Webentwickler müssen keine Netzwerkspezialisten sein. Doch Basiskenntnisse darüber, wie Anfragen im Internet vom anfragenden Rechner zum angefragten Rechner gelangen und welche Rolle dabei IP-Adressen und Domain-Namen spielen, sind unerlässlich. Dieser Abschnitt vermittelt das nötige Hintergrundwissen in lockerer Form, ohne dabei auf Details der Netzwerktechnik einzugehen.
Gehen wir von dem Szenario aus, dass ein Anwender in der Adresszeile seines Browsers eine Adresse eingibt:
www.example.org
Das ist zunächst einmal noch kein vollständiger URI. Es fehlen zumindest die Schemaangabe zum Protokoll sowie die gewünschte Pfadangabe zum verlangten Inhalt. Da ein Webbrowser per Default das HTTP-Protokoll verwendet und annimmt, dass die Startseite im Startverzeichnis des Webangebots verlangt wird, ist er so freundlich, die Adresse selbstständig in ein korrektes Standardformat zu bringen:
http://www.example.org/
http:// ist dabei das Schema für das HTTP-Protokoll und / am Ende ist der Pfadname des Web-Wurzelverzeichnisses.
Damit die aktuelle Version der verlangten Seite aufrufbar ist, muss eine Internetverbindung bestehen. Die Internetverbindung ist eine Verbindung zu einem »Einwahlknoten« eines Zugangsproviders. Dabei spielt es keine Rolle, um welche Art von Internetverbindung es sich handelt. Das Wort »Einwahlknoten« steht jedoch bewusst in Anführungszeichen. Eine Einwahl im engeren Sinne erfolgt nur dort, wo ein Modem am Werk ist, das nicht ständig online ist. Bei echten Standleitungen etwa gibt es keine Einwahl. Dennoch führt auch die Standleitung erst einmal zu einem Provider oder zumindest direkt zu einem so genannten Backbone-Provider. Von dort aus sorgt das Routing im Internet dafür, dass die Anfrage an ihr Ziel gelangt.
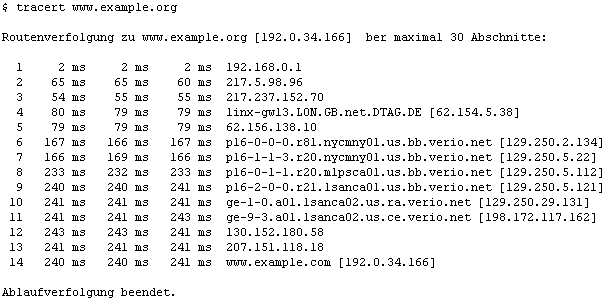
Betrachten wir, um den Vorgang besser zu verstehen, die Ausgabe des Kommandos tracert, welches auf praktisch allen internetfähigen Systemen verfügbar ist. Unter MS Windows können Sie es in einem DOS-Fenster oder unter einer Zusatz-Shell wie cygwin ausprobieren.
In diesem Beispiel wurde eingegeben:
tracert www.example.org
Hinter dem Kommandonamen tracert können Sie einen Domain-Namen oder eine IP-Adresse angeben.
Nachdem die Routenverfolgung abgeschlossen ist, listet das tracert-Kommando sein Ergebnis auf. In der letzten Spalte stehen die IP-Adressen und/oder Hostnamen der Stationen im Netz, welche die Anfrage an die Adresse passiert hat. In der ersten Spalte stehen die Laufnummern und dazwischen die Reaktionszeiten bei der Kommunikation zwischen den beteiligten Rechnern.
In unserm Beispiel verbirgt sich hinter der IP-Adresse in Laufnummer 1 ein Router, über den ein lokales Netzwerk (LAN) ans Internet angeschlossen ist. Im Beispiel wird die Internetverbindung letztlich über einen DSL-Anschluss realisiert, doch bei anderen Anschlussarten sieht der Netzzugang auch nicht anders aus. Falls sich ein Einzel-PC über Modem direkt beim Provider einwählt und kein LAN dazwischen ist, wird bei Laufnummer 1 die IP-Adresse des eingewählten PCs angezeigt. Diese wird heutzutage von den meisten Providern dynamisch bei jeder Einwahl neu zugewiesen, d.h., es kann bei jeder Einwahl eine andere IP-Adresse sein.
Die Adresse bei Laufnummer 2 gehört bereits zum Provider. Es handelt sich um den Rechner, den der Provider für die Internetverbindung als Einwahlrechner bereitgestellt hat. Im Beispiel passiert der Weg einen weiteren Rechner im gleichen Subnetz (217 an erster Stelle), bevor er in Laufnummer 4 den Gateway-Rechner erreicht, über den der Provider an den Backbone angeschlossen ist (auf die Begriffe Gateway und Backbone kommen wir später noch zu sprechen).
Der Ausgabe des tracert-Kommandos ist zu entnehmen, dass sich der mit www.example.org angefragte Rechner in den USA befindet. Die Adresse in Laufnummer 5 ist offensichtlich die letzte, die noch zum europäischen Backbone gehört. Danach passiert die Anfrage bereits diverse Gateway-Adressen des Backbone-Providers verio.net in den USA, bevor sie von dort schließlich ihren Zielrechner erreicht.
Auf dem Zielrechner erhält der Webserver die Anfrage des Browsers und sendet über das HTTP-Protokoll eine Antwort. Sofern erforderlich, werden anschließend die gewünschten Daten übertragen, etwa die Inhalte von HTML-Dateien sowie darin referenzierte Stylesheets, JavaScript-Dateien, Grafiken usw. Diese Daten müssen ebenfalls wieder über diverse Stationen geroutet werden, bis sie beim anfragenden Rechner bzw. beim dort auf Antwort wartenden Browser ankommen.