schlüssel */
Zusätzlich zum flag ist ein Enumerator
namens algorithm vorhanden, der den
gewünschten Indextyp angibt:
enum ha_key_alg {
HA_KEY_ALG_UNDEF= 0, /* Nicht angegeben (alte Datei) */
HA_KEY_ALG_BTREE= 1, /* B-Tree, ist der Standard */
HA_KEY_ALG_RTREE= 2, /* R-Tree, für raumbezogenes Suchen */
HA_KEY_ALG_HASH= 3, /* HASH-Schlüssel (HEAP-Tabellen) */
HA_KEY_ALG_FULLTEXT= 4 /* FULLTEXT (MyISAM-Tabellen) */
};
Zusätzlich zum flag und
algorithm ist ein Array von
key_part-Elementen vorhanden, welche die
einzelnen Teile eines zusammengesetzten Schlüssels beschreiben.
Diese Schlüsselteile definieren das zu dem jeweiligen Teil
gehörende Feld, geben an, ob der Schlüssel gepackt werden
soll, und verraten den Datentyp und die Länge des Indexteils.
Unter ha_myisam.cc finden Sie ein Beispiel
dafür, wie diese Daten geparst werden.
Als Alternative kann eine Speicher-Engine auch dem Beispiel von
ha_berkeley.cc folgen und bei jeder
Operation Indexinformationen aus der
TABLE-Struktur des Handlers lesen.
Bei jeder Schreiboperation auf Tabellen
(INSERT, UPDATE,
DELETE) muss die Speicher-Engine ihre
internen Indexdaten aktualisieren.
Die hierzu verwendete Methode variiert von Engine zu Engine und hängt davon ab, welche Methode zum Speichern des Indexes verwendet wird.
Im Allgemeinen muss die Speicher-Engine die in Funktionen wie
write_row(),
delete_row()
und
update_row()
übergebenen Zeilendaten mit den Indexinformationen der Tabelle
kombinieren, um festzustellen, welche Indexdaten geändert
werden müssen, und die notwendigen Modifikationen vorzunehmen.
Mit welcher Methode Zeile und Index zusammengebracht werden,
hängt von dem Ansatz Ihrer Speicherung ab. Die Speicher-Engine
BerkeleyDB speichert den Primärschlüssel
der Zeile im Index, während andere Engines oft nur den
Zeilen-Offset speichern.
Viele der Indexmethoden übergeben ein Byte-Array namens
*key, welches den zu lesenden Indexeintrag in
einem Standardformat angibt. Ihre Speicher-Engine muss die
Informationen des Schlüssels extrahieren und in ihr internes
Indexformat übersetzen, um die zum Index gehörige Zeile zu
ermitteln.
Die im Schlüssel vorliegenden Daten werden mit einer Iteration
durch den Schlüssel beschafft. Ihr Format ist so, wie es in
table->key_info[
definiert wurde. Das folgende Beispiel aus
index]->key_part[part_num]ha_berkeley.cc zeigt, wie die
Speicher-Engine BerkeleyDB einen in
*key definierten Schlüssel in ihr internes
Format konvertiert:
/*
Erzeuge aus einem ungepackten MySQL-Schlüssel (wie dem, der von index_read() übermittelt wird) einen gepackten.
Anhand dieses Schlüssels wird eine Zeile gelesen
*/
DBT *ha_berkeley::pack_key(DBT *key, uint keynr, char *buff,
const byte *key_ptr, uint key_length)
{
KEY *key_info=table->key_info+keynr;
KEY_PART_INFO *key_part=key_info->key_part;
KEY_PART_INFO *end=key_part+key_info->key_parts;
DBUG_ENTER("bdb:pack_key");
bzero((char*) key,sizeof(*key));
key->data=buff;
key->app_private= (void*) key_info;
for (; key_part != end && (int) key_length > 0 ; key_part++)
{
uint offset=0;
if (key_part->null_bit)
{
if (!(*buff++ = (*key_ptr == 0))) // Für NULL wird 0 gespeichert
{
key_length-= key_part->store_length;
key_ptr+= key_part->store_length;
key->flags|=DB_DBT_DUPOK;
continue;
}
offset=1; // Daten liegen unter key_ptr+1
}
buff=key_part->field->pack_key_from_key_image(buff,(char*) key_ptr+offset,
key_part->length);
key_ptr+=key_part->store_length;
key_length-=key_part->store_length;
}
key->size= (buff - (char*) key->data);
DBUG_DUMP("key",(char*) key->data, key->size);
DBUG_RETURN(key);
}
Damit die Indizierung wirkungsvoll eingesetzt wird, müssen Speicher-Engines dem Optimierer Informationen über die Tabelle und ihre Indizes liefern. Anhand dieser Informationen wird entschieden, ob und, wenn ja, welcher Index genutzt werden soll.
Durch Aufruf der Funktion
handler::info()
fordert der Optimierer die Aktualisierung der Tabellendaten
an. Die Funktion info() hat keinen
Rückgabewert; stattdessen wird erwartet, dass die
Speicher-Engine eine Reihe von öffentlichen Variablen setzt,
die der Server dann nach Bedarf auslesen kann. Diese Werte
werden auch für bestimmte SHOW-Ausgaben
wie beispielsweise SHOW TABLE STATUS und
für INFORMATION_SCHEMA eingesetzt.
Alle Variablen sind optional, sollten aber nach Möglichkeit ausgefüllt werden:
records– Die Anzahl der Zeilen in der Tabelle. Wenn Sie nicht schnell eine genaue Zahl liefern können, sollten Sie diesen Wert auf größer als 1 setzen, damit der Optimierer nicht für Tabellen mit null oder einer Zeile in Aktion treten muss.deleted– Die Anzahl der gelöschten Zeilen in der Tabelle. Dient der Ermittlung von Tabellenfragmentation, wo sie vorliegt.data_file_length– Die Größe der Datendatei in Bytes. Hilft dem Optimierer, den Aufwand von Leseoperationen zu berechnen.index_file_length– Die Größe der Indexdatei in Bytes. Hilft dem Optimierer, den Aufwand von Leseoperationen zu berechnen.mean_rec_length– Die Durchschnittslänge einer einzelnen Zeile in Bytes.scan_time– I/O-Aufwand für den Versuch eines vollständigen Tabellenscans.delete_length– (keine Beschreibung verfügbar)check_time– (keine Beschreibung verfügbar)
Bei der Berechnung von Werten geht Geschwindigkeit vor Genauigkeit, da es keinen Sinn hat, viel Zeit zu vertrödeln, um dem Optimierer den schnellsten Weg aufzuzeigen. Schätzungen innerhalb einer Größenordnung sind normalerweise ausreichend.
Die Funktion
records_in_range()
wird vom Optimierer aufgerufen, um besser entscheiden zu
können, welcher Index einer Tabelle für eine Anfrage oder
einen Join benutzt werden soll. Sie ist folgendermaßen
definiert:
ha_rows ha_foo::records_in_range(uint inx, key_range *min_key, key_range *max_key)
Der Parameter inx ist der zu prüfende
Index. Der Parameter *min_key gibt das
untere und der Parameter *max_key das obere
Ende des Bereichs an.
min_key.flag kann einen der folgenden Werte
haben:
HA_READ_KEY_EXACT- Schlüssel in den Bereich einbeziehenHA_READ_AFTER_KEY- Schlüssel nicht in den Bereich einbeziehen
max_key.flag kann einen der folgenden Werte
haben:
HA_READ_BEFORE_KEY- Schlüssel nicht in den Bereich einbeziehenHA_READ_AFTER_KEY- Alle 'end_key'-Werte in den Bereich einbeziehen
Folgende Rückgabewerte sind zulässig:
0- Keine passenden Schlüssel im gegebenen Bereich vorhandennumber > 0- Es gibt ungefährnumberpassende Zeilen im BereichHA_POS_ERROR- Fehler im Indexbaum
Bei der Berechnung der Werte geht Geschwindigkeit vor Genauigkeit.
