Das vollständige HTML-Dokument in der DOM-Ansicht
Die Regeln für syntaktisch korrektes HTML sind durchaus überschaubar. Um so wichtiger ist es aber auch, sie konsequent einzuhalten.
Im Fachjargon ist von HTML-Dokumenten die Rede. In der Praxis ist ein HTML-Dokument der HTML-Teil einer einzelnen Webseite. Webseiten bestehen darüber hinaus häufig aus CSS-Stylesheets, JavaScripts, sowie aus referenzierten Inhalten wie Grafiken, Flash-Movies usw. Wenn Sie Ihre Webseiten direkt in einem Texteditor bearbeiten und als statische HTML-Dateien speichern, dann ist ein HTML-Dokument einfach eine HTML-Datei.
HTML-Dokumente bestehen aus Text. Zur Textauszeichnung gibt es bestimmte Zeichen aus dem normalen Zeichenvorrat. Der Inhalt von HTML-Dokumenten steht in HTML-Elementen. HTML-Elemente werden durch sogenannte Tags markiert. Fast alle HTML-Elemente werden durch ein einleitendes und ein schließendes Tag markiert. Der Inhalt dazwischen ist der Gültigkeitsbereich des entsprechenden Elements. Tags werden in spitzen Klammern notiert. Ein Beispiel:
<h1>HTML – die Sprache des Web</h1>
Das Beispiel zeigt eine Überschrift 1. Ordnung. Das einleitende Tag <h1> signalisiert, dass eine Überschrift 1. Ordnung folgt (h = heading = Überschrift). Das abschließende Tag </h1> signalisiert das Ende der Überschrift. Ein abschließendes Tag beginnt mit einem Schrägstrich (/).
Bei HTML spielt es keine Rolle, ob die Elementnamen in den Tags in Klein- oder Großbuchstaben notiert werden. So bedeuten <h1> und <H1> das Gleiche. In XHTML müssen Elementnamen dagegen klein geschrieben werden.
Es gibt auch einige Elemente mit Standalone-Tags, d.h. Elemente, die keinen Inhalt haben und deshalb nur aus einem Tag bestehen statt aus Anfangs- und End-Tag. Ein Beispiel:
Eine Zeile, ein manueller Zeilenumbruch<br> und die nächste Zeile
Am Ende der ersten Zeile signalisiert <br>, dass ein manueller Zeilenumbruch eingefügt werden soll (br = break = Umbruch).
Wenn Sie XHTML-gerecht schreiben wollen, müssen Sie Elemente mit Standalone-Tags anders notieren: Anstelle von <br> müssen Sie <br /> notieren –- also den Elementnamen mit einem abschließenden Schrägstrich. Alternativ dazu können Sie auch <br></br> notieren, also ein Element mit Anfangs- und End-Tag, aber ohne Inhalt. In HTML 5 ist die XHTML-Notationsform ebenfalls erlaubt, d.h. dort können Sie sowohl <br> als auch <br /> notieren.
Elemente können ineinander verschachtelt werden. Auf diese Weise entsteht eine hierarchische Struktur. Komplexere HTML-Dokumente enthalten sehr viele und tiefe Verschachtelungen. Deshalb sprechen Fachleute auch von strukturiertem Markup. Ein Beispiel:
<h1><abbr>HTML</abbr> – die Sprache des Web</h1>
Das abbr-Element markiert eine Abkürzung. Die Grundregel beim Verschachteln von Elementen besteht darin, dass Elemente in der umgekehrten Reihenfolge geschlossen werden, in der sie geöffnet wurden. Das innerste Element wird also zuerst geschlossen, dann das äußere.
Eine Sequenz wie <p><span class="important">HTML CSS</p><p>PHP XML</span></p> ist nicht erlaubt.
Richtig wäre <p><span class="important">HTML CSS</span></p><p><span class="important">PHP XML</span></p>.
Einleitende Tags und Standalone-Tags können zusätzliche Angaben enthalten. lang="de" beispielsweise signalisiert dem interpretierenden Programm, dass der Elementinhalt deutschsprachig ist (lang = language = Sprache, de = deutsch):
<h1 lang="de">HTML – die Sprache des Web</h1>
Es gibt folgende Arten von Attributen in HTML-Elementen:
Alle Werte, die Sie Attributen zuweisen, sollten in hohen Anführungszeichen stehen. Die meisten Browser nehmen es zwar nicht übel, wenn die Anführungszeichen fehlen, und auch wenn sie im HTML5-Standard anders als bei HTML 4.0 nicht mehr zwingend vorgeschrieben sind, so ist doch dringend zu empfehlen, sie grundsätzlich zu verwenden. Gründe sind Rückwärtskompatibilität, Kompatibilität mit der XHTML-Syntax (dort sind sie zwingend vorgeschrieben), und bessere Code-Lesbarkeit.
Wie bei Elementnamen, so gilt auch bei Attributnamen: Bei HTML spielt es keine Rolle, ob die Attributnamen in Klein- oder Großbuchstaben notiert werden. In XHTML müssen Attributnamen dagegen klein geschrieben werden. Bei den Wertzuweisungen an Attribute kann Groß- und Kleinschreibung abhängig von der Art des Wertes unterschieden werden oder auch nicht.