Die Funktion
index_init()
wird vor Benutzung eines Indexes aufgerufen, damit die
Speicher-Engine die notwendigen Vorbereitungen oder
Optimierungen vornehmen kann:
int ha_foo::index_init(uint keynr, bool sorted)
Da die meisten Speicher-Engines keine besonderen Vorbereitungen treffen, wird in diesem Fall eine Standardimplementierung verwendet, wenn die Methode nicht explizit in der Engine implementiert ist:
int handler::index_init(uint idx) { active_index=idx; return 0; }
Die Funktion
index_end()
ist das Gegenstück zu index_init(). Ihre
Aufgabe ist es, hinter index_init() wieder
aufzuräumen.
Wenn eine Speicher-Engine index_init()
nicht implementiert, muss sie auch
index_end() nicht implementieren.
Die Funktion
index_read()
wird verwendet, um eine Zeile anhand eines Schlüssels
abzufragen:
int ha_foo::index_read(byte * buf, const byte * key, uint key_len, enum ha_rkey_function find_flag)
Der Parameter *buf ist ein Byte-Array, in dem
die Speicher-Engine die Zeile speichert, die zu dem
Indexschlüssel *key gehört. Der Parameter
key_len gibt bei Präfixvergleichen die
Länge des Präfixes an und find_flag ist ein
Enumerator, der das Suchverhalten bestimmt.
Der zu verwendende Index wird vorher im Aufruf von
index_init()
festgelegt und dann in der Handler-Variablen
active_index gespeichert.
Folgende Werte sind für find_flag zulässig:
HA_READ_KEY_EXACT HA_READ_KEY_OR_NEXT HA_READ_PREFIX_LAST HA_READ_PREFIX_LAST_OR_PREV HA_READ_BEFORE_KEY HA_READ_AFTER_KEY HA_READ_KEY_OR_NEXT HA_READ_KEY_OR_PREV
Speicher-Engines müssen den Parameter *key
in ihr spezifisches Format konvertieren. Danach verwenden sie
ihn, um anhand von find_flag die passende
Zeile zu finden und im internen Zeilenformat von MySQL in
*buf zu speichern. Weitere Informationen
über das interne Zeilenformat finden Sie unter
Abschnitt 15.9.6, „Implementierung der Funktion rnd_next()“.
Die Speicher-Engine muss nicht nur die passende Zeile zurückgeben, sondern auch einen Cursor setzen, um sequenzielle Index-Reads zu unterstützen.
Ist der Parameter *key null, liest die
Speicher-Engine den ersten Schlüssel im Index.
Die Funktion
index_read_idx()
gleicht
index_read()
mit dem Unterschied, dass index_read_idx()
noch einen weiteren keynr-Parameter
akzeptiert:
int ha_foo::index_read_idx(byte * buf, uint keynr, const byte * key,
uint key_len, enum ha_rkey_function find_flag)
Der Parameter keynr gibt den zu lesenden
Index an, während bei index_read der Index
bereits eingestellt ist.
Wie mit index_read() muss auch hier die
Speicher-Engine die zum Schlüssel gehörige Zeile gemäß dem
find_flag zurückgeben und für zukünftige
Leseoperationen einen Cursor setzen.
Die Funktion
index_next()
wird zum Durchsuchen des Indexes benutzt:
int ha_foo::index_next(byte * buf)
Im Parameter *buf wird die Zeile gespeichert,
die entsprechend dem internen Cursor, den die Speicher-Engine
bei Operationen wie index_read() und
index_first() gesetzt hatte, dem nächsten
passenden Schlüsselwert entspricht.
Die Funktion
index_prev()
wird für umgekehrtes Indexscanning verwendet:
int ha_foo::index_prev(byte * buf)
Im Parameter *buf wird die Zeile gespeichert,
die entsprechend dem internen Cursor, den die Speicher-Engine
bei Operationen wie index_read() und
index_last() gesetzt hatte, dem vorherigen
passenden Schlüsselwert entspricht.
Die Funktion
index_first()
wird für das Indexscanning verwendet:
int ha_foo::index_first(byte * buf)
Im Parameter *buf wird die Zeile gespeichert,
die dem ersten Schlüsselwert im Index entspricht.
Die Funktion
index_last()
wird für das umgekehrte Indexscanning verwendet:
int ha_foo::index_last(byte * buf)
Im Parameter *buf wird die Zeile gespeichert,
die dem letzten Schlüsselwert im Index entspricht.
In diesem Abschnitt sind Methoden beschrieben, die implementiert werden müssen, damit eine Speicher-Engine Transaktionen unterstützen kann.
Bitte beachten Sie, dass das Transaktionsmanagement eine
komplizierte Sache sein kann, zu der auch Methoden zur
Zeilenversionierung und Redo-Logs gehören, die den Rahmen dieser
Dokumentation sprengen würden. Hier wird lediglich beschrieben,
welche Methoden notwendig sind, und nicht, wie diese implementiert
werden. Implementierungsbeispiele finden Sie in
ha_innodb.cc und
ha_berkeley.cc.
Transaktionen werden nicht explizit auf der Ebene der
Speicher-Engines, sondern implizit durch Aufrufe der Funktion
start_stmt() oder
external_lock() gestartet. Falls bei Aufruf
dieser Funktionen bereits eine Transaktion läuft, wird diese
nicht ersetzt.
Die Speicher-Engine speichert Transaktionsinformationen in ihrem
pro Verbindung zugewiesenen Arbeitsspeicher und registriert die
Transaktion beim MySQL Server, damit dieser später
COMMIT- und
ROLLBACK-Operationen ausführen kann.
Die Speicher-Engine muss irgendeine Art von Versionierung oder Protokollierung implementieren, damit alle Operationen, die im Rahmen der Transaktion ausgeführt werden, wieder zurückgerollt werden können.
Nach getaner Arbeit ruft der MySQL Server entweder die
commit()-Funktion oder die im Handlerton
der Speicher-Engine definierte
rollback()-Funktion auf.
Die Speicher-Engine startet eine Transaktion, wenn die Funktion
start_stmt() oder
external_lock() aufgerufen wird.
Ist noch keine Transaktion aktiv, muss die Speicher-Engine eine
neue beginnen und beim MySQL Server registrieren, damit später
ROLLBACK oder COMMIT
aufgerufen werden kann.
Die erste Funktion, die eine Transaktion beginnen kann, ist
start_stmt().
Das folgende Beispiel zeigt, wie eine Speicher-Engine eine Transaktion registrieren könnte:
int my_handler::start_stmt(THD *thd, thr_lock_type lock_type)
{
int error= 0;
my_txn *txn= (my_txn *) thd->ha_data[my_handler_hton.slot];
if (txn == NULL)
{
thd->ha_data[my_handler_hton.slot]= txn= new my_txn;
}
if (txn->stmt == NULL && !(error= txn->tx_begin()))
{
txn->stmt= txn->new_savepoint();
trans_register_ha(thd, FALSE, &my_handler_hton);
}
return error;
}
THD ist die aktuelle Clientverbindung. Sie
speichert zustandsrelevante Daten für den aktuellen Client,
wie beispielsweise seine Identität, Netzwerkverbindung und
andere Verbindungsdaten.
thd->ha_data[my_handler_hton.slot] ist ein
Zeiger in thd auf die
verbindungsspezifischen Daten dieser Speicher-Engine. In
diesem Beispiel wird er verwendet, um den Transaktionskontext
zu speichern.
Ein weiteres Beispiel für die Implementierung von
start_stmt() finden Sie in
ha_innodb.cc.
MySQL ruft zu Beginn jeder Anweisung für jede zu verwendende
Tabelle
handler::external_lock()
auf. Somit wird immer dann, wenn eine Tabelle zum ersten Mal
angesprochen wird, implizit eine Transaktion gestartet.
Da noch keine Sperren vorhanden sind, werden alle Tabellen,
die möglicherweise zwischen dem Anfang und dem Ende einer
Anweisung verwendet werden könnten, gesperrt, bevor die
Ausführung der Anweisung beginnt. Für alle diese Tabellen
wird handler::external_lock() aufgerufen.
Wenn also ein INSERT einen Trigger
abfeuert, der eine gespeicherte Prozedur aufruft, die eine
gespeicherte Funktion aufruft usw., werden alle von Trigger,
gespeicherter Prozedur, Funktion usw. verwendeten Tabellen
schon zu Beginn des INSERT gesperrt. Und
wenn ein Konstrukt wie das folgende vorliegt, dann werden beide Tabellen gesperrt:
IF .. verwende eine Tabelle ELSE .. verwende eine andere Tabelle
Außerdem gilt: Wenn ein Benutzer LOCK
TABLES eingibt, ruft MySQL
handler::external_lock nur ein einziges
Mal auf. In diesem Fall führt MySQL
handler::start_stmt() zu Beginn der
Anweisung aus.
Das folgende Beispiel zeigt, wie eine Speicher-Engine eine Transaktion starten und Sperranforderungen dabei berücksichtigen kann:
int my_handler::external_lock(THD *thd, int lock_type)
{
int error= 0;
my_txn *txn= (my_txn *) thd->ha_data[my_handler_hton.slot];
if (txn == NULL)
{
thd->ha_data[my_handler_hton.slot]= txn= new my_txn;
}
if (lock_type != F_UNLCK)
{
bool all_tx= 0;
if (txn->lock_count == 0)
{
txn->lock_count= 1;
txn->tx_isolation= thd->variables.tx_isolation;
all_tx= test(thd->options & (OPTION_NOT_AUTOCOMMIT | OPTION_BEGIN | OPTION_TABLE_LOCK));
}
if (all_tx)
{
txn->tx_begin();
trans_register_ha(thd, TRUE, &my_handler_hton);
}
else
if (txn->stmt == 0)
{
txn->stmt= txn->new_savepoint();
trans_register_ha(thd, FALSE, &my_handler_hton);
}
}
else
{
if (txn->stmt != NULL)
{
/* Schreibe Transaktion fest, wenn Autocommit-Modus eingeschaltet */
my_handler_commit(thd, FALSE);
delete txn->stmt; // Lösche Savepoint
txn->stmt= NULL;
}
}
return error;
}
Jede Speicher-Engine muss immer zu Beginn einer Transaktion
trans_register_ha() aufrufen. Die
Funktion trans_register_ha() registriert
eine Transaktion beim MySQL Server, um spätere
COMMIT- und
ROLLBACK-Operationen möglich zu machen.
Ein weiteres Implementierungsbeispiel für
external_lock() finden Sie in
ha_innodb.cc.
Von den beiden wichtigsten Transaktionsoperationen ist
ROLLBACK am schwierigsten zu
implementieren. Alle Operationen, die während der Transaktion
auftraten, müssen rückgängig gemacht werden, damit sämtliche
Zeilen wieder den unveränderten Zustand vor der Transaktion
zurückerhalten.
Um ROLLBACK zu unterstützen, benötigen Sie
eine Funktion, die folgender Definition entspricht:
int (*rollback)(THD *thd, bool all);
Der Name dieser Funktion wird dann im
rollback-Eintrag (dem 13.) des
Handlerton
aufgeführt.
Der Parameter THD zeigt an, welche
Transaktion zurückgerollt werden soll, und bool
all legt fest, ob die gesamte Transaktion oder nur die
letzte Anweisung rückgängig gemacht werden soll.
Die Implementierungsdetails von ROLLBACK sind
von Engine zu Engine unterschiedlich. Beispiele finden Sie in
ha_innodb.cc und
ha_berkeley.cc.
Bei einer Commit-Operation werden alle während einer Transaktion vorgenommenen Änderungen festgeschrieben, sodass eine Rollback-Operation danach nicht mehr möglich ist. Je nachdem, welche Transaktionsisolation verwendet wurde, werden die Änderungen dann zum ersten Mal für andere Threads sichtbar.
Zur Unterstützung von COMMIT benötigen Sie
eine Funktion, die wie folgt definiert ist:
int (*commit)(THD *thd, bool all);
Der Name dieser Funktion wird dann im
commit-Eintrag (dem 12.) des
Handlerton
aufgeführt.
Der Parameter THD zeigt an, welche
Transaktion festgeschrieben werden soll, und bool
all legt fest, ob dies ein kompletter Commit ist oder
nur das Ende einer zu einer Transaktion gehörenden Anweisung.
Die Implementierungsdetails von COMMIT sind
von Engine zu Engine unterschiedlich. Beispiele finden Sie in
ha_innodb.cc and
ha_berkeley.cc.
Läuft der Server im Autocommit-Modus, so müsste die
Speicher-Engine automatisch alle nur-lesenden Anweisungen wie
beispielsweise SELECT festschreiben.
Das "Autocommitten" in einer Speicher-Engine funktioniert durch
Zählen von Sperren. Jeder Aufruf von
external_lock() inkrementiert den Zähler
und jeder Aufruf von external_lock() mit
dem Argument F_UNLCK dekrementiert ihn.
Fällt die Anzahl der Sperren auf null, wird ein Commit
ausgelöst.
Zuerst sollte der Implementierer wissen, wie viele Bytes erforderlich sind, um die Savepoint-Daten zu speichern. Diese Anzahl sollte eine feste Größe und möglichst nicht zu groß sein, da der MySQL Server Platz zum Speichern des Savepoints für alle Speicher-Engines und jeden benannten Savepoint zuweisen muss.
Der Implementierer sollte die Daten in dem von mysqld zuvor zugewiesenen Platz speichern und den Inhalt dieses zugewiesenen Speichers auch nutzen, um Rollback- oder Savepoint-Freigabeoperationen auszuführen.
Wenn ein COMMIT oder
ROLLBACK eintritt (wobei bool
all auf true gesetzt ist), werden
alle Savepoints freigegeben. Wenn die Speicher-Engine Ressourcen
für Savepoints zuweist, sollte sie diese freigeben.