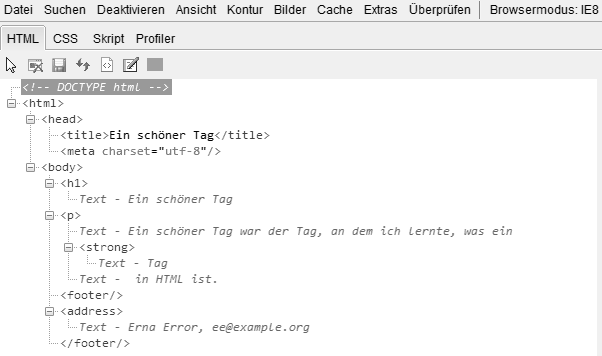
Zum besseren Verständnis des Gesamtzusammenhangs hier ein einfaches, vollständiges HTML-Dokument:
» Anzeigebeispiel: so sieht es aus
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Ein schöner Tag</title> </head> <body> <h1>Ein schöner Tag</h1> <p>Ein schöner Tag war der Tag, an dem ich lernte, was ein <strong>Tag</strong> in HTML ist.</p> <footer><address>Erna Error, ee@example.org</address></footer> </body> </html>
Auf das Grundgerüst von HTML-Dokumenten und die einzelnen Elemente gehen wir später ein. Wichtig ist zunächst, die Verschachtelungsstruktur von HTML zu verstehen. Das gesamte Dokument wird in das Tag-Paar <html> … </html> eingeschlossen. Die Kopfdaten sind von <head> … </head> umgeben, der im Browserfenster sichtbare Dokumentbereich von <body> … </body>. Innerhalb des body-Bereichs stehen ein h1-Element, ein p-Element und ein footer-Element auf gleicher Ebene. Das p-Element enthält neben Text auch ein strong-Element. Das footer-Element enthält ein address-Element.
Die im Dokument notierte Verschachtelungsstruktur wird, wenn das HTML-Dokument vom Browser verarbeitet wird, intern in einer Baumstruktur abgebildet. Die Baumstruktur eines HTML-Dokuments wird als dessen Document Object Model (DOM) bezeichnet. Durch entsprechende Visualisierungs-Tools wie den DOM-Inspector, eine Erweiterung für den Firefox-Browser, oder die Entwicklerwerkzeugansicht des MS Internet Explorer 8, lassen sich solche Baumstrukturen optisch darstellen:
Jeder Eintrag in dieser DOM-Baumstruktur wird als Knoten (englisch: node) bezeichnet.
Unter einem HTML-Parser versteht man eine Software, die HTML-Auszeichnungen erkennt und die darin ausgedrückte Baumstruktur in eine entsprechende Datenstruktur umsetzt, wie sie von Software benötigt wird. Jeder Web-Browser verfügt über einen HTML-Parser, um überhaupt mit HTML klarzukommen. Solche HTML-Parser werden nun leider auf den meisten Webseiten mit Syntaxfehlern in der Textauszeichnung konfrontiert. Oft sind es kleinere, nicht allzu tragische Fehler, doch es gibt auch viele Webseiten, deren HTML-Quelltext nur das Prädikat „ungenügend“ verdient, weil darin übelste Verunstaltungen der HTML-Regeln vorkommen. Strenge Parser, die genau gegen die HTML-Regeln prüfen, müssten die Umsetzung solcher Webseiten eigentlich abbrechen, und anstelle der Seite würden die Browser dann nur eine lapidare Fehlermeldung anzeigen. Da ein solcher Browser am breiten Markt jedoch keine Chance hätte, weil er kaum eine bekannte Webseite anzeigen würde, sind die HTML-Parser der heute verbreiteten Browser ziemlich gutmütige Wesen, die so ziemlich alles fressen, was ihnen vorgesetzt wird, und irgendetwas daraus machen, meistens sogar durchaus das, was der Autor der Webseite erreichen wollte.
Anders ist es, wenn XHTML, also die XML-basierte Variante von HTML, von einem XML-Parser verarbeitet wird. Solche Parser sind angehalten, die Verarbeitung im Fall von Syntaxfehler abzubrechen, ähnlich wie der Compiler einer Programmiersprache. Bislang wurden XHTML-Dokumente nur von den HTML-Parsern der Browser interpretiert. Mit HTML 5 / XHTML 5 ändert sich das. Wer XHTML 5 schreibt, schreibt Code für XML-Parser, nicht für HTML-Parser. Browser oder andere Web-Clients sollen XHTML 5 nur noch mit Hilfe eines XML-Parsers verarbeiten.
Korrekturen, Hinweise und Ergänzungen
Bitte scheut euch nicht und meldet, was auf dieser Seite sachlich falsch oder irreführend ist, was ergänzt werden sollte, was fehlt usw. Dazu bitte oben aus dem Menü Seite den Eintrag Diskutieren wählen. Es ist keine Anmeldung erforderlich, um Anmerkungen zu posten. Unpassende Postings, Spam usw. werden allerdings kommentarlos entfernt.