Die folgenden Handlerton-Elemente müssen implementiert werden, damit Savepoints unterstützt werden können (es sind die Elemente 7, 9, 10 und 11):
uint savepoint_offset; int (*savepoint_set)(THD *thd, void *sv); int (*savepoint_rollback)(THD *thd, void *sv); int (*savepoint_release)(THD *thd, void *sv);
Das siebte Element des Handlertons ist der
savepoint_offset:
uint savepoint_offset;
Der savepoint_offset muss mit einer festen
Größe initialisiert werden, die ausreicht, um die Savepoint
zu speichernden Informationen aufzunehmen.
Die Funktion savepoint_set() wird immer
dann aufgerufen, wenn ein Benutzer den Befehl
SAVEPOINT gibt:
int (*savepoint_set)(THD *thd, void *sv);
Der Parameter *sv verweist auf einen
uninitialisierten Speicherbereich, dessen Größe in
savepoint_offset definiert wurde.
Wenn savepoint_set() aufgerufen wird,
muss die Speicher-Engine Savepoint-Informationen in
sv speichern, damit der Server die
Transaktion später bis zu dem Savepoint zurückrollen oder
die Ressourcen des Savepoints wieder freigeben kann.
Die Funktion savepoint_rollback() wird
immer dann aufgerufen, wenn ein Benutzer die ROLLBACK
TO SAVEPOINT-Anweisung erteilt:
int (*savepoint_rollback) (THD *thd, void *sv);
Der Parameter *sv verweist auf den
Speicherbereich, der zuvor an die Funktion
savepoint_set() übergeben wurde.
Die Funktion savepoint_release() wird
immer dann aufgerufen, wenn ein Benutzer die Anweisung
RELEASE SAVEPOINT verwendet:
int (*savepoint_release) (THD *thd, void *sv);
Der Parameter *sv verweist auf den
Speicherbereich, der zuvor an die Funktion
savepoint_set() übergeben wurde.
- 15.17.1. bas_ext
- 15.17.2. close
- 15.17.3. create
- 15.17.4. delete_row
- 15.17.5. delete_table
- 15.17.6. external_lock
- 15.17.7. extra
- 15.17.8. index_end
- 15.17.9. index_first
- 15.17.10. index_init
- 15.17.11. index_last
- 15.17.12. index_next
- 15.17.13. index_prev
- 15.17.14. index_read_idx
- 15.17.15. index_read
- 15.17.16. info
- 15.17.17. open
- 15.17.18. position
- 15.17.19. records_in_range
- 15.17.20. rnd_init
- 15.17.21. rnd_next
- 15.17.22. rnd_pos
- 15.17.23. start_stmt
- 15.17.24. store_lock
- 15.17.25. update_row
- 15.17.26. write_row
Zweck
Definiert die von der Speicher-Engine verwendeten Dateierweiterungen.
Zusammenfassung
virtual const char ** bas_ext
( | ); |
| ; |
Beschreibung
Dies ist die Methode bas_ext. Sie wird
aufgerufen, um dem MySQL Server die Liste der von der
Speicher-Engine verwendeten Dateierweiterungen in Form eines mit
null endenden String-Arrays mitzuteilen.
Indem sie eine Liste der Dateierweiterungen angeben, können
Speicher-Engines in vielen Fällen auf die Funktion
delete_table()
verzichten, da der MySQL Server alle Verweise auf die Tabelle
schließt und alle Dateien mit den angegebenen Erweiterungen
löscht.
Parameter
Diese Funktion hat keine Parameter.
Rückgabewerte
Der Rückgabewert ist ein auf null endendes String-Array mit den Dateierweiterungen der Speicher-Engine. Das folgende Beispiel stammt von der Engine
CSV:static const char *ha_tina_exts[] = { ".CSV", NullS };
Verwendung
static const char *ha_tina_exts[] =
{
".CSV",
NullS
};
const char **ha_tina::bas_ext() const
{
return ha_tina_exts;
}
Standardimplementierung
static const char *ha_example_exts[] = {
NullS
};
const char **ha_example::bas_ext() const
{
return ha_example_exts;
}
Zweck
Schließt eine geöffnete Tabelle.
Zusammenfassung
virtual int close
( | void); |
| void ; |
Beschreibung
Dies ist die Methode close.
Schließt eine Tabelle. Ein guter Zeitpunkt, um die zugewiesenen Ressourcen wieder freizugeben.
Wird von sql_base.cc,
sql_select.cc und table.cc
aufgerufen. In sql_select.cc wird diese
Methode nur zum Schließen temporärer Tabellen oder bei der
Konvertierung einer temporären in eine
MyISAM-Tabelle verwendet. Wegen
sql_base.cc schauen Sie unter
close_data_tables() nach.
Parameter
void
Rückgabewerte
Keine Rückgabewerte.
Verwendung
Ein Beispiel von der CSV-Engine:
int ha_example::close(void)
{
DBUG_ENTER("ha_example::close");
DBUG_RETURN(free_share(share));
}
Zweck
Legt eine neue Tabelle an.
Zusammenfassung
virtual int create
( | name, | |
| form, | ||
info); |
| const char * | name ; |
| TABLE * | form ; |
| HA_CREATE_INFO * | info ; |
Beschreibung
Dies ist die Methode create.
create() wird aufgerufen, um eine Tabelle
anzulegen. Der Variablenname ist dann der Name der Tabelle. Wenn
Sie create() aufrufen, brauchen Sie die
Tabelle nicht zu öffnen. Auch die
.frm-Datei ist dann bereits angelegt,
sodass ein Aufruf von adjusting create_info
nicht mehr zu empfehlen ist.
Wird von handler.cc in Form von
ha_create_table() aufgerufen.
Parameter
nameforminfo
Rückgabewerte
Keine Rückgabewerte.
Verwendung
Beispiel von der Speicher-Engine CSV:
int ha_tina::create(const char *name, TABLE *table_arg,
HA_CREATE_INFO *create_info)
{
char name_buff[FN_REFLEN];
File create_file;
DBUG_ENTER("ha_tina::create");
if ((create_file= my_create(fn_format(name_buff, name, "", ".CSV",
MY_REPLACE_EXT|MY_UNPACK_FILENAME),0,
O_RDWR | O_TRUNC,MYF(MY_WME))) < 0)
DBUG_RETURN(-1);
my_close(create_file,MYF(0));
DBUG_RETURN(0);
}
Zweck
Löscht eine Zeile.
Zusammenfassung
virtual int delete_row
( | buf); |
| const byte * | buf ; |
Beschreibung
Dies ist die Methode delete_row.
buf
enthält eine Kopie der zu löschenden Zeile. Der Server
verwendet diese Funktion, unmittelbar nachdem die aktuelle Zeile
aufgerufen wurde (von einer vorangegangenen
rnd_next()-Funktion oder einem
Indexaufruf). Wenn Sie einen Zeiger auf die letzte Zeile
bewahren oder auf einen Primärschlüssel zugreifen können,
wird das Löschen viel einfacher. Denken Sie daran, dass der
Server aufeinander folgende Löschungen nicht garantiert.
ORDER BY-Klauseln können verwendet werden.
Wird in sql_acl.cc und
sql_udf.cc aufgerufen, um interne
Tabelleninformationen zu verwalten. Wird auch in
sql_delete.cc,
sql_insert.cc und
sql_select.cc benutzt. In
sql_select wird diese Funktion zum Entfernen
von Duplikaten eingesetzt, während sie in
insert für
REPLACE-Aufrufe verwendet wird.
Parameter
buf
Rückgabewerte
Keine Rückgabewerte.
Verwendung
(kein Beispiel verfügbar)
Standardimplementierung
{ return HA_ERR_WRONG_COMMAND; }
Zweck
Alle Dateien löschen, die eine von
bas_ext()
gemeldete Erweiterung haben.
Zusammenfassung
virtual int delete_table
( | name); |
| const char * | name ; |
Beschreibung
Dies ist die Methode delete_table.
Dient dem Löschen einer Tabelle. Wenn
delete_table() aufgerufen wird, sind alle
offenen Verweise auf diese Tabelle geschlossen (und auch Ihre
globalen, gemeinsam genutzten Verweise freigegeben) worden. Der
Variablenname ist der Name der Tabelle. Zuvor angelegte Dateien
müssen an diesem Punkt gelöscht werden.
Wenn Sie diese Funktion nicht implementieren, wird die
Standardfunktion delete_table() von
handler.cc aufgerufen, die alle Dateien mit
den von bas_ext() zurückgegebenen
Erweiterungen löscht. Man kann davon ausgehen, dass der Handler
unter Umständen mehr Erweiterungen zurückgibt, als für die
Datei tatsächlich verwendet wurden.
Wird von handler.cc durch
delete_table und
ha_create_table() aufgerufen. Wird beim
Erzeugen einer Tabelle nur dann eingesetzt, wenn das
table_flag
HA_DROP_BEFORE_CREATE für die
Speicher-Engine angegeben wurde.
Parameter
name: Basisname der Tabelle
Rückgabewerte
0, wenn mindestens eine Datei vonbase_exterfolgreich gelöscht und keine anderen Fehler alsENOENTgemeldet wurden.#: Fehler
Verwendung
Die meisten Speicher-Engines brauchen diese Funktion nicht zu implementieren.
Zweck
Sorgt bei Transaktionen für das Sperren der Tabellen.
Zusammenfassung
virtual int external_lock
( | thd, | |
lock_type); |
| THD * | thd ; |
| int | lock_type ; |
Beschreibung
Dies ist die Methode external_lock.
Im Abschnitt „locking functions for mysql“ in
lock.cc finden Sie weitere lesenswerte
Hinweise zu diesem Thema.
Sperrt eine Tabelle. Wenn Sie eine Speicher-Engine
implementieren, die mit Transaktionen umgehen kann, schauen Sie
in ha_berkely.cc nach, wie Sie am besten
vorgehen. Ansonsten können Sie hier auch einen Aufruf von
flock() in Erwägung ziehen.
Wird von lock.cc durch
lock_external() und
unlock_external() sowie von
sql_table.cc durch
copy_data_between_tables() aufgerufen.
Parameter
thdlock_type
Rückgabewerte
Keine Rückgabewerte.
Standardimplementierung
{ return 0; }
Zweck
Übergibt Hinweise („Hints“) vom Server an die Speicher-Engine.
Zusammenfassung
virtual int extra
( | operation); |
| enum ha_extra_function | operation ; |
Beschreibung
Dies ist die Methode extra.
extra() wird aufgerufen, wenn der Server
einen Hinweis an die Speicher-Engine senden will. Die Engine
MyISAM implementiert die meisten Hinweise.
ha_innodb.cc enthält die vollständigste
Liste dieser Hinweise.
Parameter
operation
Rückgabewerte
Keine Rückgabewerte.
Verwendung
Die meisten Speicher-Engines geben einfach 0
zurück.
{ return 0; }
Standardimplementierung
Sie können Ihrer Speicher-Engine auch die Standardeinstellung geben, keinen dieser Hinweise zu implementieren.
{ return 0; }
Zweck
Zeigt das Ende eines Indexscans an und gibt die hierfür belegten Ressourcen frei.
Zusammenfassung
virtual int index_end
( | ); |
| ; |
Beschreibung
Dies ist die Methode index_end, die
normalerweise als Gegenstück zu index_init
verwendet wird und alle für den Indexscan verwendeten
Ressourcen wieder freigibt.
Parameter
Diese Funktion hat keine Parameter.
Rückgabewerte
Diese Funktion hat keine Rückgabewerte.
Verwendung
Gibt alle zugewiesenen Ressourcen frei und liefert 0 zurück.
Standardimplementierung
{ active_index=MAX_KEY; return 0; }
Zweck
Fragt die erste Zeile eines Indexes ab und gibt sie zurück.
Zusammenfassung
virtual int index_first
( | buf); |
| byte * | buf ; |
Beschreibung
Dies ist die Methode index_first.
index_first() fragt nach dem ersten
Schlüssel im Index.
Wird von opt_range.cc,
opt_sum.cc, sql_handler.cc
und sql_select.cc aufgerufen.
Parameter
buf- Ein Byte-Array, in welches die Zeile geladen wird.
Rückgabewerte
Keine Rückgabewerte.
Verwendung
Die Implementierung hängt von der verwendeten Indexmethode ab.
Standardimplementierung
{ return HA_ERR_WRONG_COMMAND; }
Zweck
Teilt der Speicher-Engine mit, dass ein Indexscan bevorsteht, damit diese die benötigten Ressourcen zuweist.
Zusammenfassung
virtual int index_init
( | idx, | |
sorted); |
| uint | idx ; |
| bool | sorted ; |
Beschreibung
Dies ist die Methode index_init. Diese
Funktion wird vor einem Indexscan aufgerufen, damit die
Speicher-Engine Gelegenheit hat, Ressourcen zuzuweisen und
Vorbereitungen zu treffen.
Parameter
idxsorted
Rückgabewerte
(nicht verfügbar)
Verwendung
Diese Funktion kann 0 zurückgeben, wenn keine Vorbereitung erforderlich ist.
Standardimplementierung
{ active_index=idx; return 0; }
Zweck
Gibt die letzte Zeile des Indexes zurück.
Zusammenfassung
virtual int index_last
( | buf); |
| byte * | buf ; |
Beschreibung
Dies ist die Methode index_last.
index_last() fragt nach dem letzten
Schlüssel im Index.
Wird von opt_range.cc,
opt_sum.cc, sql_handler.cc
und sql_select.cc aufgerufen.
Parameter
buf- Ein Byte-Array, in welches die zugehörige Zeile geladen wird.
Rückgabewerte
Diese Funktion hat keine Rückgabewerte.
Verwendung
Geht zur letzten Zeile im Index und lädt den zugehörigen Datensatz in den Puffer.
Standardimplementierung
{ return HA_ERR_WRONG_COMMAND; }
Zweck
Gibt die nächste Zeile im Index zurück.
Zusammenfassung
virtual int index_next
( | buf); |
| byte * | buf ; |
Beschreibung
Dies ist die Methode index_next.
Wird verwendet, um sich im Index nach vorne zu arbeiten.
Parameter
buf
Rückgabewerte
Diese Funktion hat keine Rückgabewerte.
Verwendung
Geht mithilfe eines Zeigers oder Cursors immer zum nächsten Index weiter und schreibt die zugehörige Zeile in den Puffer.
Standardimplementierung
{ return HA_ERR_WRONG_COMMAND; }
Zweck
Geht zur vorherigen Zeile im Index.
Zusammenfassung
virtual int index_prev
( | buf); |
| byte * | buf ; |
Beschreibung
Dies ist die Methode index_prev.
Wird verwendet, um sich rückwärts durch den Index zu arbeiten.
Parameter
buf
Rückgabewerte
Diese Funktion hat keine Rückgabewerte.
Verwendung
Geht zur vorigen Zeile im Index und schreibt diese in den Puffer.
Standardimplementierung
{ return HA_ERR_WRONG_COMMAND; }
Zweck
Sucht anhand eines Schlüssels eine Zeile und schreibt sie in den Puffer.
Zusammenfassung
virtual int index_read_idx
( | buf, | |
| index, | ||
| key, | ||
| key_len, | ||
find_flag); |
| byte * | buf ; |
| uint | index ; |
| const byte * | key ; |
| uint | key_len ; |
| enum ha_rkey_function | find_flag ; |
Beschreibung
Dies ist die Methode index_read_idx.
Setzt einen Indexcursor auf den im Schlüssel angegebenen Indexwert und holt, sofern vorhanden, die zugehörige Zeile ab. Wird nur verwendet, um ganze Schlüssel zu lesen.
Parameter
bufindexkeykey_lenfind_flag
Rückgabewerte
Diese Funktion hat keine Rückgabewerte.
Verwendung
Findet die zum Schlüssel gehörige Zeile und gibt sie in den bereitgestellten Puffer zurück.
Zweck
Sucht anhand eines Schlüssels eine Zeile und kehrt zurück.
Zusammenfassung
virtual int index_read
( | buf, | |
| key, | ||
| key_len, | ||
find_flag); |
| byte * | buf ; |
| const byte * | key ; |
| uint | key_len ; |
| enum ha_rkey_function | find_flag ; |
Beschreibung
Dies ist die Methode index_read.
Setzt einen Indexcursor auf den im Handle angegebenen Indexwert und holt, sofern vorhanden, die zugehörige Zeile ab. Ist der Schlüsselwert null, beginnt die Funktion beim ersten Schlüssel des Indexes.
Parameter
bufkeykey_lenfind_flag
Rückgabewerte
Diese Funktion hat keine Rückgabewerte.
Verwendung
(kein Beispiel verfügbar)
Standardimplementierung
{ return HA_ERR_WRONG_COMMAND; }
Zweck
Lässt die Speicher-Engine Statistikdaten ausgeben.
Zusammenfassung
virtual void info
( | uint); |
| uint ; |
Beschreibung
Dies ist die Methode info.
::info() gibt Informationen an den Optimierer
zurück. Zurzeit implementiert dieser Tabellen-Handler die
meisten erforderlichen Felder noch nicht. Auch
SHOW nutzt diese Daten. Ein weiterer Hinweis
ist der, dass Sie voraussichtlich Folgendes in Ihren Code
schreiben müssen: if (records < 2) records =
2;. Denn sonst führt der Server auch in Fällen, wo
nur ein einziger Datensatz vorhanden ist, Optimierungen durch.
Wenn Sie die Anzahl der Datensätze bei einem Tabellenscan nicht
kennen, sollten Sie records auf zwei
einstellen, damit Sie so viele Datensätze zurückgeben können,
wie Sie benötigen. Neben records gibt es
noch einige weitere Variablen einzustellen, nämlich:
deleted data_file_length,
index_file_length, delete_length
check_time. Weitere Informationen finden Sie unter den
öffentlichen Variablen in handler.h.
Wird in filesort.cc,
ha_heap.cc, item_sum.cc,
opt_sum.cc, sql_delete.cc,
sql_delete.cc,
sql_derived.cc,
sql_select.cc,
sql_select.cc,
sql_select.cc,
sql_select.cc,
sql_select.cc,
sql_show.cc,
sql_show.ccsql_show.cc,
sql_show.cc, sql_table.cc,
sql_union.cc und
sql_update.cc aufgerufen.
Parameter
uint
Rückgabewerte
Keine Rückgabewerte.
Verwendung
Dieses Beispiel stammt von der Speicher-Engine
CSV:
void ha_tina::info(uint flag)
{
DBUG_ENTER("ha_tina::info");
/* Ist zwar gelogen, aber der Optimierer soll keine mit null oder 1 Datensatz anfassen */
if (records < 2)
records= 2;
DBUG_VOID_RETURN;
}
Zweck
Öffnet eine Tabelle.
Zusammenfassung
virtual int open
( | name, | |
| mode, | ||
test_if_locked); |
| const char * | name ; |
| int | mode ; |
| uint | test_if_locked ; |
Beschreibung
Dies ist die Methode open.
Wird zum Öffnen von Tabellen verwendet. Der Name ist der Name der Datei. Eine Tabelle wird dann geöffnet, wenn es nötig ist, zum Beispiel, wenn eine SELECT-Anfrage für die Tabelle eintrifft. (Die Tabellen werden jedoch nicht für jede Anfrage geöffnet und geschlossen, sondern zwischenzeitlich im Cache gelagert.)
Wird von handler.cc durch
handler::ha_open() aufgerufen. Der Server
öffnet alle Tabellen mit einem Aufruf der Funktion
ha_open(), die dann die Handler-spezifische
open()-Funktion aufruft.
Ein Handler-Objekt wird im Rahmen seiner Initialisierung geöffnet, bevor es für normale Anfragen verwendet wird (nicht immer vor Metadatenänderungen.) Wenn das Objekt geöffnet wurde, wird es auch vor dem Löschen wieder geschlossen.
Dies ist die Methode open. Sie wird
aufgerufen, um eine Datenbanktabelle zu öffnen.
Der erste Parameter ist der Name der zu öffnenden Tabelle und
der zweite legt fest, welche Datei geöffnet oder welche
Operation ausgeführt werden soll. Die Werte sind in
handler.h definiert und werden hier für
Sie noch einmal aufgeführt:
#define HA_OPEN_KEYFILE 1 #define HA_OPEN_RNDFILE 2 #define HA_GET_INDEX 4 #define HA_GET_INFO 8 /* nach dem Öffnen ha_info() aufrufen */ #define HA_READ_ONLY 16 /* Datei schreibgeschützt öffnen */ #define HA_TRY_READ_ONLY 32 /* Wenn Schreibzugriff nicht möglich, schreibgeschützten versuchen */ #define HA_WAIT_IF_LOCKED 64 /* Bei vorhandener Sperre mit dem Öffnen warten */ #define HA_ABORT_IF_LOCKED 128 /* Bei vorhandener Sperre das Öffnen überspringen*/ #define HA_BLOCK_LOCK 256 /* Entsperren, wenn einige Datensätze gelesen werden */ #define HA_OPEN_TEMPORARY 512
Die letzte Option gibt an, ob der Handler auf Sperren auf der Tabelle achten soll, ehe er sie öffnet.
In der Regel wird Ihre Speicher-Engine auch irgendeine Form von
Zugriffskontrolle implementieren müssen, damit in einer
Multithread-Umgebung keine Dateien beschädigt werden. Ein
Beispiel für die Implementierung von Dateisperren finden Sie in
den Methoden get_share() und
free_share() von
sql/examples/ha_tina.cc.
Parameter
namemodetest_if_locked
Rückgabewerte
Keine Rückgabewerte.
Verwendung
Dieses Beispiel stammt von der Speicher-Engine
CSV:
int ha_tina::open(const char *name, int mode, uint test_if_locked)
{
DBUG_ENTER("ha_tina::open");
if (!(share= get_share(name, table)))
DBUG_RETURN(1);
thr_lock_data_init(&share->lock,&lock,NULL);
ref_length=sizeof(off_t);
DBUG_RETURN(0);
}
Zweck
Liefert dem MySQL Server die Position/den Offset der zuletzt gelesenen Zeile.
Zusammenfassung
virtual void position
( | record); |
| const byte * | record ; |
Beschreibung
Dies ist die Methode position.
position() wird nach jedem
rnd_next() aufgerufen, wenn die Daten
geordnet werden müssen. Um die Position zu speichern, können
Sie so etwas wie das Folgende tun: my_store_ptr(ref,
ref_length, current_position);
Der Server benutzt ref zum Speichern von
Daten. In den obigen Fällen ist ref_length
die Größe, die erforderlich ist, um die
current_position zu speichern.
ref ist nur ein Byte-Array, das vom Server
gepflegt wird. Wenn Sie Offsets verwenden, um Zeilen zu
kennzeichnen, dann sollte current_position
der Offset sein. Wenn ein Primärschlüssel verwendet wird, wie
in BDB, dann muss
current_position ein Primärschlüssel sein.
Wird aufgerufen von filesort.cc,
sql_select.cc,
sql_delete.cc und
sql_update.cc.
Parameter
record
Rückgabewerte
Diese Funktion hat keine Rückgabewerte.
Verwendung
Gibt für die letzte Zeile einen Offset oder einen Schlüssel für den Datenabruf zurück.
Zweck
Gibt eine Einschätzung, wie viele Datensätze in dem angegebenen Bereich liegen.
Zusammenfassung
virtual ha_rows records_in_range
( | inx, | |
| min_key, | ||
max_key); |
| uint | inx ; |
| key_range * | min_key ; |
| key_range * | max_key ; |
Beschreibung
Dies ist die Methode records_in_range.
Wenn Sie dieser Funktion einen Start- und einen End-Schlüssel
übergeben, schätzt sie ein, wie viele Zeilen zwischen diesen
beiden Schlüsseln liegen. end_key kann auch
leer sein; in diesem Fall wird ermittelt, ob
start_key irgendwelchen Zeilen entspricht.
Wird vom Optimierer genutzt, um den Aufwand zu ermitteln, den die Benutzung eines bestimmten Indexes verursachen würde.
Wird von opt_range.cc durch
check_quick_keys() aufgerufen.
Parameter
inxmin_keymax_key
Rückgabewerte
Gibt die ungefähre Anzahl der Zeilen zurück.
Verwendung
Ermittelt näherungsweise die Anzahl der Zeilen zwischen den beiden Schlüsselwerten und kehrt zurück.
Standardimplementierung
{ return (ha_rows) 10; }
Zweck
Initialisiert einen Handler für den Tabellenscan.
Zusammenfassung
virtual int rnd_init
( | scan); |
| bool | scan ; |
Beschreibung
Dies ist die Methode rnd_init.
rnd_init() wird aufgerufen, wenn das System
von der Speicher-Engine einen Tabellenscan verlangt.
Anders als index_init() kann
rnd_init() zweimal aufgerufen werden, ohne
dass zwischendurch rnd_end() erforderlich
ist (macht nur Sinn, wenn scan=1). Der zweite Aufruf sollte dann
den neuen Tabellenscan vorbereiten (wenn z. B.
rnd_init() den Cursor zuweist, sollte der
zweite Aufruf diesen an den Tabellenanfang setzen; so muss er
nicht erneut freigegeben und wieder zugewiesen werden).
Wird von filesort.cc,
records.cc,
sql_handler.cc,
sql_select.cc,
sql_table.cc und
sql_update.cc aufgerufen.
Parameter
scan
Rückgabewerte
Keine Rückgabewerte.
Verwendung
Dieses Beispiel stammt von der Speicher-Engine
CSV:
int ha_tina::rnd_init(bool scan)
{
DBUG_ENTER("ha_tina::rnd_init");
current_position= next_position= 0;
records= 0;
chain_ptr= chain;
DBUG_RETURN(0);
}
Zweck
Liest die nächste Zeile einer Tabelle und gibt sie an den Server zurück.
Zusammenfassung
virtual int rnd_next
( | buf); |
| byte * | buf ; |
Beschreibung
Dies ist die Methode rnd_next.
Diese Methode wird für jede Zeile des Tabellenscans aufgerufen.
Am Ende der Datensätze sollten Sie HA_ERR_END_OF_FILE
zurückgeben. Die Zeilendaten werden in den Puffer geladen. Die
Feldstruktur für die Tabelle ist der Schlüssel, um Daten so in
den Puffer zu schreiben, dass der Server sie verstehen kann.
Wird von filesort.cc,
records.cc,
sql_handler.cc,
sql_select.cc,
sql_table.cc und
sql_update.cc aufgerufen.
Parameter
buf
Rückgabewerte
Keine Rückgabewerte.
Verwendung
Dieses Beispiel stammt von der Speicher-Engine
ARCHIVE:
int ha_archive::rnd_next(byte *buf)
{
int rc;
DBUG_ENTER("ha_archive::rnd_next");
if (share->crashed)
DBUG_RETURN(HA_ERR_CRASHED_ON_USAGE);
if (!scan_rows)
DBUG_RETURN(HA_ERR_END_OF_FILE);
scan_rows--;
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count,
&LOCK_status);
current_position= gztell(archive);
rc= get_row(archive, buf);
if (rc != HA_ERR_END_OF_FILE)
records++;
DBUG_RETURN(rc);
}
Zweck
Gibt eine Zeile anhand ihrer Position zurück.
Zusammenfassung
virtual int rnd_pos
( | buf, | |
pos); |
| byte * | buf ; |
| byte * | pos ; |
Beschreibung
Dies ist die Methode rnd_pos.
Diese Methode findet Zeilen, die zuvor anhand ihrer Position gekennzeichnet wurden. Ist nützlich für große Sortieraufgaben.
Ähnlich wie rnd_next, liefert jedoch eine
Position zurück, um die Zeile zu ermitteln. Die Position hat
den in ref gespeicherten Typ. Mit
ha_get_ptr(pos,ref_length) können Sie den
Schlüssel oder den Positionswert abrufen, den Sie beim Aufruf
von position() gespeichert hatten. Wird von
filesort.cc, records.cc,
sql_insert.cc,
sql_select.cc und
sql_update.cc aufgerufen.
Parameter
bufpos
Rückgabewerte
Diese Funktion hat keine Rückgabewerte.
Verwendung
Findet die Zeile anhand eines Positionswerts und schreibt sie in den bereitgestellten Puffer.
Zweck
Wird zu Beginn einer Anweisung für Transaktionszwecke aufgerufen.
Zusammenfassung
virtual int start_stmt
( | thd, | |
lock_type); |
| THD * | thd ; |
| thr_lock_type | lock_type ; |
Beschreibung
Dies ist die Methode start_stmt.
Wenn eine Tabelle gesperrt wird, wird eine Anweisung gestartet,
indem start_stmt anstelle von
external_lock aufgerufen wird.
Parameter
thdlock_type
Rückgabewerte
Diese Funktion hat keine Rückgabewerte.
Verwendung
Falls nicht bereits eine Transaktion läuft, werden durch diese Funktion die Vorkehrungen für den Beginn einer Transaktion getroffen.
Standardimplementierung
{return 0;}
Zweck
Dient dem Errichten und Freigeben von Tabellensperren.
Zusammenfassung
virtual THR_LOCK_DATA **
store_lock
( | thd, | |
| to, | ||
lock_type); |
| THD * | thd ; |
| THR_LOCK_DATA ** | to ; |
| enum thr_lock_type | lock_type ; |
Beschreibung
Dies ist die Methode store_lock.
Der Methode handler::store_lock() liegt
folgende Idee zugrunde:
Die Anweisung entscheidet darüber, welche Sperren auf einer Tabelle erforderlich sind. Für Updates/Deletes/Inserts bekommen wir WRITE-Sperren und für SELECTs usw. Lesesperren.
Bevor die Sperre dem Tabellensperren-Handler übergeben wird,
ruft mysqld die Funktion
store_lock mit den erforderlichen Sperren
auf. Diese Funktion kann die Sperrebene modifizieren, etwa den
blockierenden Schreibmodus in einen nichtblockierenden
umwandeln, die Sperre ignorieren (wenn wir die
MySQL-Tabellensperren gar nicht einsetzen möchten) oder Sperren
für viele Tabellen hinzufügen (zum Beispiel bei Verwendung
eines MERGE-Handlers).
Berkeley DB stuft beispielsweise blockierende Tabellensperren vom Typ TL_WRITE zu nichtblockierenden TL_WRITE_ALLOW_WRITE-Sperren herab (ein Zeichen dafür, dass wir zwar Schreiboperationen vornehmen, aber dennoch andere Lese- und Schreibvorgänge zulassen).
store_lock() wird auch bei der Freigabe von
Sperren aufgerufen. In diesem Fall muss normalerweise nichts
weiter getan werden.
Wenn store_lock() das Argument
TL_IGNORE bekommt, so bedeutet dies, dass
MySQL den Handler dasselbe Ausmaß der Sperrung wie beim letzten
Mal speichern lässt.
Wird von lock.cc durch
get_lock_data() aufgerufen.
Parameter
thdtolock_type
Rückgabewerte
Keine Rückgabewerte.
Verwendung
Das folgende Beispiel stammt von der Speicher-Engine
ARCHIVE:
/*
Das folgende Beispiel zeigt die Einrichtung von Zeilensperren.
*/
THR_LOCK_DATA **ha_archive::store_lock(THD *thd,
THR_LOCK_DATA **to,
enum thr_lock_type lock_type)
{
if (lock_type == TL_WRITE_DELAYED)
delayed_insert= TRUE;
else
delayed_insert= FALSE;
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK)
{
/*
Hier kommen wir zum Kern der Zeilensperre.
Wenn TL_UNLOCK gesetzt ist
Wenn kein LOCK TABLE oder DISCARD/IMPORT
TABLESPACE erfolgt, dann sollen mehrere Schreib-Threads zulässig sein
*/
if ((lock_type >= TL_WRITE_CONCURRENT_INSERT &&
lock_type <= TL_WRITE) && !thd->in_lock_tables
&& !thd->tablespace_op)
lock_type = TL_WRITE_ALLOW_WRITE;
/*
In Anfragen wie INSERT INTO t1 SELECT ... FROM t2 ...
würde MySQL die Sperre TL_READ_NO_INSERT für t2 verwenden und dies
würde mit der Sperre TL_WRITE_ALLOW_WRITE in Konflikt treten, da alle Inserts
in t2 blockiert werden. Also konvertieren wir die Sperre in eine normale Lesesperre, um nebenläufige
Einfügungen in t2 zuzulassen.
*/
if (lock_type == TL_READ_NO_INSERT && !thd->in_lock_tables)
lock_type = TL_READ;
lock.type=lock_type;
}
*to++= &lock;
return to;
}
Im Folgenden sehen Sie die Minimalimplementierung für eine Speicher-Engine, die keine Sperren herabstufen muss:
THR_LOCK_DATA **ha_tina::store_lock(THD *thd,
THR_LOCK_DATA **to,
enum thr_lock_type lock_type)
{
/* Achtung: Wenn die Sperre den Typ TL_IGNORE hat, wird lock.type nicht aktualisiert,
sondern die vorherige Ebene beibehalten*/
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK)
lock.type=lock_type;
/* Das Herz der Methode store_lock() und ihr Daseinszweck:
das (möglicherweise geänderte) Ausmaß der Sperrung im zugewiesenen Speicher festzuhalten */
*to++= &lock;
return to;
}
Komplexere Implementierungen finden Sie unter
ha_berkeley::store_lock() und
ha_myisammrg::store_lock().
Zweck
Ändert den Inhalt einer vorhandenen Zeile.
Zusammenfassung
virtual int update_row
( | old_data, | |
new_data); |
| const byte * | old_data ; |
| byte * | new_data ; |
Beschreibung
Dies ist die Methode update_row.
old_data
speichert den alten und
new_data
den neuen Datensatz der Zeile.
Der Server kann Änderungen anhand einer Reihenfolge vornehmen,
wenn eine ORDER BY-Klausel verwendet wurde. Eine
aufeinander folgende Ordnung ist nicht garantiert.
Zurzeit kann
new_data
keine aktualisierten auto_increment- oder
timestamp-Felder aufnehmen. Dies können Sie
jedoch zum Beispiel folgendermaßen erreichen: if
(table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_UPDATE)
table->timestamp_field->set_time(); if (table->next_number_field
&& record == table->record[0])
update_auto_increment();.
Wird von sql_select.cc,
sql_acl.cc, sql_update.cc
und sql_insert.cc aufgerufen.
Parameter
old_datanew_data
Rückgabewerte
Keine Rückgabewerte.
Verwendung
(kein Beispiel verfügbar)
Standardimplementierung
{ return HA_ERR_WRONG_COMMAND; }
Zweck
Fügt einer Tabelle eine neue Zeile hinzu.
Zusammenfassung
virtual int write_row
( | buf); |
| byte * | buf ; |
Beschreibung
Dies ist die Methode write_row.
write_row() fügt eine Zeile ein.
Gegenwärtig wird bei Massenladeoperationen kein
extra()-Hinweis
gegeben.
buf
ist ein Byte-Array mit Daten und hat die Länge
table->s->reclength
Mithilfe der Feldinformationen können Sie die Daten aus dem nativen Byte-Array-Typ extrahieren, zum Beispiel wie in: for (Field **field=table->field ; *field ; field++) { ... }.
BLOBs erfordern eine Sonderbehandlung:
for (ptr= table->s->blob_field, end= ptr + table->s->blob_fields ; ptr != end ; ptr++)
{
char *data_ptr;
uint32 size= ((Field_blob*)table->field[*ptr])->get_length();
((Field_blob*)table->field[*ptr])->get_ptr(&data_ptr);
...
}
In ha_tina.cc wird gezeigt, wie alle Daten
als Strings extrahiert werden. In
ha_berkeley.cc finden Sie ein Beispiel, wie
die Daten intakt gespeichert werden, indem man sie für den
Berkeley-eigenen nativen Speichermechanismus "verpackt".
Siehe Hinweis zu update_row() über
auto_increments und
timestamps. Dieser Fall lässt sich auch auf
write_row() übertragen.
Wird von item_sum.cc,
item_sum.cc, sql_acl.cc,
sql_insert.cc,
sql_insert.cc,
sql_select.cc,
sql_table.cc, sql_udf.cc
und sql_update.cc verwendet.
Parameter
buf- Ein Byte-Array mit Daten
Rückgabewerte
Keine Rückgabewerte.
Verwendung
(kein Beispiel verfügbar)
Standardimplementierung
{ return HA_ERR_WRONG_COMMAND; }